In database terminology primary key refers to the column in a table that's intended to be the primary way of identifying rows. Each table must have exactly one, and it needs to be unique. This is usually some kind of a unique identifier associated with objects presented by the table, or if such an identifier doesn't exist simply a running ID number (which is incremented automatically).
Learning Outcomes and Material¶
During this exercise students will learn how to design a
Hypermedia
API. Students will learn also how to document their API using Apiary, a professional documentation framework. We expect that you follow the same process as the one described in this exercise in order to complete the Deliverable 3.The slides presenting the content of the lecture can be downloaded from the following link:
In addition, we included an additional set of slides containing main hypermedia formats that you can use in your project work. We recommend you to choose either Collection+JSON or Mason.
More on hypermedia formats can be found from the course material. We recommend:
- Chapter 10 of Hypermedia Web APIs book.
- Ammundsen lecture about RESTful and Hypermedia. https://www.youtube.com/watch?v=UkAt9XSOfaE . Related presentation by same author: http://amundsen.com/talks/2015-04-codepalousa/gap-slides.pdf
Hypermedia API Design and Documentation¶
This exercise material is a more hands-on tutorial to design considerations regarding (hypermedia) APIs. It also introduces one particular tool for documenting APIs. The material tells you - through examples - what is required from your API documentation for deadline 3 of the project work. While it may sound a bit backward that we're asking you to document your API before implementing it, there's a couple of reasons. First of all, we want you to really focus on the interface when designing your API. You should think about the best ways for the clients to access your API. If you implement before documeting, your API will instead be based on your implementation and its limitations. Second, this way you will receive feedback about your API before implementing it. It's much easier to make corrections on the design and documentation than on an implemented API.
This material mostly follows the requirements in your project report. We will outline the API concept and then move on to making a fully documented REST API that uses
hypermedia
for resource
representations. We'll explain the design decisions as we go, which will hopefully help you understand REST concepts and the use of hypermedia. Please note that this material has been written with the expectation that the reader is familiar with RESTful API concepts from the lecture materials or relevant course book chapters.
API Concept¶
The API concept in this material is a service that stores metadata about music. The metadata is split into three levels: artist, album and track. The API can be used to enrich music-related data from other sources, and can also be used to fill in partial metadata of a poorly managed music collection. This example is interesting because the problem domain has some peculiar characteristics that require additional design considerations. It's also a good API example because its primary clients are machines.
The data schema is not particularly large: artists are authors of albums which contain tracks. So we have a clear hierarchy that is easy enough to represent in a database.
Challenges¶
The first challenge related to the problem domain is that names of artists, albums or tracks are not generally not trademarkable. In other words they are not unique. You can find multiple artists - sometimes even from the same country - with the exact same name. The same goes for album names. On the other hand, artists typically don't have multple albums with the same name. Usually albums don't have multiple tracks with the same name either but there's an exception: there can be multiple untitled tracks on an album. One way or another our API needs to navigate this non-uniqueness mess.
The second challenge is the existence of "various artists" releases (VA for short), i.e. collaborative works. These are albums that have multiple artists, with one or more tracks from each. With these releases each track has to have its artist defined separately unlike normal releases where all tracks on an album are by the same artist. So although these two types of releases are very similar, they are not identical and will require some degree of differing treatment.
Related Services¶
This example API provides similar data as two free services for music metadata: Musicbrainz and FreeDB. These services are often used when ripping audio files from CDs because they have a CD checksum lookup for metadata. Of course our example is more limited but it is a RESTful API unlike these two. There's also Rate Your Music which offers meta information for human users.
An example of a data source that can be used with this API is last.fm which is a tracking site for your personal music listening. It has a lot of metadata of its own but one tragic failing: it is unable to track listening time accurately as the primary statistcs are listening counts per track. This means that the statistics are biased towards artists that have shorter average track length. Not to worry, last.fm has its own API. It would be possible to pull data from there and combine with the length metadata from our proposed API!
