Tämä sivusto käyttää evästeitä. Sivusto käyttää ainoastaan evästeitä, jotka ovat välttämättömiä sen toiminnan kannalta, tai joita tarvitaan käyttäjän asetusten (kuten kieli) muistamiseen. Sivusto ei käytä seurantaevästeitä.Lue lisää käyttöehdoista.
In this final exercise we're visiting the other side of the API puzzle: the clients. We've been discussing the advantages
hypermedia
has for client developers for quite a bit. Now it's time to show how to actually implement these mythical clients. This exercise material goes through two examples: one fully automated machine client (Python script), and a browser client that generates a user interface for human users (Javascript with jQuery). We will show you how to make clients that are robust against API changes.
Because this exercise's number is even, we're using the MusicMeta API in this exercise. Jk, the real reason is that we're much more familiar with that API's hypermedia representations. We also envisioned some clients in exercise 2 so we have don't have the create a new idea from scratch.
Our first client is a submission script that manages its local MP3 files and compares their metadata against ones stored in the API. If local files have data that the API is missing, it automatically adds that data. If there's a conflict it just notifies a human user about it and asks their opinion - this is not an AI course after all.
Learning goals: Using Python's requests library to make
Another exercise, another Python module. We're using Requests for making API calls. Installation into your virtual environment as usual.
pip install requests
Just for the fun of it and showing off more API development tools, we're not going to give you the server code; instead we ask that you use the mockup server from Apiary to test the client. For this purpose we're giving you an update to the
API Blueprint
you filled at the end of exercise 2 - the tracks group documentation, which you can paste into your existing documentation. We also added the entry point as a resource so that it can be fetched by the client.
In order for this to work you need to combine it with the artist resources you defined in the last task of exercise 2.
musicmeta.md
You can find the address for your mockup server in the Inspector tab when viewing your Apiary document.
Do note that technically there's still errors in some of the example responses for 400 status codes because we've incorrectly split some strings to make the examples more readable (the ones with JSON validation errors produced by jsonschema). These don't matter for testing, but if you want everything to work fully you should remove the newlines. Finally, a note about the mockup server: it uses the Accept
header
of the request to determine which response it will send. This means it will send the first error response for PUT, POST and DELETE requests because the success responses do not have response body and therefore also don't have a content type. You can fix this in two ways:
use "application/vnd.mason+json" as the content type for the 201 and 204 responses even though there is no body, e.g. + Response 204 (application/vnd.mason+json)
either do not use the Accept header in testing, or add */* to the Accept header value (separate with comma).
Of course as the mockup only operates on the data that's included in its examples, your requests must match those examples to succeed. In particular you cannot test creating a new resource and then requesting that resource.
The basic use of Requests is quite simple and very similar to using Flask's test client. The biggest obvious difference is that now we're actually making a
HTTP request
. Like the test client, Requests also has a function for each
HTTP method
. These functions also take similar arguments: URL as a mandatory first argument, then keyword arguments like headers, params and data (for
headers
,
query parameters
and
request body
respectively). For example, to get artists collection (sub your own Apiary mockup URL to SERVER_URL):
Sending a POST request doesn't actually do anything to the mockup server, and regardless of what data you send, it will reply with the canned Location header. It does however suffice for testing the client:
You can view the requests you sent to the mockup server from the same Inspector tab where you found its address. Do note that it compares what you send to the examples, and will say (for both requests above) that they are incorrect (they're missing headers, and Apiary thinks all four artist fields are mandatory).
Some example requests sent while compiling this material
However as you can see from the console, these requests still got the responses we expected, so it's good enough for client testing. If you try to send the POST request to an actual API server with content type validation (which happens when the server tries to use request.json) you will get rejected. Setting the header is shown in the PUT example here:
We didn't show you how to send a DELETE request. As you might have guessed, this means we're going to ask you how to do it.
Learning goals: How to write a HTTP request using requests, a DELETE request in particular.
Assuming that the
host part
of the URL is stored in a constant called SERVER_URL, write a code line that deletes the album Hypnagogia by Evoken. Check the MusicMeta apiary documentation if you don't remember how.
Remember the artist name should be in lower case, while the album is in uppercase.
Vihjeet
Viestit
Often when making requests using
hypermedia
controls the client should use the method included in the
control
element. When doing this, using the request function is more convenient than using the method specific ones. Assuming we have the control as a dictionary called crtl:
Our intended client is expected to call the API a lot. Requests offers sessions which can help improve the performance of the client by reusing TCP connections. It can also set persistent
headers
which is helpful in sending the Accept header, as well as authentication tokens for APIs that use them. Sessions should be used as context managers using with statement to ensure that the session is closed.
With this setup, when using the session object to send
HTTP requests
, all the session headers are automatically included. Any headers defined in the request method call are added on top of the session headers (taking precedence in case of conflict). Note: if you want to avoid the issue with the mock server's response selection, you can use "application/vnd.mason+json, */*" as the Accept header value here as one way to do it.
The client code we're about to see makes some relatively sane assumptions about the API. First of all, it works with the assumption that
link relations
that are promised in the API
resource
state diagram are present in the representations sent by the API. Furthermore it trusts that the API will not send broken
hypermedia
controls
or
JSON schema
. It will also have issues if new mandatory fields are added for POST and PUT requests (but we'll make it easy to update in this regard).
We're not going to show the full code here, only the parts that actually interact with the API. Furthermore, while the client was tested with actual MP3 files, it might be easier for you to simply fake the tag data by creating a data class with necessary attributes, e.g. (only in Python 3.7. or newer)
In older Python versions you need to make a normal class and write the __init__ method yourself (data classes implement this kind of __init__ automatically).
The submission script works by going through the local collection with the following order of processing:
check first artist
check first album by first artist
check each track on first album
check second album by first artist
and so on, creating artists, albums and tracks as needed. It also compares data and submits differences. It trusts the local curator more than the API, always submitting the local side as the correct version. However when it doesn't have data for some field, it uses the API side value. Since MP3 files don't have metadata about artists, it uses "TBA" for the location field (because it is mandatory).
This way your client doesn't give two hoots even if the API changed its
URIs
arbitrarily on a daily basis, as long as the resource state diagram remains unchanged. Our submission script needs to start at the artist collection. However, instead of starting the script with a GET to /api/artists/, it should start digging at the entry point /api/ and find the correct URI for the collection it's looking for by looking at the "href" attribute of the "mumeta:artists-all"
control
.
With this in mind, this is how the client should start its interaction with the API:
withrequests.Session()ass:s.headers.update({"Accept":"application/vnd.mason+json"})resp=s.get(API_URL+"/api/")ifresp.status_code!=200:print("Unable to access API.")else:body=resp.json()artists_href=body["@controls"]["mumeta:artists-all"]["href"]
This is the only time the entry point is visited. From now on we'll be navigating with the link relations of
resource representations
(starting with the artist collection's representation). With the artist collection at hand, we can start to check artists from the local collection one by one.
