In database terminology primary key refers to the column in a table that's intended to be the primary way of identifying rows. Each table must have exactly one, and it needs to be unique. This is usually some kind of a unique identifier associated with objects presented by the table, or if such an identifier doesn't exist simply a running ID number (which is incremented automatically).
Hypermedia APIs¶
In the extra part of this exercise material we will dive into hypermedia APIs. This exercise moves away from the SensorHub example to the MusicMeta example which provides a better base for what we are about to discuss.
Full Example¶
Below is the full MusicMeta API example that we will be discussing in this section. Furthermore, if you haven't done so already, read through the API design extra material in order to understand what this API is trying to achieve.
Enter Hypermedia¶
In order for client developers to know what to actually send - and what to expect in return - APIs need to be documented. We achieved some of this goal by using OpenAPI to document the API, but we can further with
hypermedia
in responses given by the API. This way the API itself describes possible actions that can be taken to the client. For this example we have chosen Mason as our hypermedia format because it has a very clear syntax for defining hypermedia elements and connecting them to body. Hypermedia Controls and You¶
You can consider the API as a map and each
resource
as a node. The resource that you most recently sent a GET request to is basically the node that says "you are here". Hypermedia
controls
describe the logical next actions: where to go next, or actions that can be performed with the particular node you're in. Together with the resources they actually form a client-side state diagram of how to navigate the API. Hypermedia controls are extra attributes attached to the data representation
we showed in the API design example.A hypermedia control is a combination of at least two things:
link relation
("rel") and target URI
("href"). These answer two questions: what does this control do, and where to go to activate it. Note that link relation is a machine-readable keyword, not a description for humans. Many generally used relations are being standardized (full list) but APIs can define their own when needed as well - as long as each relation always means the same thing. When a client wants to do something, it uses the available link relations to discover what URI the next request should go to. This means that clients using our API should never need to have hardcoded URIs - they will find the URI by searching for the correct relation instead.Mason also defines some additional attributes for hypermedia controls. Of these "method" is one that we will be using frequently, because it tells which
HTTP method
should be used to make the request (usually omitted for GET as it is assumed to be the default). There's also "title" which can be used in generic clients
(or other generated clients) to help the client's human user figure out what the control does. Even beyond that we can also include JSON schema representation that defines how to send data to the API. In Mason hypermedia controls can be attached to any object by adding the
"@controls" attribute. This in itself is an object where link relations are attribute names whose values are also objects that have at least one attribute: href. For example, here is a track item with controls to get back to the album it is on ("up") and to edit its information ("edit"):{