Database Design¶
From our concept we can easily come up with a database that has three
models
: album, artist and track. However we also need to consider the VA exception when designing these models, so we actually have two additional item types to represent: VA album and VA track. We also need to figure out unique constraints
for each model. Although everything in the database has a unique primary key, you should never use raw database IDs to address resources in an API. First of all they don't mean anything. Second, it introduces vulnerabilities for APIs that don't want unauthorized clients to infer details about the content. Unique constraint allows us to define more complex definitions of uniqueness than just defining individual columns as unique. A combination of multiple columns can be made into a unique constraint so that a certain combination of values in these columns can only appear once. For example, we can probably assume that the same artist is not going to have multiple albums with the same name (we're not counting separate editions). So while album title by itself cannot be unique, album title combined with the artist ID foreign key can.
def Album(db.Model):
__table_args__ = (db.UniqueConstraint("title", "artist_id", name="_artist_title_uc"), )
Please note the comma at the end: this tells Python that this is a 1 item tuple, not a single value in regular parenthesis. You can list as many as column names for the unique constraint as you want. The name at the end doesn't matter, but has to exist, so better make it descriptive. For individual tracks we have an even better unique constraint: each album can only have one track at each disc index (per disc). So the unique constraint for tracks is a combinaton of album ID, track number and disc number.
def Track(db.Model):
__table_args__ = (db.UniqueConstraint("disc_number", "track_number", "album_id", name="_track_index_uc"), )
We're going to solve the VA problem by allowing an album's artist foreign key to be null, and by adding an optional va_artist field to tracks. We'll make this mandatory for VA tracks on the application logic side later. Overall our database code ends up looking like this:
From it you can also see how to set default ordering for relationships and a couple of other things that weren't covered in the previous exercise.
Resource Design¶
We're now ready to design the
resources
provided by our API. An important takeaway from this section is how we turn three database models
into (way) more than three resources. We will also explain how HTTP methods
are used in this API by following REST principles.Resources from Models¶
A resource should be something that is interesting enough to be given its own
URI
in our service. Likewise each resource must be uniquely identifiable by its URI. It's quite common for an API to have at least twice as many resources as it has database tables
. This follows from a simple reasoning: for each table, a client might be interested in the table as a collection, or just in an individual row
in the table. Even if the collection representation
has all the stored data about each of its items, the item representation must also exist if we want to enable clients to manipulate them.If we were to follow this very simple reasoning, we'd have 6 resources:
- artist collection
- artist item
- album collection
- album item
- track collection
- track item
It is worth noting that a collection type resource doesn't necessarily have to contain the entire contents of the associated table. For instance contextless track collection makes very little sense; a collection of tracks by album makes more sense. In fact an album is a collection of tracks, so having a separate track collection resource might not even make sense. Artist collection is simple enough because artist is on top of the hierarchy, so it makes sense for the collection to have all artists. What about albums though? Like tracks, it does make sense to have "albums by an artist" as a collection resource. But we also have VA albums to worry about. We can make two collection resources: one for an artist's albums and another for VA albums. We end up with:
- artist collection
- artist item
- albums by artist collection
- VA albums collection
- album item (incorporates track collection)
- track item
However, we have slightly different representation for VA albums compared to normal albums, and same goes for tracks. Even though we chose the same
model
to represent both, they do have ever so slightly different requirements to be valid: for normal albums, we must know the artist; for VA album tracks we must know the track artist. So it would be fair to say that these are in fact separate representations
that should be added as resources. Finally let's add a collection of all albums so that clients can see what albums our API has data for.- artist collection
- artist item
- all albums collection
- albums by artist collection
- VA albums collection
- album item (incorporates track collection)
- VA album item (incorpotes VA track collection)
- track item
- VA track item
Bonus consideration: Why are we incorporating track collection into album, but not incorporating album colletion into artist? Mostly because artist as a concept is more than a collection of albums. For example artist could also be a collection of people (band members). The API should state what it means explicitly, and therefore it is better to separate "artist" from "albums by artist".