We've chosen to fetch the artist collection anew for each artist, for the off chance that the artist we're checking is added by another client while we were processing the previous one. The first order of things is to go through the "items" attribute and look if the artist is there. Remembering the non-uniqueness issue with artist names, our script falls back to the human user to make a decision in the event of finding more than one artist with the same name. Doing comparisons in lowercase avoids capitalization inconsistencies.
Assuming we find the artist, we can now use the item's "self" link relation to proceed into the artist resource. This is only an intermediate step that is needed (according to the state diagram) in order to find the "mumeta:albums-by" control for this artist. This is the resource we need for checking the artist's albums. We have skipped exception handling because we trust the API to adhere to its own documentation (also for the sake of brevity).
Hypermedia can also be used for dumb things like making mazes that can be navigated using link relations. Solving one with an automated client is good exercise, so we decided to do some cheese hiding into a rather large maze...
Learning goals: Making a
hypermedia
client that chains together GET requests using
link relations
to find what it needs.
What to do
We have an API server running in https://pwpcourse.eu.pythonanywhere.com. Its media type is Mason. The server only has one resource, which only supports GET, and an entry point at /api/. The resource is a room, and it has two attributes:
"handle": string, the room's unique identifier
"content": string, possible values: "" and "cheese"
In addition it can have up to four directional controls which represent transitions from one room to another. Corner rooms only have two, rooms along the edge only have three. The controls belong to the maze namespace.
"maze:north": head towards the wall; you probably know nothing
"maze:south": head to warmer climates
"maze:east": go towards the sunrise
"maze:west": go west where the skies are blue
In addition the entry point has one control from the maze namespace: "maze:entrance" which leads to the first room.
Your quest is to find the cheese. The "maze" is just a square grid, but it has a lot of rooms. Unless you feel like clicking through thousands of links manually, using an automated machine client is recommended. When you find the cheese, remember to print out the room's handle - it's your answer to this task.
Your client needs some minimal intelligence so that it goes through the rooms in some logical order (e.g. one row at a time). Please make sure your client doesn't get stuck in infinite loops. Your client is sending actual network traffic - don't flood the API.
Vihjeet
Viestit
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
When something doesn't exist, the submission script needs to obviously send it to the API. We're skipping ahead a bit to creating albums and tracks. For both the data comes from MP3 tags (for albums we take the first track's tag as the source). The POST
request body
for both can also be composed in a similar manner thanks to
JSON schema
included in the
hypermedia
control. The basic idea is to go through properties in the schema and for each property:
find the corresponding local value (i.e. MP3 tag field)
convert the value into the correct format using the property's "type" and related fields (like "pattern" and "format" for strings)
add the value to the
message body
using the property name
In the event that a corresponding value is not found, the client can check whether that property is required. If it's not required, it can be safely skipped. Otherwise the client needs to figure out (or ask a human user) how to determine the correct value. We've chosen not to implement this part in the example though. It would be relevant only if the API added new attributes to its resources.
As a reminder of what it looks like, here's the "mumeta:add-album" control from the the albums collection
resource
:
"mumeta:add-album":{"href":"/api/artists/scandal/albums/","title":"Add a new album for this artist","encoding":"json","method":"POST","schema":{"type":"object","properties":{"title":{"description":"Album title","type":"string"},"release":{"description":"Release date","type":"string","pattern":"^[0-9]{4}-[01][0-9]-[0-3][0-9]$"},"genre":{"description":"Album's genre(s)","type":"string"},"discs":{"description":"Number of discs","type":"integer","default":1}},"required":["title","release"]}}
As it turns out, we only need one function for constructing POST requests for both albums and tracks:
In this function, tag is an object. In real use it's an instance of tinytag.TinyTag, but can also be instance of the class Tag we showed earlier. The ctrl parameter is a dictionary picked from the
resource's
controls
(e.g. "mumeta:add-album"). The mapping parameter is a dictionary with API side resource attribute names as keys and the corresponding MP3 tag fields as values. The knowledge of what goes where comes from reading the API's resource
profiles
. As an implementaion note, we're also using the getattr function which is how object's attributes can be accessed using strings in Python (as opposed to normally being accessed as e.g. tag.album).
The mapping dictionary for albums looks like this, where keys are API side names and values are names used in the tag objects.
Since all values are not stored in the same type or format as they are required to be in the request, the convert_value function (shown below) takes care of conversion:
Finally, notice how we have put submit_data as its own function? What's great about this function is that it works for all POST and PUT requests in the client. It looks like this:
Overall this solution is very dynamic. The client makes almost every decision using information it obtained from the API. The only thing we had to hardcode was the mapping of resource attribute names to MP3 tag field names. Everything else regarding how to construct the request is derived from the hypermedia control: what values to send; in what type/format; where to send the request and which HTTP method to use. Not only is this code resistant to changes in the API, it is also very reusable.
Of course if the control has "schemaUrl" instead of "schema", the additional step of obtaining the schema from the provided URL is needed, but is very simple to add.
When using dynamic code like the above example, editing a resource with PUT is a staggeringly similar act to creating a new one with POST. The bigger part of editing is actually figuring out if it's needed. Once again the core of this operation is the
schema
. One reason to use the schema instead of the
resource representation's
attributes is that the attributes can contain derived attributes that should not be submitted in a PUT request (e.g. album resource does have "artist" attribute, but the value cannot be changed).
In order to decide whether it should send a PUT request, the client needs to compare its local data against the data it obtained from the API regarding an album or a track. For comparisons to make sense, we need to once again figure out what are the corresponding local values, and convert them into the same type/format. This process is very similar to what we did in the create_with_mapping function above, and in fact most of its code can be copied into a new function called compare_with_mapping:
Overall this process looks very similar. There's just the added step of checking whether a field needs to be updated, and marking the change flag as True the first time a difference is discovered. Note also that for albums we're doing this comparison for the album resource, but for tracks we are actually doing it to track data that's in the album resource's "items" listing. This way we don't need to GET each individual track unless it needs to be updated. When this happens, we actually need to first GET the track and then find the edit
control
from there. This explains why we're not directly passing a control to this method, and also why finding the control at the end has the extra step if an edit control is not directly attached to the object we're comparing.
Fun fact: if at a later stage the API developer chooses to add the edit control to each track item in the album resource, this code would find that, making the extra step unnecessary. Sometimes clients can apply logic to find a control that's not immediately available. Following the self
link relation
of an item in a collection is a good guess about where to find additional controls related to that item.
A final reminder about PUT: remember that it must send the entire representation, not just the fields that have changed. The API should use the request body to replace the resource entirely. That is why we're always adding the API side value to fields when we don't have a new value for that field.
Generic hypermedia clients are built on the idea that it's possible to fully interact with an API by generating a user interface using information provided by hypermedia controls. One part of this is prompting values for POST and PUT requests from the user by generating a form or similar from either a template or schema provided by the API. In this task you will do a simple command line version of a generic data prompt function.
Learning goals: How to make prompts and convert data based on
JSON schema
, fetching a schema from a schema URL, submitting a POST/PUT request.
Before you begin:
You can use the submit_data function from the submission script example as-is. The only difference is that the checker in task will provide complete URLs as the "href" attribute in controls. Therefore you should either remove the API_URL constant or set it to "" before submitting your answer.