"title": "Wings of Lead Over Dormant Seas",
"disc_number": 2,
"track_number": 1,
"length": "01:00:00",
"@controls": {
"up": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/"
},
"edit": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/2/1/",
"method": "PUT"
}
}
}
Or if we want each item in a collection to actually have its own URI available to clients:
{
"items": [
{
"artist": "Scandal",
"title": "Hello World",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Hello World/"
}
}
},
{
"artist": "Scandal",
"title": "Yellow",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Yellow/"
}
}
}
]
}
Custom Link Relations¶
While it's good to use standards as much as possible, realistically each API will have a number of
controls
whose meaning cannot be explicitly conveyed with any of the standardized relations
. For this reason Mason documents can use link relation namespaces
to extend available link relations. A Mason namespace defines a prefix and its associated namespace (similar to XML namespace, see CURIEs). The prefix will be added to link relations that are not defined in the IANA list. When a relation is prefixed with a namespace prefix, it is meant to be interpreted as attaching the relation at the end of the namespace and makes the relation unique - even if another API defined a relation with the same name, it would have a different namespace in front. For example if want to have a relation called "albums-va" to indicate a control that leads to a collection of all VA albums, its full identifier could be
http://wherever.this.server.is/musicmeta/link-relations/#albums-va. To make this look less wieldy we can define a namespace prefix called "mumeta", and then include this control like so:{
"@namespaces": {
"mumeta": {
"name": "http://wherever.this.server.is/musicmeta/link-relations/#"
}
},
"@controls": {
"mumeta:albums-va": {
"href": "/api/artists/VA/albums"
}
}
}
Also if a client developer visits the full URL, they should find a description about the link relation. Note also that this is normally expected to be a full URL because the server part is what guarantees uniqueness. In later examples you will see we're using a relative
URI
- this way the link to the relation description itself works even if the server is running in a different address (i.e. most likely localhost:someport). Information about the link relations must be stored somewhere. Note that this is intended for client developers i.e. humans. In our case a simple HTML document with anchors for each relation should be sufficient. This is why our namespace name ends with #. It makes it convenient to find each relation's description. Before moving on, here's the full list of custom link relations our API uses:
add-album, add-artist, add-track, albums-all, albums-by, albums-va, artists-all, delete.API Map¶
The last order of business in designing our API is to create a full map with all the
resources
and hypermedia
controls
visible. This a kind of a state diagram where resources are states and controls are transitions. Generally speaking only GET methods are used to moving from one state to another because other methods don't return a resource representation
. We have presented other methods as arrows that circle back to the same state. Here's the full map in all its glory. 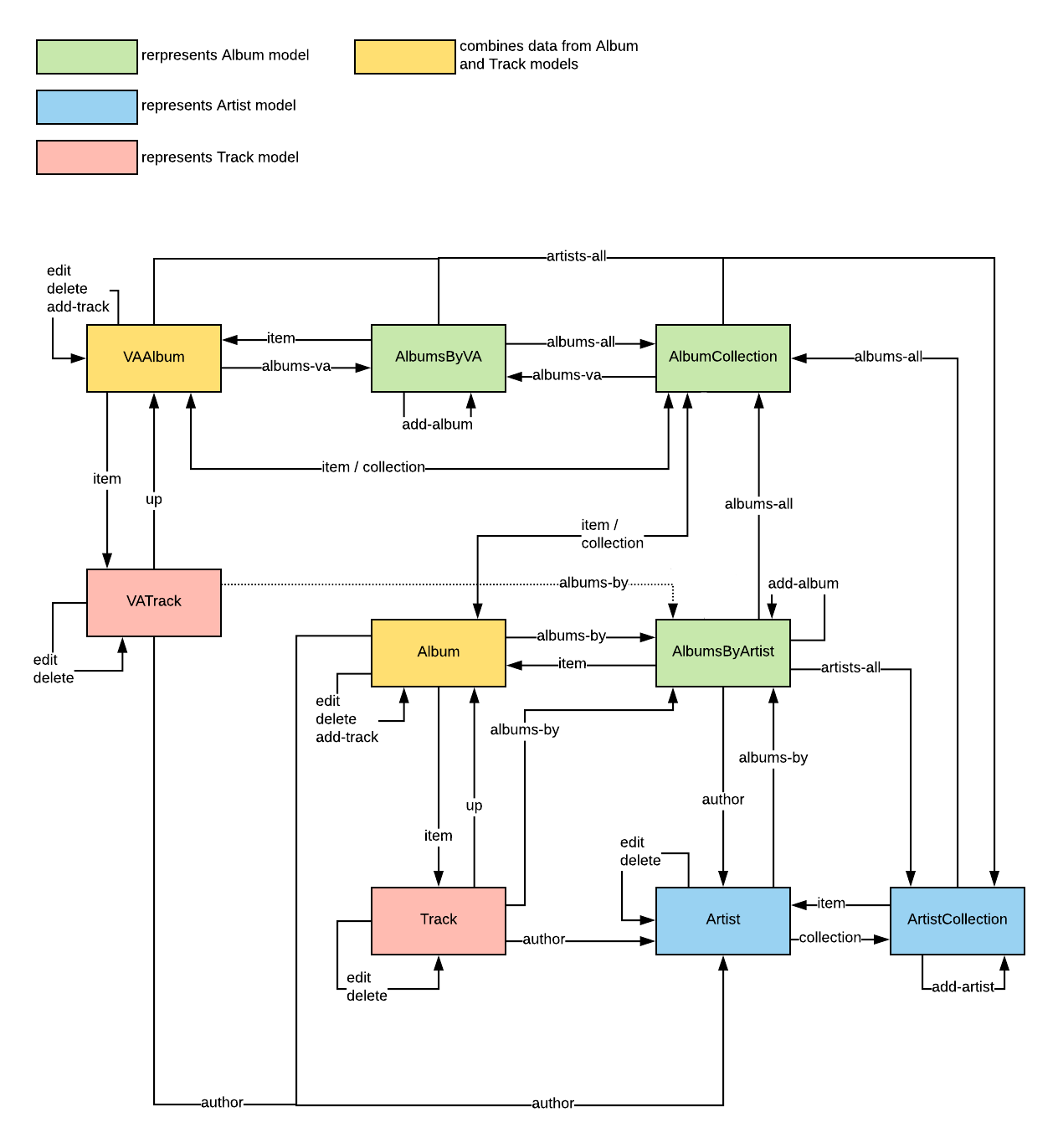
NOTE: The box color codes are only included for educational purposes to show you how data from the database is connected to resources - you don't need to share implementation details like this in real life, or your course project for that matter.