Routing Resources¶
After identifying what's considered important enough (and different enough) to be regarded as its own
resource
, we now have to come up with URIs
so that each can be uniquely identified (addressability principle
). This also defines our URI hierarchy. We want the URIs to convey the relationships between our resources. For normal albums the hierarchy goes like this:artist collection
└── artist
└── album collection
└── album
└── track
We decided that album title paired with artist ID is sufficient for
uniqueness
. We also decided that the best way to uniquely identify a track is to use its position an the album as an index consisting of disc and track numbers. Taking all this into account, we end up with a route that looks like this:/api/artists/{artist_unique_name}/albums/{album_title}/{disc}/{track}/
This uniquely identifies each track, and also clearly shows the hierarchy. All the intermediate resources (both collections and items) can be found by dropping off parts from the end. We will separate VA albums from the rest by using VA to replace {artist}, ending up with this route to identify each VA track:
/api/artists/VA/albums/{album_title}/{disc}/{track}/
Then we need to add one more separate branch to the URI tree for the collection that shows all albums:
/api/albums/
The entire URI tree becomes:
api
├── artists
│ ├── {artist}
│ │ └── albums
│ │ └── {album}
│ │ └── {disc}
│ │ └── {track}
│ └── VA
│ └── albums
│ └── {album}
│ └── {disc}
│ └── {track}
└── albums
Resource Actions¶
Following REST principles our API should offer actions as
HTTP methods
targeted at resources. To reiterate, each HTTP method should be used as follows:- GET - should return a representation of the resource; does not modify anything
- POST - should create a new instance that belongs to the target collection
- PUT - should replace the target resource with a new representation (only if it exists)
- DELETE - should delete the target resource
- PATCH - should describe a change to the resource - generally not recommended, see extra chapter
Most resources should therefore implement GET. Collection types usually implement POST whereas PUT and DELETE are typically attached to individual items. In our case we make two exceptions: first, as album serves as both an item and as a collection, it actually implements all four; second, the albums resource at the bottom of the URI tree above should not provide POST because there is no way of knowing from the URI which artist is the author. The parent of a new item should always be found from the URI - not in the
request body
. We're not using PATCH in this example.Gathering everything into a table:
| Resource | URI | GET | POST | PUT | DELETE |
| artist collection | /api/artists/ | X | X | - | - |
| artist item | /api/artists/{artist}/ | X | - | X | X |
| albums by artist | /api/artists/{artist}/albums/ | X | X | - | - |
| albums by VA | /api/artists/VA/albums/ | X | X | - | - |
| all albums | /api/albums/ | X | - | - | - |
| album | /api/artists/{artist}/albums/{album}/ | X | X | X | X |
| VA album | /api/artists/VA/albums/{album}/ | X | X | X | X |
| track | /api/artists/{artist}/albums/{album}/{disc}/{track}/ | X | - | X | X |
| VA track | /api/artists/VA/albums/{album}/{disc}/{track}/ | X | - | X | X |
Since we are following the
uniform interface
REST principle and each HTTP method does what it's expected to, this table actually tells a lot about our API: it shows every possible HTTP
request that can be made and even hints at their meaning: if you send a PUT request to a track resource, it will modify the track's data (even more specifically it will replace all data with what's in the request body). It just doesn't do a very good job of explaining what requests and responses should look like.Just Add Happiness¶
Using everything we've told you about the API so far, what URI do you need to use if you want to add the track "Happiness" (third track on Kallocain, album by Paatos). For this task, the artist's unique name is simply the artist's name in lowercase.
 Anna palautetta
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Enter Hypermedia¶
In order for client developers to know what to actually send - and what to expect in return - APIs need to be documented. On this course we are using
hypermedia
in responses given by the API. This solves part of the documentation issue because the API itself describes possible actions that can be taken to the client. For this example we have chosen Mason as our hypermedia format because it has a very clear syntax for defining hypermedia elements and connecting them to data. Data Representation¶
Our API communicates in
JSON
. There isn't a whole lot to data representation really, it's a rather straightforward serialization
process from model
instance attributes to JSON attributes. If the client sends a GET request to, say, /api/artists/scandal/ the data that is returned would be serialized into this:{
"name": "Scandal",
"unique_name": "scandal",
"location": "Osaka, JP",
"formed": "2006-08-21",
"disbanded": null
}
Likewise if the client wants to add a new artist, they'd send almost an identical JSON document, sans unique_name because it is generated by the API server. A similar serialization process can be applied for all models. Collection type resources will have
"items" attribute which is an array containing objects that are part of the collection. Most notably albums have both root level data about the album itself, and an array of tracks. It's also worth noting that collection types don't necessarily have to include all the data about their members. For example in album collections we have deemed it sufficient to show album title and artist name:{
"items": [
{
"artist": "Scandal",
"title": "Hello World"
},
]
}
If the client wants more information about the album, it can always send a GET to the album resource itself. But how does it know how to do that?