You should also download the latest version of the Sensorhub API and
run it
. This will help you in testing.
sensorhub.py
Function to implement:prompt_from_schema
Parameters:
requests session object - you must use this object to make any requests
Mason hypermedia control as a dictionary
The function should obtain the schema in one of two ways:
if the control has a "schema" attribute, use that schema
otherwise send a GET request to the URL specified in "schemaUrl" attribute and read the schema from the response with .json()
Once it has a schema, it should ask the user to input all required values (using description as the input prompt), and convert these into correct types as specified in the schema. The types used in this exercise are "number", "integer" and "string". String formats or patterns are not used. Once the function has compiled the request data, it should send it to the API server using attributes from the hypermedia control. You can use the submit_data function for this.
You do not need to implement typechecking for the user's inputs - the checker will only give you valid inputs. You do need to prompt inputs in the order they appear in the "required" list though (inputs from the checker are given in this order). Use the builtin input function for making these prompts.
Testing your program
You can test this program against any API that uses Mason as its
media type
, you just have to check whether the API uses full URLs or omits the
host part
. All of our examples omit it, which means you need to use the API_URL constant for the host part. Just remember to change it to an empty string before submitting your answer. Best way to do this is to set it to empty string at the beginning, and change its value to your test target in the main program portion of your module (as seen below).
Here's a main program that you can use to test against the Sensorhub API, to create a sensor.
This checker does not run an API server, but rather just uses objects that emulate just enough of the behavior of requests.Session and requests.Response to make it possible to check your function. They do not provide the full set of methods and attributes of these objects so try to stick to the basics shown in the examples (i.e. get, request, put and post for the Session and json and status_code for Response).
Vihjeet
Viestit
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Although this was a specific example, it should give you a good idea about how to approach client development in general when accessing a
hypermedia
API: minimize assumptions and allow the API
resource representations
to guide your client. When you need to hardcode logic, always base it on information from
profiles
. Always avoid working around the API - workarounds often rely on features that are not officially supported by the API, and may stop working at any time when the API is updated. Having a client that adjusts itself to the API is also respectful towards the API developer, making the job of maintaining the API much easier when there aren't clients out there relying on ancient/unintended features.
Here's the full example. If you want to run it without modifications, you need to actually have MP3 files with tag data that matches your Apiary documentation's examples. The submission script doesn't currently support VA albums.
In this section we're going through some considerations about making browser clients with Javascript and jQuery. A typical example of such a client is a graphical user interface to the API for human users. We're only commenting some implementation details of the code. If you need to learn Javascript basics, please refer to other sources (here are some). It's not a hard language to pick up if you already know Python, although it has a a lot of caveats. One of the principal components of browser side scripts is
DOM
manipulation. Because jQuery does DOM manipulation a lot better than Javascript by itself, and is therefore an almost unseparable component despite technically being an external library. In fact the example in this material is almost entirely written using jQuery.
Because Javascript is not expected to be as familiar as Python in our degree program, we're not jumping immediately into making as dynamic code as possible. Rather we'll show the basic actions without taking full advantage of
hypermedia
.
Learning goals: Learn the basics of implementing a browser-based API client for human users. Making
Ajax
-requests with jQuery. Manipulating DOM with jQuery.
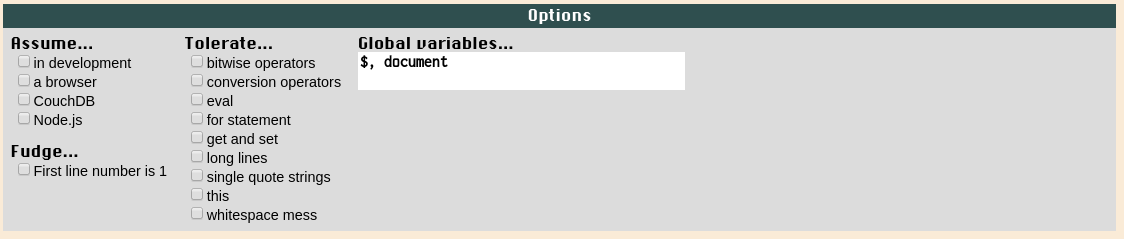
In our examples, we're following this style guide and expect you to do the same. We also encourage the use of JSLint. Javascript can be a devious language to debug as is - it's best to not make it any harder with poor code quality. When using JSLint for scripts that use jQuery, remember to add $ and document to the global variables box at the bottom to avoid a legion of "undeclared '$'" errors.
Globals look like this
It is also recommended to run Javascript in strict mode. This makes it raise more errors which makes overall debugging and maintenance easier. You can run a script in strict mode by including the following line at the beginning of your file:
For this example, we're going to serve the client from the same server application as the API itself. It's actually just one view that serves a static HTML page and a couple of script files (jQuery and our code) - maybe CSS if you're feeling designer-y - we're not. Serving everything from the same server also sidesteps the need for
cross origin resource sharing (CORS)
definition in the API side. In order to follow this example, download jQuery and create the following structure for your project's static folder:
static
├── css
├── html
├── profiles
└── scripts
Drop jquery.js into the scripts folder, and the following HTML file into the html folder. There's nothing particularly amazing about this HTML file, it just defines a couple of div elements where the client script will place elements as it receives
resource representations
from the API. You can also take this short CSS file to avoid 404 reports when loading the page. Also either name your own script file admin.js or change the reference in the HTML file appropriately.
admin.html
admin.css
Then put these lines into your single file application after resource
routing
, or inside the create_app function in __init__.py if you followed the more elaborate project strcuture guide.
After saving and starting your server, you should be able to visit /admin/ in localhost and see the rendered contents of the HTML file (which is not a whole lot).
In case you didn't already have it, here's the latest version of Sensorhub API single file version:
historically stood for Asynchronous Javascript And Xml and was spelled AJAX. Since then XML has been largely dropped, and presently Ajax is mostly used as a term rather than acronym. However, its asynchronous nature persists. Due to this nature, Ajax is non-blocking: after a request is sent with Ajax, the client side script will continue to run. Without this, browsing web pages that use Ajax would be plagued by constant freezing (and yes, constant, web pages these days do excessive amounts of Ajax calls). It also means, from the programming perspective, that your script cannot expect the response to be immediately available after making an Ajax request.
In the Python client above we always did blocking API calls - the script actually paused to wait for the response, and when it got one, it was stored into the resp variable. With non-blocking calls the response cannot be directly stored into a variable when making the call, because the response is not ready at the time. Instead, the code must register a
callback
that will handle the response when it's ready. In most cases at least one other callback with be registered for handling errors. All of this needs to be registered somehow. With jQuery, all of these are collected into an object that's given to the ajax fuction. The same in practice, for getting the entry point:
$ is a prefix that's used for all jQuery functions (and it's also a callable by itself, don't worry about it just now though). The $.ajax function takes a settings object as its argument. Here is a complete list or properties that can be included in this object. We're not going to use all of them. In the example we defined callbacks as
anonymous functions
. It's perfectly legal to assign existing functions instead:
Another thing that is entirely legal is to leave out function parameters if you don't need them, as long as the ones you don't need are at the end. E.g. we could leave jqxhr (jQuery XmlHttpRequest object) out because it's not used (you need it if you want to access headers). Javascript is dirty that way (and in many other ways). Also legal is to give $.ajax the url as the first argument, and rest of the settings as second argument (the joys of function overloading).