NOTE 2: the
link relation
"item" does not exist, this is actually "self". In this diagram "item" is used to indicate that this is a transition to an item from a collection through the item's "self" link.A map like this is useful when designing the API and should be done before designing individual representations returned by the API. As all actions are visible in a single diagram, it's easier to see if something is missing. When making the diagram keep in mind that there must be a path from every state to every other state (
connectedness
principle). In our case we have three separate branches in the URI
tree and therefore we have to make sure to include transitions between brances (e.g. AlbumCollection resource
has "artists-all" and "albums-va"). The Road to Transcendence¶
Consider the above state diagram. Let's assume you're a machine client. You are currently standing in the ArtistCollection node. The goal is to find and modify data about a various artists album titled "Transcendental" (collaboration of Mono and The Ocean). Which links have to be followed in order to do that? Does that path make sense to you?
For your answer, type the shortest list of link relations (use same names as in the diagram) that lead you from ArtistCollection to modifying the VA album's data.
 Anna palautetta
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Entry Point¶
A final note about mapping API is the
entry point
concept. This should be at the root of the API (in our case: /api/. It's kind of like the API's index page. It's not a resource
, and isn't generally returned to (which is why it isn't in the diagram). It just shows the reasonable starting options a client has when "entering" the API. In our case it should have controls
to GET either the artists collection or the albums collection (potentially also the VA album collection). Enter the Maze¶
Create a JSON document of the MusicMeta APIs entry point. It should contain two hypermedia controls: link to the artist collection, and link to the albums collection. You should be able to figure out the link relations of these controls from the state diagram. Don't forget to use the mumeta namespace!
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Advanced Controls with Schema¶
Up to now we have defined possible actions by using
hypermedia
. Each action comes with a link relation
that has an explicit meaning, address for the associated resource, and the HTTP method
to use. This information is sufficient for GET and DELETE requests, but not quite there for POST and PUT - we still don't know what to put in the request body
. Mason supports adding JSON Schema
to hypermedia controls. A schema object can be attached to a Mason hypermedia
control
by assigning it to the "schema" attribute. If the schema is particularly large or you have another reason to not include it in the response body, you can alternatively provide the schema from a URL on your API server (e.g. /schema/album/) and assign the URL to the "schemaUrl" attribute so that clients can retrieve it. The client can then use the schema to form a proper request when sending data to your API. Whether a machine client can figure out what to put into each attribute is a different story. One option is to use names that conform to a standard e.g. we could use the same attribute names as IDv2 tags in MP3 files. Schemas are particularly useful for (partially) generated clients that have human users. It's quite straightforward to write a piece of code that generates a form from a schema so that the human user can fill it. We'll show this in the last exercise of the course. Below is an example of a POST method control with schema:
{
"@controls": {
"mumeta:add-artist": {
"method": "POST",
"encoding": "json",
"title": "Add a new artist",
"schema": {
"type": "object",
"properties": {
"name": {
"description": "Artist name",
"type": "string"
},
"location": {
"description": "Artist's location",
"type": "string"
},
"formed": {
"description": "Formed",
"type": "string",
"format": "date"
},
"disbanded": {
"description": "Disbanded",
"type": "string",
"format": "date"
}
},
"required": [
"name",
"location"
]
}
}
}
}
Schemas can also be used for resources that use
query parameters
. In this case they will described the available parameters and values that are accepted. As an example we can add a query parameters that affects how the all albums collection is sorted. Here's the "mumeta:albums-all" control with the schema added. Note also the addition of "isHrefTemplate", and that "type": "object" is omitted from the schema.{
"@controls": {
"mumeta:albums-all": {
"href": "/api/albums/?{sortby}",
"title": "All albums",
"isHrefTemplate": true,
"schema": {
"properties": {
"sortby": {
"description": "Field to use for sorting",
"type": "string",
"default": "title",
"enum": ["artist", "title", "genre", "release"]
}
},
"required": []
}
}
}
}
Client Example¶
In order to give you some idea about why we're going through all this trouble and adding a bunch of bytes to our payloads, let's consider a small example from the client's perspective. Our client is a submission bot that browses its local music collection and sends metadata to the API for artists/albums that do not exist there yet. Let's say its local collection is grouped by artists, then albums. Let's say it's currently examining an artist folder ("Miaou") that contains one album folder ("All Around Us"). The goal is to see if this artist is in the collection, and whether it has this album.