Hypermedia Controls and You¶
You can consider the API as a map and each
resource
as a node. The resource that you most recently sent a GET request to is basically the node that says "you are here". Hypermedia
controls
describe the logical next actions: where to go next, or actions that can be performed with the particular node you're in. Together with the resources they actually form a client-side state diagram of how to navigate the API. Hypermedia controls are extra attributes attached to the data representation
we just saw. A hypermedia control is a combination of at least two things:
link relation
("rel") and target URI
("href"). These answer two questions: what does this control do, and where to go to activate it. Note that link relation is a machine-readable keyword, not a description for humans. Many generally used relations are being standardized (full list) but APIs can define their own when needed as well - as long as each relation always means the same thing. When a client wants to do something, it uses the available link relations to discover what URI the next request should go to. This means that clients using our API should never need to have hardcoded URIs - they will find the URI by searching for the correct relation instead.Mason also defines some additional attributes for hypermedia controls. Of these "method" is one that we will be using frequently, because it tells which
HTTP method
should be used to make the request (usually omitted for GET as it is assumed to be the default). There's also "title" which can be used in generic clients
(or other generated clients) to help the client's human user figure out what the control does. Even beyond that we can also include JSON schema representation that defines how to send data to the API. In Mason hypermedia controls can be attached to any object by adding the
"@controls" attribute. This in itself is an object where link relations are attribute names whose values are also objects that have at least one attribute: href. For example, here is a track item with controls to get back to the album it is on ("up") and to edit its information ("edit"):{
"title": "Wings of Lead Over Dormant Seas",
"disc_number": 2,
"track_number": 1,
"length": "01:00:00",
"@controls": {
"up": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/"
},
"edit": {
"href": "/api/artists/dirge/albums/Wings of Lead Over Dormant Seas/2/1/",
"method": "PUT"
}
}
}
Or if we want each item in a collection to actually have its own URI available to clients:
{
"items": [
{
"artist": "Scandal",
"title": "Hello World",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Hello World/"
}
}
},
{
"artist": "Scandal",
"title": "Yellow",
"@controls": {
"self": {
"href": "/api/artists/scandal/albums/Yellow/"
}
}
}
]
}
Custom Link Relations¶
While it's good to use standards as much as possible, realistically each API will have a number of
controls
whose meaning cannot be explicitly conveyed with any of the standardized relations
. For this reason Mason documents can use link relation namespaces