Regardless of how they are defined, one of these functions will be called once the server responds to our Ajax call. In case of success, the first parameter will get the
response body
as a compiled Javascript object. What usually happens after is some kind of
DOM
manipulation where data from the response is placed into the
DOM
for the user to see.
There is another way to register
callbacks
by using something called a Promise object. The code below has identical functionality:
For this exercise we're asking you to use the first method, i.e. pass the callbacks in the settings object. All the examples will also use it. As a practical reason, the current checkers cannot deal with the method that uses Promise object. They also do not support giving the URL in a separate argument - include it in the settings. In real life both approaches are equally valid. Promise objects are newer tech however, and introduce new options that are not possible with the old way. One such example is the ability to add multiple callbacks to the same event.
calls cleaner, the primary purpose of jQuery is to make
DOM
manipulation a lot cleaner. Document Object Model is a programming interface that allows Javascript to modify the contents of the document (i.e. web page) "on the fly" (i.e. without reloading the page). It presents the HTML as a tree structure where
elements
can be addressed either directly through their own attributes (e.g. class or id), or through relationships such as parent, children, next and previous. Basic selection with jQuery uses the same syntax as you would use with CSS when setting styles:
$("table")// selects all table elements$(".resulttable")// selects any elements where class="resulttable"$("#sensorlist")// selects the element where id="sensorlist"$(".resulttable tbody tr")// selects all rows from all tables where class="resulttable"
As you can see, jQuery itself can be called. This will return a query object which has methods that can be used to perform operations on all of the selected elements at once. Generally it's best to use id when attempting to select only one specific element, and class when selecting a group of related elements. Element types are usually used as seen in the last example, i.e. selecting all elements of one type within another selection. There's a wide variety of selectors to choose from but you can usually get pretty far with the basics.
Generally the best way to test selections and manipulation is to use your browser's Javascript console. In Chrome you can open it with Ctrl + Shift + j while in Firefox Ctrl + Shift + k gives a similar view (using j does also give a console but in a separate window). For testing the commands from now on you can use the HTML page served in your API server's "/admin/" URL.
Once you have a selection, there's another world of possibilities regarding how to manipulate it. One of the basic manipulation methods is html which can be used to set the HTML inside the selected element to whatever is in the argument (note: if arguments are not given this method becomes a getter and will return the HTML inside the element instead of setting it). Here's one way to set the contents of an error message area (HTML div element with the error class) in the UI:
Another simple common operation is to clear everything inside an element, such as clearing a table when we receive a different set of data to show. This is done with empty. Generally when manipulating tables, it's common to select the <tbody> element unless you want to change the table's headers. Here we're only clearing the data rows.
$(".resulttable tbody").empty();
Also regarding tables, the last very common thing we'll do is to append elements inside another element - usually a table, a form or a list (i.e. <ol> or <ul>). This is done with the append method.
Other things that are done commonly but not so much in this material are changing elements' attributes with attr or their appearance with css. These are related to things like hiding/showing and activating/deactivating elements in the UI, and obviously a lot more.
Ajax calls and how to insert data into the HTML page, we can look into some basic client operations. First is showing the items of a collection [!term=Resource!]resource
by putting them inside a table. But first let's do just the part the fills the data into the table.
For this purpose we need to make an Ajax call to "/api/sensors/" and fill the results into the HTML table inside the success
callback
. This is shown below using a named functions as handlers. The bit at the bottom is what calls this function once the HTML document has been completely loaded. Because doing the Ajax request itself is always the same, it's a good idea to make the function that renders the results into the HTML page a parameter:
For the first iteration of this client, we use a resource specific rendering function. This means the function is coded with knowledge of what the table headers are, and what columns are in the data. In this case it's also simplest to just construct the entire row's worth of HTML as a string and stuff it into the relevant part of the table, using html for the header (since we want to replace whatever was there) and append for the data. With these decision the implementation is quite simple, divided into two functions:
Showing data in the client is one thing - being able to submit is another. This will be done by using HTML forms that call a Javascript function instead of submitting directly to the server with POST. In the first iteration we will once again make resource specific functions which means form fields are hard-coded. We will still use the
schema
to mark which fields are mandatory, and retrieve the field descriptions.
Here we are using attr to set the various attributes of the form and the required attribute for mandatory input fields, We also use submit to set a function that will be called when the form is submitted (i.e. when the user presses the submit button). We're also using the syntax for selecting elements using arbitrary attributes ("element[attribute='value']"). All that's left is to implement the functions that actually send the data to the server. First let's talk about this one:
The most important line is at the very beginning. Calling event.preventDefault makes the browser skip the default behavior it would normally do with this event. In this case that would be to send the form contents as form encoded data to the address specified by the form element's action attribute. Our API doesn't take form encoded requests, so this would cause a 415 error. It's important to put this line in all functions that replace a default behavior. Another example is the anchor element which when clicked normally follows the associated URL - again something that we don't want because our entire client is built on the idea that we never leave the page. The sendData function has been generalized to work for all requests that have a request body:
argument. In the case of a POST request, the post-processing for successful addition would be to append the sensor's data into the sensor table. The options we have are:
use local data: read values from the form and put them into the table
refetch the sensor collection
fetch the new sensor using the location header and insert the data into the table
None of these are without problems. Local data is no good if resources have attributes that are generated by the API server, and local data does't have
controls
. Refetching the entire collection avoids any inconsistencies but is a rather heavy operation. The last option can also be problematic, especially if the sensor comes with bunch of data that we don't need for this view. It's still best in this scenario, so we will chain immediately into another
Ajax
call that uses the generic getResource from earlier, coupled with the function that appends the sensor into the table after the GET request.
Finally we're going to need navigational links to traverse between
resources
. For this example, we're only going to travel back and forth between the sensor collection and individual sensors. The first order of business is to enrich each sensor in the table with its "self"
link relation
, allowing us to get details about each. This necessitates a change to our sensorRow function:
The anchor tag definition looks a bit messy but it should be clear that we're getting the URL from the
control
. We're also hooking up the tag's onClick to a function that will override its normal behavior. Important difference to earlier: when setting an event handler with jQuery's method (e.g. submit), only the function's name is written; but when using HTML attributes, the entire function call is written. This function is quite simple:
Once again the most important thing is to prevent the default behavior. After this we'll handle the transition in our own way: by GETting the sensor's resource, and using a new rendering function to insert it into the
DOM
. When showing a resource that can be edited, a good way to do that is to put the data into a form. This way editing is really straightforward. Attributes that cannot be submitted this way can be put into read-only fields. Because we already have a fuction that renders a similar form for creating sensors, we can reuse it, and apply changes to the form afterward:
We're now using the before method to insert the location field (which is not in the
schema
) as a read-only field into the form before the submit button. Because the submission was made in a rather dynamic way, we can actually already edit the sensor. There will be an error in processing the results however, because the post-processing function tries to follow the Location header after submission. The header is not there though, because this is an edit. We could device a more elaborate way to deal with this, but for now let's just add a simple if statement to the function:
We should actually consider fetching the resource again or returning to the sensor collection. Why? Because changing the name of a sensor changes its
URI
. But instead of focusing too much on this, let's just finish this example by adding one navigational control to the navigation div: the "collection" link relation. This means adding another somewhat messy anchor tag by putting the following snippet somewhere inside renderSensor:
Pagination is often used with large datasets and something you have undoubtedly seen a lot in the web. It means that data is fetched in chunks of a certain size, and displayed along with controls like "next" (">") and "prev" ("<") (sometimes also "first" ("<<") and "last" (">>")). This is also used with APIs. In this exercise you will get to implement pagination for measurement data.