- bot enters the api and finds the artist collection by looking for a hypermediacontrolnamed "mumeta:artists-all"
- bot sends a GET to the artist collection using the hypermedia control's href attribute
- bot looks for an artist named "Miaou" but doesn't find it
- bot looks for "mumeta:add-artist" hypermedia control
- bot compiles a POST request using the control's href attribute and the associated JSON schema
- after sending the POST request, the bot discovers the artist's address from the response's location header
- bot sends a GET to the address it received
- from the artist representation the bot looks for the "mumeta:albums-by" hypermedia control
- bot send a GET to the control's href attribute, receiving an empty album collection
- since the album is not there, bot looks for "mumeta:add-album" control
- bot compiles a POST request using the control's href attribute and the associated JSON schema
The important takeaway from this example is that the bot doesn't need to now any
URIs
besides /api/. For everything else it has been programmed to look for link relations
. All the addresses it visits are parsed from the responses it gets. They could be completely arbitrary and the bot would still work. Depending on the bot's AI it can survive quite drastical API changes (for example when it GETs the artist representation and finds a bunch of controls, how exactly has it been programmed to follow "mumeta:albums-by"?) One really cool thing about hypermedia APIs is that they usually have a generic client to browse any API if it's valid. The client will generate a human-usable web site by using hypermedia controls to provide links from one view to another, and schemas to generate forms.
Hypermedia Profiles¶
By adding
hypermedia
we have managed to create APIs that machine clients can navigate once they have been taught the meaning of each link relation
, and the meaning of each attribute in resource representations
. But how exactly does the machine learn these things? This is a ongoing challenge for API development - for now one way is to educate the human developers by using resource profiles
. Profiles describe the semantics of resources in human-readable format. This way human developers can transfer this knowledge to their client, or a human user of a client can use this knowledge when navigating the API.What's in a Profile?¶
There's no universal consensus about what exactly should be in a profile, or how to write one. Regardless of how it's written, the profile should have semantic descriptors for attributes (of the resource representation) and protocol semantics for actions that can be taken (or a list of link relations associated with the resource). Collections don't necessarily have their own profiles, like in our example they don't. Except for album since it is both an item and a collection.
If your resource represents something that is relatively common, using attributes defined in a standard (or standard proposal) is recommended. If your entire resource representation can conform to a standard, all the better. You can look for standards in https://schema.org/. One important future step for our example API would be to use attributes from this schema for albums and tracks.