Learning goals: Fetching data from the API with pagination controls. Showing paginated data with
DOM
manipulation.
Before you begin:
We have made a final update to the Sensorhub API server. This update inlcudes the API side support for getting measurements with pagination, in chunks of 50. You can download it below.
app.py
Remember you need to create a database and populate with data. We have include some commands in the SensorHub API to simplify this tasks. They are explained in the Flask API project layout tutorial. If you just want to have it up and running execute the following commands:
flask init-db
flask testgen
flask run
Beyond that, you should continue where we left off with admin.js. Get the API running in port 5000, and point the browser to "http://localhost:5000/admin/". While developing, you will probably need more than a few reloads. Important: when you are testing in the browser, you must make a forced reload to the page - normal reload will keep the CSS and JS files cached and your changes won't take effect. Forced reload is performed with Shift + F5.
Do not touch any parts of the code that you haven't been instructed to.
Function to modify:renderSensor
You need to add an additional navigational control to the navigation div
element
. It should be added to the end (i.e. as second). Like others before it, this link will also call followLink when clicked, using the renderMeasurements function as its last argument. The href attribute for this link can be found from the "senhub:measurements-first" control.
New function:renderMeasurements
When the
Ajax
call returns, this function should have a measurement collection resource. This collection contains 50 measurements starting from the start index defined in
query string
(0 if omitted). Each measurement has two attributes:
time: a full ISO timestamp (string)
value: measurement value (float)
In addition the collection resource has the following controls:
"up": leads back to the sensor resource (irrelevant to this task)
"prev": retrieves the previous 50 measurements, only present if not already showing the first measurement
"next": retrieves the next 50 measurements, only present if not already showing the last measurement
Here's a list of things your function must do:
replace the tablecontrols div cotents with "prev" and "next" links if they are present in the resource representation
not the same div as navigation - check the HTML!
need to be shown in both top and bottom tablecontrol div elements!
"prev" should always be on the left
set the table headers to correspond with measurement attribute names (time on left)
display the 50 measurements in the table
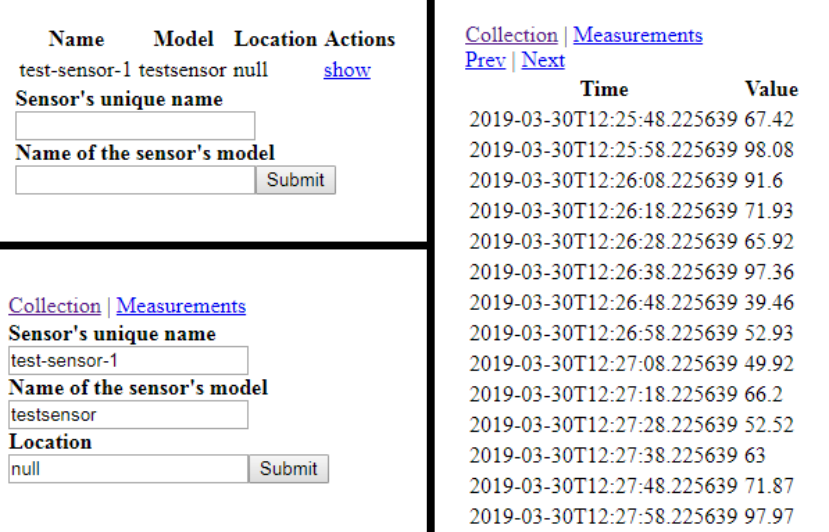
At the end your UI should have three different screens: one with the list of sensors, one with information about an specific sensor and one with the list of sensor's measurements. They are shown in the following image:
'Expected output
About the checker:
The checker is a rather interesting monstrosity that uses NodeJS and JSDOM and some bonus hacking to make your code think it's running in a browser, and that the user is clicking links. It does not use the checker architecture used by all the other checkers (due to lack of JS support), making it less resistant to errors. If your code produces any errors, the checker will crash (or at least Lovelace will think so) - test your code properly before sending. The same will happen if your code does any console logging - remember to comment out any console.log lines.
NOTE: The checker does not work if you have "use strict"; in the file. Please comment the line out before submitting.
Vihjeet
Viestit
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Anna palautetta
Kommentteja materiaalista?
?
API Blueprint is a description language for REST APIs. Its primary categories are resources and their related actions (i.e. HTTP methods). It uses a relatively simple syntax. The advantage of using API Blueprint is the wide array of tools available. For example Apiary has a lot of features (interactive documentation, mockup server, test generation etc.) that can be utilized if the API is described in API Blueprint.
Another widely used alteranative for API Blueprint is OpenAPI.
Addressability is one of the key REST principles. It means that in an API everything should be presented as resources with URIs so that every possible action can be given an address. On the flipside this also means that every single address should always result in the same resource being accessed, with the same parameters. From the perspective of addressability, query parameters are part of the address.
Ajax is a common web technique. It used to be known as AJAX, an acronym for Asynchronous Javascript And XML but with JSON largely replacing XML, it become just Ajax. Ajax is used in web pages to make requests to the server without a page reload being triggered. These requests are asynchronous - the page script doesn't stop to wait for the response. Instead a callback is set to handle the response when it is received. Ajax can be used to make a request with any HTTP method.
Kuvaus
Examples
Anonymous functions are usually used as in-place functions to define a callback. They are named such because they are defined just like functions, but don't have a name. In JavaScript function definition returns the function as an object so that it can e.g. passed as an argument to another function. Generally they are used as one-off callbacks when it makes the code more readable to have the function defined where the callback is needed rather than somewhere else. A typical example is the forEach method of arrays. It takes a callback as its arguments and calls that function for each of its members. One downside of anonymous functions is that they function is defined anew every time, and this can cause significant overhead if performed constantly.
Anonymous functions are also often seen in Ajax calls:
In this case the functions are stored into the settings object as callable attributes. When they are called, the code contained within the function is executed.
Kuvaus
Example
In Flask application context (app context for short) is an object that keeps tracks of application level data, e.g. configuration. You always need to have it when trying to manipulate the database etc. View functions will automatically have app context included, but if you want to manipulate the database or test functions from the interactive Python console, you need to obtain app context using a with statement.
Obtaining app context in the console from module app.py (where the application is contained within the app variable):
In[1]:fromappimportappIn[2]:withapp.app_context():...:#do things
Blueprint is a Flask feature, a way of grouping different parts of the web application in such a way that each part is registered as a blueprint with its own root URI. Typical example could be an admin blueprint for admin-related features, using the root URI /admin/. Inside a blueprint, are routes are defined relatively to this root, i.e. the route /users/ inside the admin blueprint would have the full route of /admin/users/.
Defines how data is processed in the application
Cross Origin Resource Sharing (CORS) is a relaxation mechanism for Same Origin Policy (SOP). Through CORS headers, servers can allow requests from external origins, what can be requested, and what headers can be included in those requests. If a server doesn't provide CORS headers, browsers will browsers will apply the SOP and refuse to make requests unless the origin is the same. Note that the primary purpose of CORS is to allow only certain trusted origins. Example scenario: a site with dubious script cannot just steal a user's API credentials from another site's cookies and make requests using them because the APIs CORS configuration doesn't allow requests from the site's origin. NOTE: this is not a mechanism to protect your API, it's to protect browser users from accessing your API unintentionally.
Callback is a function that is passed to another part of the program, usually as an argument, to be called when certain conditions are met. For instance in making Ajax requests, it's typical to register a callback for at least success and error situations. A typical feature of callbacks is that the function cannot decide its own parameters, and must instead make do with the arguments given by the part of the program that calls it. Callbacks are also called handlers. One-off callbacks are often defined as anonymous functions.
Piece of software that consumes or utilizes the functionality of a Web API. Some clients are controlled by humans, while others (e.g. crawlers, monitors, scripts, agents) have different degree of autonomy.
In databases, columns define the attributes of objects stored in a table. A column has a type, and can have additional properties such as being unique. If a row doesn't conform with the column types and other restrictions, it cannot be inserted into the table.
Kuvaus
Common keywords
In object relational mapping, column attributes are attributes in model classes that have been initialized as columns (e.g. in SQLAlchemy their initial value is obtained by initializing a Column). Each of these attributes corresponds to a column in the database table (that corresponds with the model class). A column attribute defines the column's type as well as additional properties (e.g. primary key).
These are the most commonly used keyword attributes to SQLALchemy's Column:
default - the default value that is used when no value for the column is provided (must match column type)
nullable - does the column accept NULL as value (i.e. no value) (boolean)
primary_key - marks this column as the PK (boolean)
unique - all values in the column must be unique (boolean)
Connectedness is a REST principle particularly related to hypermedia APIs. It states that there for each resource in the API, there must exist a path from every other resource to get there by following hypermedia links. Connectedness is easiest to analyze by creating an API state diagram.
Kuvaus
Example
A hypermedia control is an attribute in a resource representation that describes a possible action to the client. It can be a link to follow, or an action that manipulates the resource in some way. Regardless of the used hypermedia format, controls include at least the URI to use when performing the action. In Mason controls also include the HTTP method to use (if it's not GET), and can also include a schema that describes what's considered valid for the request body.
In Mason controls are attached to the "@controls" attribute which can be part of the top-level resource, or part of an item in an array. Here's the delete control for an artist resource in the MusicMeta API example:
{"@controls":{"mumeta:delete":{"href":"/api/artists/dream theater/""title":"Delete this artist""method":"DELETE"}}}
Document Object Model (DOM) is an interface through which Javascript code can interact with the HTML document. It's a tree structure that follows the HTML's hierarchy, and each HTML tag has its own node. Through DOM manipulation, Javascript code can insert new HTML into anywhere, modify its contents or remove it. Any modifications to the DOM are updated into the web page in real time. Do note that since this is a rendering operation, it's very likely one of the most costly operations your code can do. Therefore changing the entire contents of an element at once is better than changing it e.g. one line at a time.
Database schema is the "blueprint" of the database. It defines what tables are contained in the database, and what columns are in each table, and what additional attributes they have. A database's schema can be dumped into an SQL file, and a database can also be created from a schema file. When using object relational mapping (ORM), the schema is constructed from model classes.
In HTML element refers to a single tag - most of the time including a closing tag and everything in between. The element's properties are defined by the tag, and any of the properties can be used to select that element from the document object model (DOM). Elements can contain other elements, which forms the HTML document's hierarchy.
For APIs entry point is the "landing page" of the API. It's typically in the API root of the URL hierarchy and contains logical first steps for a client to take when interacting with the API. This means it typically has one or more hypermedia controls which usually point to relevant collections in the API or search functions.
In software testing, a fixture is a component that satisfies the preconditions required by tests. In web application testing the most common role for fixtures is to initialize the database into a state that makes testing possible. This generally involves creating a fresh database, and possibly populating it with some data. In this course fixtures are implemented using pytest's fixture architecture.
This term contains basic instructions about setting up and running Flask applications. See the term tabs "Creating DB" and "Starting the App". For all instructions to work you need to be in the folder that contains your app.
Before the first run you need to create the database:
your/app/folder$ ipython
[1]: from yourapp import db
[2]: db.create_all()
In Linux:
your/app/folder$ export FLASK_APP=yourapp.py
your/app/folder$ export FLASK_ENV=development
flask run
In Windows:
C:\your\app\folder> set FLASK_APP=yourapp.py
C:\your\app\folder> set FLASK_ENV=development
flask run
In database terminology, foreign key means a column that has its value range determined by the values of a column in another table. They are used to create relationships between tables. The foreign key column in the target table must be unique.
For most hypermedia types, there exists a generic client. This is a client program that constructs a navigatable user interface based on hypermedia controls in the API, and can usually also generate data input forms. The ability to use such clients for testing and prototyping is one of the big advantages of hypermedia.
HTTP method is the "type" of an HTTP request, indicating what kind of an action the sender is intending to do. In web applications by far the most common method is GET which is used for retrieving data (i.e. HTML pages) from the server. The other method used in web applications is POST, used in submitting forms. However, in REST API use cases, PUT and DELETE methods are also commonly used to modify and delete data.
HTTP request is the entirety of the requets made by a client to a server using the HTTP protocol. It includes the request URL, request method (GET, POST etc.), headers and request body. In Python web frameworks the HTTP request is typically turned into a request object.
Headers are additional information fields included in HTTP requests and responses. Typical examples of headers are content-type and content-length which inform the receiver how the content should be interpreted, and how long it should be. In Flask headers are contained in the request.headers attribute that works like a dictionary.
Host part is the part of URL that indicates the server's address. For example, lovelace.oulu.fi is the host part. This part determines where (i.e. which IP address) in the world wide web the request is sent.
In API terminology hypermedia means additional information that is added on top of raw data in resource representations. It's derived from hypertext - the stuff that makes the world wide web tick. The purpose of the added hypermedia is to inform the client about actions that are available in relation to the resource they requested. When this information is conveyed in the representations sent by the API, the client doesn't need to know how to perform these actions beforehand - it only needs to parse them from the response.
An idempotent operation is an operation that, if applied multiple times with the same parameters, always has the same result regardless of how many times it's applied. If used properly, PUT is an idempotent operation: no matter how many times you replace the contents of a resource it will have the same contents as it would have if only one request had been made. On the other hand POST is usually not idempotent because it attempts to create a new resource with every request.