Distributing Profiles¶
Like
link relations
, information about your profiles
should be accessible from somewhere. In our example we have chosen to distribute them as HTML pages from the server using routing
/profiles/{profile_name/. Links to profiles can be inserted as hypermedia
controls
using the "profile" link relation. For example, to link the track profile from a track representation
:{
"@controls": {
"profile": {
"href": "/profiles/track/"
}
}
}
Another possibility is to use HTTP Link
header
in responses. Link: <http://where.ever.the.server.is/profiles/track/>; rel="profile"
However this is somewhat more ambiguous. Our album
resource
is an example that actually should link to two profiles - album and track. For this reason we have included profiles as hypermedia controls, and for collection types we have included one with every item. Implementing Hypermedia¶
Hypermedia is essentially a bunch of JSON that is added to GET responses. At its core this is a rather simple matter of adding more content to the dictionaries we get from
serializing
model instances. As the Mason syntax is quite verbose, simply hardcoding these additions to response body dictionaries is a fast lane to trouble town. In this section we will discuss how to be a bit more systematic when adding hypermedia to responses.Subclass Solution¶
In Mason the root type of a hypermedia response is
JSON
object which - as we have learned - is in most ways the equivalent of a Python dictionary. However if you go and define the entire response as a dictionary in each resource method separately, the likelihood of introducing inconsistencies is quite high. Furthermore the code becomes cumbersome to maintain. For any applications that produce JSON, a good development pattern is to create a dictionary subclass that includes a number of convenience methods that automatically manage integrity of the selected JSON format. As stated before, our chosen hypermedia type for examples in this course is Mason. There are three special attributes in Mason JSON documents that we use commonly:
"@controls", "@namespaces" and "@error". Just to give you an idea of what we're trying to avoid, here's how we would need to make a Mason document with one namespace
and control
with normal dictionaries: body = artist.serialize()
body["@namespaces"] = {
"mumeta": {
"name": "/musicmeta/link-relations/#"
}
}
body["@controls"] = {
"mumeta:albums-by": {
"href": api.url_for(AlbumCollection, artist=artist)
}
}
Putting stuff like this - and usually in bigger numbers - is incredibly messy. What we want to achieve is, instead, something like this:
body = MasonBuilder(**artist.serialize())
body.add_namespace("mumeta", "/musicmeta/link-relations/#")
body.add_control("mumeta:albums-by", api.url_for(AlbumCollection, artist=artist))
Without doubt this looks much cleaner. The MasonBuilder class would take care of details about how exactly to add the namespace and control into the resulting document. If something about that changed, making the change in the class would also apply the change to all resource methods. So, how does this look on the class itself? Something like this:
class MasonBuilder(dict):
def add_namespace(self, ns, uri):
if "@namespaces" not in self:
self["@namespaces"] = {}
self["@namespaces"][ns] = {
"name": uri
}
def add_control(self, ctrl_name, href, **kwargs):
if "@controls" not in self:
self["@controls"] = {}
self["@controls"][ctrl_name] = kwargs
self["@controls"][ctrl_name]["href"] = href
Observe how
MasonBuilder extends the dict Python class, so the way of creating a MasonBuilder is exactly the same to create a dictionary using the dict class.Implementation detail: if you have not seen
**kwargs used before, this is a Python feature called packing/unpacking. It's a wildcard catch for keyword arguments given to the function/method when it's called: all such arguments will be packed into the kwargs dictionary. So when we call this method with method="POST" the kwargs will be end up like this: {"method": "POST"}. This feature is also used in the dict __init__ method (which we inherit), you can give it keyword arguments to initialize it with a bunch of keys.Because each object should have only one
"@controls" and "@namespaces" attributes, it makes sense to automatically create this when the first namespace/control is added. We can add a similar method for the "@error" attribute: def add_error(self, title, details):
self["@error"] = {
"@message": title,
"@messages": [details],
}
You can download the entire class with docstrings added from below. If you're using the more elaborate project structure, this class is something that definitely belongs into the
utils.py file and should be imported to other modules with from sensorhub.utils import MasonBuilder. The file below also incudes utility methods for adding PUT, POST, and DELETE controls.Since items in a colletion type
resource
can have their controls, you should construct them as MasonBuilder instances instead of dictionaries. This way you can add controls
to them just as effortlessly as you can to the root object. Let's take an example of how to add the very important "self" relation
to each sensor in the sensors collection resource representation
. body = MasonBuilder(items=[])
for artist in Artist.query.all():
item = MasonBuilder(artist.serialize(short_form=True))
item.add_control("self", api.url_for(Artist, artist=artist))
body["items"].append(item)
Note: instead of passing the serialize method's result to the MasonBuilder constructor like we do in this example, you can change the seriliaze method itself to initialize a MasonBuilder instance of a normal dictionary.
API Specific Subclasses¶
While the builder class we gave you goes quite a long way, making an API specific subclass can reduce the amount of boilerplate code in view methods a little bit more. For instance, to create a control for creating artist resources with POST, a function call like this is required:
body.add_control_post(
"mumeta:add-artist",
"Add a new artist",
api.url_for(ArtistCollection),
Artist.json_schema()
)
If you have to put multiple such method calls into your view methods, they get very bulky. It would probably be better if we could simply do:
body.add_control_add_artist()
This of course require that the gritty details of the add_control_post function call are hidden away somewhere else. A good way to hide these details is to subclass MasonBuilder, and put these convenience methods there.
class MusicMetaBuilder(MasonBuilder):
def add_control_add_artist(self):
self.add_control_post(
"mumeta:add-artist",
"Add a new artist",
api.url_for(ArtistCollection),
Artist.json_schema()
)
This case is very simple because the control has no variables at all. But we can also take an example with variables, like the PUT method control for tracks:
def add_control_edit_track(self, artist, album, disc, track):
self.add_control_put(
"Edit this track",
api.url_for(
TrackItem,
artist=artist,
album=album,
disc=disc,
track=track
),
Track.json_schema()
)
Now we can get a control for editing a track with a much simpler function call (all the variable values come from the view method's parameters).
body.add_control_edit_track(artist, album, disc, track)
With the gritty details carefully hidden away, the view method code will stay much more compact, making it much more easier to see what the view method actually does. For instance, an artist item has quite a few controls to it, but the view method code stays quite neat:
class ArtistItem(Resource):
def get(self, artist):
body = MusicMetaBuilder(artist.serialize())
body.add_namespace("mumeta", LINK_RELATIONS_URL)
body.add_control("self", href=request.path)
body.add_control("profile", href=ARTIST_PROFILE_URL)
body.add_control("collection", href=api.url_for(ArtistCollection))
body.add_control_albums_all()
body.add_control_albums_by(artist)
body.add_control_edit_artist(artist)
body.add_control_delete_artist(artist)
return Response(json.dumps(body), 200, mimetype=MASON)
Inventory Builder¶
In this task you're going to get a bit more familiar with dictionary subclasses by implementing one yourself. Picking up this habit will make future work on our inventory management API much leaner.
Learning goals: How to implement a dictionary subclass that maintains a Mason
hypermedia
document using convenience methods for adding controls
.Before you begin:
We have provided you a base file that contains the necessary resource classes, and the MasonBuilder class that was introduced above.
You need to complete your answer into this file for the checker to work. The checker is dynamic. It constructs a
JSON
document using your InventoryBuilder and then attempts to generate requests based on the controls in that JSON document against the resources in the base template. In order to be able to test your solution, run the following commands after setting the FLASK_APP environment variable:
flask init-db flask populate-db
You can also test your solution with another utility command
flask test-document
Product method: json_schema
You need to fill in the json_schema method in the Product model class in order to make the rest of the task work properly. It should return the schema for a valid product.
Class ProductConverter
Use the class from your solution to Inventory Converter.
Class: InventoryBuilder
For this task we want you to create a class that can be used to add hypermedia controls associated with the inventory manager's product resources. Your class should have a method the following methods for various
link relations
:add_control_all_products- paramaters: -
- rel:
"storage:products-all" - Leads to the list of all products (GET
/api/products/) add_control_delete_product- parameters: product model instance
- rel:
"storage:delete" - Deletes this product (DELETE
/api/products/{handle}/) add_control_add_product- paramaters: -
- rel:
"storage:add-product" - Creates a new product (POST
/api/products/) - schema required
- handle: string
- weight: number
- price: number
add_control_edit_product- parameters: product model instance
- rel:
"edit" - Edits a product (PUT
/api/products/{handle}/) - schema required (same as above)
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Responses and Errors¶
We briefly discussed Flask's
response object
in the Resource Locator task where we used it to set custom headers
. We have now arrived at a stage where we should actually be using it for all responses. This is largely because we need to announce the content type of our responses
, and this is done by using the mimetype keyword argument. Because we're using Mason, we need to set it to "application/vnd.mason+json". Since this will be repeated in every GET method, it'd be wise to make a constant of it (i.e. MASON = "application/vnd.mason+json"). From now on a typical 200 response would look like:return Response(json.dumps(body), 200, mimetype=MASON)
We went back to using json.dumps because Response takes the
response body
as a string. We can also change all 201 and 204 responses accordingly. We already learned how to do the 201 response with Location header, and a 204 response is even simpler: return Response(status=204)