Instance folder is a Flask feature. It is intended for storing files that are needed when running the Flask application, but should not be in the project's code repository. Primary example of this is the prodcution configuration file which differs from installation to installation, and generally should remain unchanged when the application code is updated from the repository. The instance path can be found from the application context: app.instance_path. Flask has a reasonable default for it, but it can also be set manually when calling Flask constuctor by adding the instance_path keyword argument. The path should be written as absolute in this case.
Kuvaus
Serializing / Parsing
JavaScript Object Notation (JSON) is a popular document format in web development. It's a serialized representation of a data structure. Although the representation syntax originates from JavaScript, It's almost identical to Python dictionaries and lists in formatting and structure. A JSON document conists of key-value pairs (similar to Python dictionaries) and arrays (similar to Python lists). It's often used in APIs, and also in AJAX calls on web sites.
JSON is extremely simple to write and read in Python using the json module.
JSON schema is a JSON document that defines the validity criteria for JSON documents that fall under the schema. It defines the type of the root object, and types as well as additional constraints for attributes, and which attributes are required. JSON schemas serve two purposes in this course: clients can use them to generate requests to create/modify resources, and they can also be used on the API end to validate incoming requests.
In hypertext and hypermedia context, link relation is a semantic "tag" that indicates the link's purpose. Machine clients can use link relations to determine what to do with a link or how to present it to a human user. Link relations should always have explicitly defined meaning, and the use of standardized link relations is recommended wherever possible. APIs must provide definitions for all custom link relations they use.
MIME type is a standard used for indicating the type of a document.In web development context it is placed in the Content-Type header. Browsers and servers the MIME type to determine how to process the request/response content. On this course the MIME type is in most cases application/json.
Database migration is a process where an existing database is updated with a new database schema. This is done in a way that does not lose data. Some changes can be migrated automatically. These include creation of new tables, removal of columns and adding nullable columns. Other changes often require a migration script that does the change in multiple steps so that old data can be transformed to fit the new schema. E.g. adding a non-nullable column usually involves adding it first as nullable, then using a piece of code to determine values for each row, and finally setting the column to non-nullable.
In ORM terminology, a model class is a program level class that represents a database table. Instances of the class represent rows in the table. Creation and modification operations are performed using the class and instances. Model classes typically share a common parent (e.g. db.Model) and table columns are defined as class attributes with special constuctors (e.g. db.Column).
Here's a simple model class (along with imports required to create it)
In API terminology, namespace is a prefix for names used by the API that makes them unique. The namespace should be a URI, but it doesn't have to be a real address. However, usually it is convenient to place a document that described the names within the namespace into the namespace URI. For our purposes, namespace contains the custom link relations used by the API.
In Mason namespace should be indicated in each response using the "@namespaces" attribute. For example you can see this namespace definition in all MusicMeta API examples:
Object relational mapping is a way of abstracting database use. Database tables are mapped to programming language classes. These are usually called models. A model class declaration defines the table's structure. When rows from the database table are fetched, they are represented as instances of the model class with columns as attributes. Likewise new rows are created by making new instances of the model class and committing them to the database. This course uses SQLAlchemy's ORM engine.
In database terminology primary key refers to the column in a table that's intended to be the primary way of identifying rows. Each table must have exactly one, and it needs to be unique. This is usually some kind of a unique identifier associated with objects presented by the table, or if such an identifier doesn't exist simply a running ID number (which is incremented automatically).
Profile is metadata about a resource. It's a document intended for client developers. A profile gives meaning to each word used in the resource representation be it link relation or data attribute (also known as semantic descriptors). With the help of profiles, client developers can teach machine clients to understand resource representations sent by the API. Note that profiles are not part of the API and are usually served as static HTML documents. Resource representations should always contain a link to their profile.
In database terminology, query is a command sent to the database that can fetch or alter data in the database. Queries use written with a script-like language. Most common is the structured query language (SQL). In object relational mapping, queries are abstracted behind Python method calls.
Kuvaus
Example
Query parameters are additional parameters that are included in a URL. You can often see these in web searches. They are the primary mechanism of passing arbitrary parameters with an HTTP request. They are separated from the actual address by ?. Each parameter is written as a key=value pair, and they are separated from each other by &. In Flask applications they can be found from request.args which works like a dictionary.
Regular expressions are used in computing to define matching patterns for strings. In this course they are primarily used in validation of route variables, and in JSON schemas. Typical features of regular expressions are that they look like a string of garbage letters and get easily out of hand if you need to match something complex. They are also widely used in Lovelace text field exercises to match correct (and incorrect) answers.
Here's a regular expression that matches valid ISO dates (and some invalid ones)
"^[0-9]{4}-[01][0-9]-[0-3][0-9]$"
Where:
^ marks the start of string
$ marks the end of string (meaning there must not be anything else in the string)
square braces define a group of characters to match
In this course request referes to HTTP request. It's a request sent by a client to an HTTP server. It consists of the requested URL which identifies the resource the client wants to access, a method describing what it wants to do with the resource. Requests also include headers which provide further context information, and possihby a request body that can contain e.g. a file to upload.
Kuvaus
Accessing
In an HTTP request, the request body is the actual content of the request. For example when uploading a file, the file's contents would be contained within the request body. When working with APIs, request body usually contains a JSON document. Request body is mostly used with POST, PUT and PATCH requests.
In Flask the request body is accessed differently depending on its content type.
If the content type is JSON, request body is accessible through request.json as a dictionary
If the content type is form, request body is accessible through request.form
If the content type is some other type of text, it will be in request.data
Kuvaus
Getting data
Request object is related to web development frameworks. It's a programming language object representation of the HTTP request made to the server. It has attributes that contain all the information contained within the request, e.g. method, url, headers, request body. In Flask the object can be imported from Flask to make it globally available.
The request has several different attributes that contain data that might be needed in the view function.
request.json - request body JSON parsed into a Python dictionary
request.args - a dictionary-like object containing query parameters
request.form - a dictionary-like object containing HTML form data
request.headers - a dictionary-like object containing request headers
request.files - files uploaded with the request
request.data - the request body as a string (should never be used for JSON requests in this course!)
in RESTful API terminology, a resource is anything that is interesting enough that a client might want to access it. A resource is a representation of data that is stored in the API. While they usually represent data from the database tables it is important to understand that they do not have a one-to-one mapping to database tables. A resource can combine data from multiple tables, and there can be multiple representations of a single table. Also things like searches are seen as resources (it does, after all, return a filtered representation of data).
Resource classes are introduced in Flask-RESTful for implementing resources. They are inherited from flask_restful.Resource. A resource class has a view-like method for each HTTP method supported by the resource (method names are written in lowercase). Resources are routed through api.add_resource which routes all of the methods to the same URI (in accordance to REST principles). As a consequence, all methods must also have the same parameters.
In this course we use the term representation to emphasize that a resource is, in fact, a representation of something stored in the API server. In particular you can consider representation to mean the response sent by the API when it receives a GET request. This representation contains not only data but also hypermedia controls which describe the actions available to the client.