We have now resolved issues regarding responses in the 200 range (i.e. successful operations). What about errors in the 400 range? Mason also defines what errors should look like. In fact, we actually already implemented the add_error method into our MasonBuilder dictionary subclass. However, even with that, returning an error becomes a multiline effort, and we don't really want that because most of it is boilerplate and resource methods typically return errors at multiple points of their execution. Let's make a convenience function for generating errors:
def create_error_response(status_code, title, message=None):
resource_url = request.path
body = MasonBuilder(resource_url=resource_url)
body.add_error(title, message)
body.add_control("profile", href=ERROR_PROFILE)
return Response(json.dumps(body), status_code, mimetype=MASON)
This generates a Mason error messages with a title, and one message with more description about the problem. It also puts the resource URL into the response body, just in case the client forgot what it was trying to do (sometimes actually relevant, e.g. asynchronous use cases). Now instead of writing all that whenever an error is encountered in a resource method, we can just write:
return create_error_response(404, "Not found", "No sensor was found with the given name")
Static Parts of Hypermedia¶
In addition to generating
hypermedia
representations for resources
, a fully functional hypermedia API should also serve some static content. Namely: link relations
and resource profiles
. Also if you have particularly large schemas and would rather serve them separately from resource representations
, these should also be served as static content. For profiles and link relations, you can send them out as static files. As Static Files¶
If your project doesn't have a static folder yet, now's the time to create one. It's also recommended to create some subfolders to keep things organized, e.g.
static ├── profiles └── schema
In order to use a static folder, it must be registered with Flask. This is done when initializing the app:
app = Flask(__name__, static_folder="static")
Static views are
routed
with @app.route. If you are storing profiles and such locally as html files, you can implement these views quite easily by using Flask's send_from_directory function which sends the contents of a file as the response body
- you should add it to your growing from flask import line. With profiles you can use one route definition and view function for all the profiles, like this:@app.route("/profiles/<resource>/")
def send_profile_html(resource):
return send_from_directory(app.static_folder, "{}.html".format(resource))
The
send_from_directory function is convenient enough that it will send a 404 response if the file is not found. Because link relation descriptions are not particularly lengthy they can be gathered into a single file, served in a similar manner:@app.route("/sensorhub/link-relations/")
def send_link_relations_html():
return send_from_directory(app.static_folder, "links-relations.html")
If you are using schema files, you can send them out in a similar manner. You will also need these URLs often in your code since almost all responses will include the
namespace
which requires the link relation URL, and likewise all resource representations have at least one profile link. Therefore you should probably at least introduce them as constants in your code, e.g.SENSOR_PROFILE = "/profiles/sensor/"
MEASUREMENT_PROFILE = "/profiles/measurement/"
LINK_RELATIONS_URL = "/sensorhub/link-relations/"
If you are using the more elaborate project structure, consider putting these into their own file, e.g.
constants.py. Documenting Hypermedia¶
So we documented our API with Swagger. Then we self-documented the API with hypermedia. Now the two are no longer in sync, so the final step is to update the OpenAPI documentation to match the new and improved hypermedia API we have built. Frankly there isn't much to do, just need to update the examples in all GET method responses.
Snatching Bodies with Requests¶
So basically what we want to have for, e.g. the documentation of the GET method for a single artist in our API, looks like this:
parameters:
- $ref: '#/components/parameters/artist/'
responses:
'200':
content:
application/vnd.mason+json:
example:
'@controls':
collection:
href: /api/artists/
edit:
encoding: json
href: /api/artists/scandal/
method: PUT
schema:
properties:
disbanded:
description: Disbanded
format: date
type: string
formed:
description: Formed
format: date
type: string
location:
description: Artist's location
type: string
name:
description: Artist name
type: string
required:
- name
- location
type: object
title: Edit this artist
mumeta:albums-all:
href: /api/albums/?sortby={sortby}
isHrefTemplate: true
schema:
properties:
sortby:
default: title
description: Field to use for sorting
enum:
- artist
- title
- genre
- release
type: string
required: []
type: object
title: All albums
mumeta:albums-by:
href: /api/artists/scandal/albums/
mumeta:delete:
href: /api/artists/scandal/
method: DELETE
title: Delete this artist
profile:
href: /profiles/artist/
self:
href: /api/artists/scandal/
'@namespaces':
mumeta:
name: /musicmeta/link-relations#
disbanded: null
formed: '2006-08-01'
location: Osaka, JP
name: Scandal
unique_name: scandal
'404':
description: The artist was not found
Now that's a handful. There is no way we are writing anything like this manually into the documentation files. Even if we replace the schemas with references, there's just too many things here that it's way too easy to forget something. Luckily, just like with schemas earlier, we can just pull the examples from our own code. Not quite as directly, but close enough.
Regardless of what your API is, the first step is to populate the database with enough data to have examples for everything. Then you can simply go through your routes with requests and use PyYaml to dump the responses into YAML format. Then you can just place the example into wherever you need it. Here's the basic way to do it:
import requests
import yaml
import os.path
SERVER_ADDR = "http://localhost:5000/api"
DOC_ROOT = "./doc/"
DOC_TEMPLATE = {
"responses": {
"200": {
"content": {
"application/vnd.mason+json": {
"example": {}
}
}
}
}
}
resp_json = requests.get(SERVER_ADDR + "/artists/scandal/").json()
DOC_TEMPLATE["responses"]["200"]["content"]["application/vnd.mason+json"]["example"] = resp_json
with open(os.path.join(DOC_ROOT, "artist/get.yml"), "w") as target:
target.write(yaml.dump(resp_json, default_flow_style=False))
A small note on folder naming in this example. The MusicMeta API defines endpoint names for resources because it uses the same resource class for multiple endpoints (to separate single artist and VA albums). So the doc folder naming is based on endpoint names instead of resource class names. Resource class name in lowercase is simply the default endpoint name assigned by Flask Restful if none is given.
After running this for all resources, you'd then simply add the remaining details like parameters and error codes. With this as a base operation you could quite easily build your own automation machinery that uses e.g. your API test database, and updates all examples in all documentation files. Or, now that you understand the basic process, you could look into libraries that provide this kind of automation.
Inventory Engineer Finale¶
We're almost one with our very minimal inventory management API that has served us well for majority of the server side implementation tasks. As your final exam on the topic, we want you to turn it into a hypermedia API that uses Mason. We will stick to managing products, inventory will be Someone Else's Problem.
Learning goals: how to add
hypermedia
to API responses.Before you begin:
Continue into the same file that was used in the previous task.
Entry Point
- Route:
"/api/"
You need to create an entry point that has one control:
"storage:products-all" which should point to the products collection. Remember namespace. This is best done as a normal view function
. Resource: ProductCollection
- Route:
"/api/products/" - Methods:
- GET - get list of all products (returns a Mason document)
- POST - creates a new product (should already be done)
GET: you should already have the basic code for this method. However, instead of returning an array, this method should now return an object, where the array of products is placed in the "items" property. You also need to add the following hypermedia controls to each item in the array:
"self"- points to the item"profile"- points to the product profile ("/profiles/product/")
The top level object itself should also have the following controls:
"self"- points to the collection itself"storage:add-product"- a control for adding products, see previous task
Don't forget to add the namespace. The document is returned as JSON, with the status code 200 and using
"application/vnd.mason+json" as the content type. POST: add validation using the product schema.
Resource: ProductItem
- Route:
"/api/products/<product:product>/" - Methods:
- GET - get information about the addressed product
- PUT - modify product information
- DELETE - delete the addressed product
GET: this method returns information about a product and controls related to it. It should use the product converter as shown in the given file. Add the following controls to response body, and change its media type to
"application/vnd.mason+json":"self"- points to the item"profile"- points to the product profile ("/profiles/product/")"collection"- points to the product collection"edit"- a control for editing product information, see previous task"storage:delete"- a control to delete the addressed product, see previous task
Finishing Touches
Finally you need to provide views for
link relations
and profiles
. These do not need to contain anything in particular as long as they exist and return plain text or HTML as strings. For this task only don't use static files or redirect.About the Checker
The checker initializes your database with some test data. After this it will run a script that acts like a hypermedia client, traversing your API from the entry point onward using link relations to find resources and actions. The testing is sequential: if your API fails to return a resource representation, all future cases will probably fail as well because the client script cannot find the hypermedia controls it's looking for.
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?