In this course response refers to HTTP response, the response given by an HTTP server when a request is made to it. Reponses are made of a status code, headers and (optionally) response body. Status code describes the result of the transaction (success, error, something else). Headers provide context information, and response body contains the document (e.g. HTML document) returned by the server.
Response body is the part of HTTP response that contains the actual data sent by the server. The body will be either text or binary, and this information with additional type instructions (e.g. JSON) are defined by the response's Content-type header. Only GET requests are expected to return a response body on a successful request.
Response object is the client side counterpart of request object. It is mainly used in testing: the Flask test client returns a response object when it makes a "request" to the server. The response object has various attributes that represent different parts of an actual HTTP response. Most important are usually status_code and data.
In database terminology, rollback is the cancellation of a database transaction by returning the database to a previous (stable) state. Rollbacks are generally needed if a transaction puts the database in an error state. On this course rollbacks are generally used in testing after deliberately causing errors.
Kuvaus
Routing in Flask
Reverse routing
Flask-RESTful routing
URL routing in web frameworks is the process in which the framework transforms the URL from an HTTP request into a Python function call. When routing, a URL is matched against a sequence of URL templates defined by the web application. The request is routed to the function registered for the first matching URL template. Any variables defined in the template are passed to the function as parameters.
In Flask routes are defined using the app.route decorator in combination with a view function. The decorator takes the route's URL temoplate as its argument. Variables in the URL template match with the function's parameters. E.g.
Reverse routing is used when you want to generate a URL based on routes registered to the application. This is extremely useful for managing routes without breaking code - when a route is changed, all URLs will automatically match the new route if they've been generated with reverse routing. Reverse routing is done with the url_for function, which can be imported from Flask. It takes endpoint name as its first argument. It can be set with the endpoint keyword argument, and it defaults to the view function's name. The rest of the arguments must match the URL template variables.
With Flask-RESTful routing is done for resource classes using the Api object's add_resource method. This routes all different HTTP methods to their corresponding resource class methods.
Reverse routing can be done in two ways: using the method described in the "Reverse routing" tab (default endpoint name is the class name) or using Api object's url_for method which takes the resource class as its first argument and otherwise works identically.
api.url_for(SensorItem,sensor=handle)
This approach is clearer for single file applications but can cause issues with circular imports if you split resources into multiple modules.
In relational database terminology, row refers to a single member of table, i.e. one object with properties that are defined by the table's columns. Rows must be uniquely identifiable by at least one column (the table's primary key).
SQL (structured query language) is a family of languages that are used for interacting with databases. Queries typically involve selecting a range of data from one or more tables, and defining an operation to perform to it (such as retrieve the contents).
Serialization is a common term in computer science. It's a process through which data structures from a program are turned into a format that can be saved on the hard drive or sent over the network. Serialization is a reversible process - it should be possible to restore the data structure from the representation. A very common serialization method in web development is JSON.
In web applications static content refers to content that is served from static files in the web server's hard drive (or in bigger installations from a separate media server). This includes images as well as javascript files. Also HTML files that are not generated from templates are static content.
In database terminology, a table is a collection of similar items. The attributes of those items are defined by the table's columns that are declared when the table is created. Each item in a table is contained in a row.
In software testing, test setup is a procedure that is undertaken before each test case. It prepares preconditions for the test. On this course this is done with pytest's fixtures.
In software testing, test teardown is a process that is undertaken after each test case. Generally this involves clearing up the database (e.g. dropping all tables) and closing file descriptors, socket connections etc. On this course pytest fixtures are used for this purpose.
Universal resource identifier (URI) is basically what the name says: it's a string that unambiguously identifies a resource, thereby making it addressable. In APIs everything that is interesting enough is given its own URI. URLs are URIs that specify the exact location where to find the resource which means including protocol (http) and server part (e.g. lovelace.oulu.fi) in addition to the part that identifies the resource within the server (e.g. /ohjelmoitava-web/programmable-web-project-spring-2019).
Kuvaus
Type converters
Custom converters
URL template defines a range of possible URLs that all lead to the same view function by defining variables. While it's possible for these variables to take arbitrary values, they are more commonly used to select one object from a group of similar objects, i.e. one user's profile from all the user profiles in the web service (in Flask: /profile/<username>. If a matching object doesn't exist, the default response would be 404 Not Found. When using a web framework, variables in the URL template are usually passed to the corresponding view function as arguments.
It's also possible to add type conversion to URL variables. This automatically converts the view function parameters into the correct type, and returns 404 if the conversion cannot be done. Type validating and convering numbers is quite simple:
Floats work the same way. Take care though: the float type specifier only accepts numbers that have a decimal point! This is not a valid URL: "/do-something-with-float/1/"! It would need to be written as "/do-something-with-float/1.0/"
You can also implement custom converters. These are classes that have two methods: to_python and to_url - the first one being responsible for conversion when calling the view function, and the second one for generating URLs with reverse routing. You can find an example by following the link below.
Uniform interface is a REST principle which states that all HTTP methods, which are the verbs of the API, should always behave in the same standardized way. In summary:
GET - should return a representation of the resource; does not modify anything
POST - should create a new instance that belongs to the target collection
PUT - should replace the target resource with a new representation (usually only if it exists)
DELETE - should delete the target resource
PATCH - should describe a change to the resource
In database terminology, unique constraint is a what ensures the uniqueness of each row in a table. Primary key automatically creates a unique constraint, as do unique columns. A unique constraint can also be a combination of columns so that each combination of values between these columns is unique. For example, page numbers by themselves are hardly unique as each book has a first page, but a combination of book and page number is unique - you can only have one first page in a book.
Kuvaus
Registering
View functions are Python functions (or methods) that are used for serving HTTP requests. In web applications that often means rendering a view (i.e. a web page). View functions are invoked from URLs by routing. A view function always has application context.
View functions are registered using the app.route decorator. A view function's parameters must match the variables in the URL template given to the decorator:
A Python virtual environment (virtualenv, venv) is a system for managing packages separately from the operating system's main Python installation. They help project dependency management in multiple ways. First of all, you can install specific versions of packages per project. Second, you can easily get a list of requirements for your project without any extra packages. Third, they can placed in directories owned by non-admin users so that those users can install the packages they need without admin privileges. The venv module which is in charge of creating virtual environments comes with newer versions of Python.
Virtual environments are created using the venv module. It can be invoked through the Python interpreter from the command line:
python -m venv /path/to/the/virtualenv
in most Linux and OS X systems the command to use is python3 instead of python.
To use the virtual environment's Python packages, it must be activated. In Linux and OS X this is done by
source /path/to/the/virtualenv/bin/activate
and in Windows:
C:\path\to\the\virtualenv\Scriptrs\activate
Upon activation the virtual environment's name will be placed at the beginning of the command prompt. E.g.
(pwp-env) user@computer:~/$
In all operating systems you can deactivate the virtual environment by giving the deactivate command.
Interface, implemented using web technologies, that exposes a functionality in a remote machine (server). By extension Web API is the exposed functionality itself.
 Anna palautetta
Anna palautetta