to extend available link relations. A Mason namespace defines a prefix and its associated namespace (similar to XML namespace, see CURIEs). The prefix will be added to link relations that are not defined in the IANA list. When a relation is prefixed with a namespace prefix, it is meant to be interpreted as attaching the relation at the end of the namespace and makes the relation unique - even if another API defined a relation with the same name, it would have a different namespace in front. For example if want to have a relation called "albums-va" to indicate a control that leads to a collection of all VA albums, its full identifier could be
http://wherever.this.server.is/musicmeta/link-relations/#albums-by. To make this look less wieldy we can define a namespace prefix called "mumeta", and then include this control like so:{
"@namespaces": {
"mumeta": {
"name": "http://wherever.this.server.is/musicmeta/link-relations/#"
}
},
"@controls": {
"mumeta:albums-va": {
"href": "/api/artists/VA/albums"
}
}
}
Also if a client developer visits the full URL, they should find a description about the link relation. Note also that this is normally expected to be a full URL because the server part is what guarantees uniqueness. In later examples you will see we're using a relative
URI
- this way the link to the relation description itself works even if the server is running in a different address (i.e. most likely localhost:someport). Information about the link relations must be stored somewhere. Note that this is intended for client developers i.e. humans. In our case a simple HTML document with anchors for each relation should be sufficient. This is why our namespace name ends with #. It makes it convenient to find each relation's description. Before moving on, here's the full list of custom link relations our API uses:
add-album, add-artist, add-track, albums-all, albums-by, albums-va, artists-all, delete.API Map¶
The last order of business in designing our API is to create a full map with all the
resources
and hypermedia
controls
visible. This a kind of a state diagram where resources are states and controls are transitions. Generally speaking only GET methods are used to moving from one state to another because other methods don't return a resource representation
. We have presented other methods as arrows that circle back to the same state. Here's the full map in all its glory. 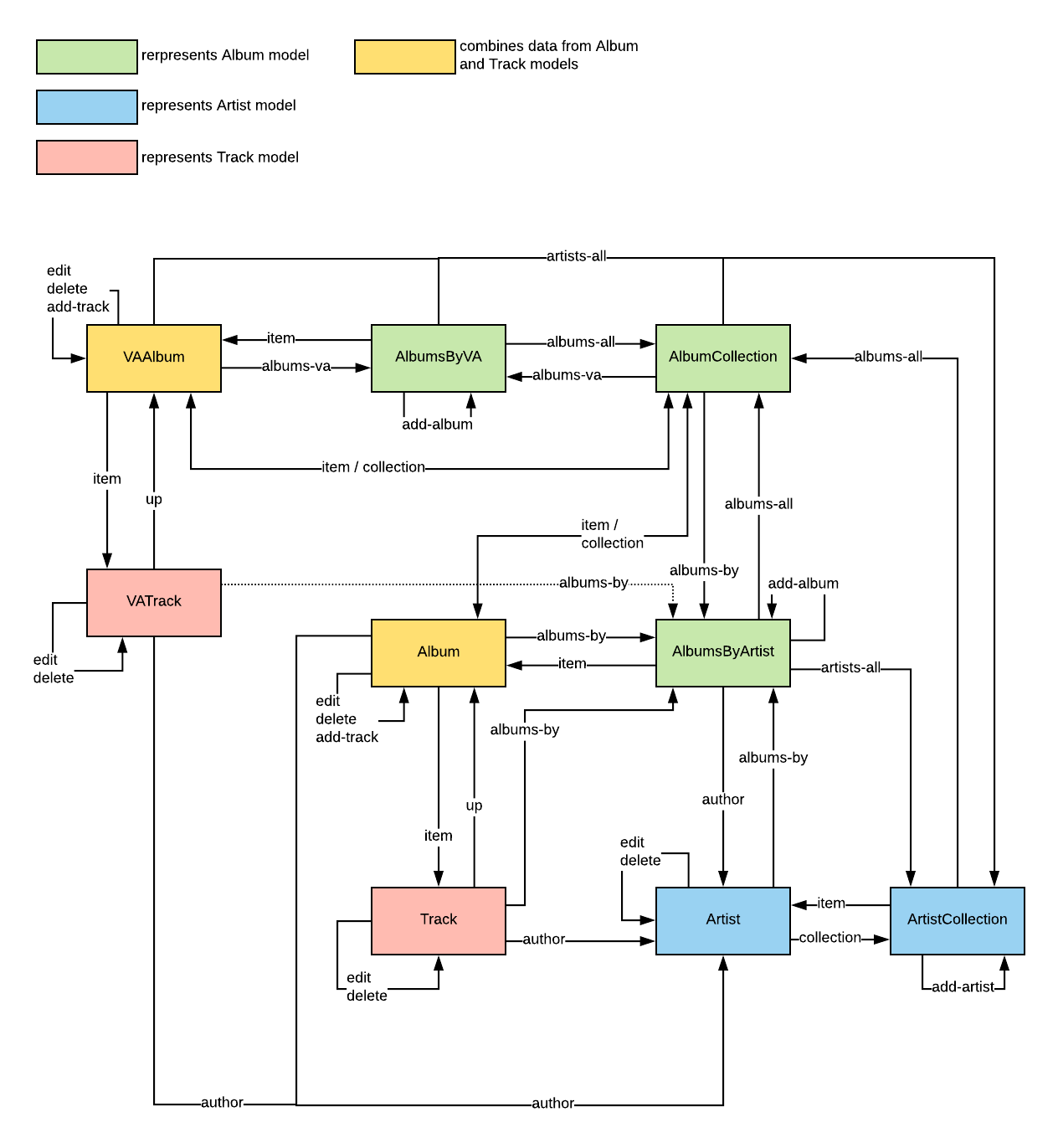
NOTE: The box color codes are only included for educational purposes to show you how data from the database is connected to resources - you don't need to share implementation details like this in real life, or your course project for that matter.
NOTE 2: the
link relation
"item" does not exist, this is actually "self". In this diagram "item" is used to indicate that this is a transition to an item from a collection through the item's "self" link.A map like this is useful when designing the API and should be done before designing individual representations returned by the API. As all actions are visible in a single diagram, it's easier to see if something is missing. When making the diagram keep in mind that there must be a path from every state to every other state (
connectedness
principle). In our case we have three separate branches in the URI
tree and therefore we have to make sure to include transitions between brances (e.g. AlbumCollection resource
has "artists-all" and "albums-va"). The Road to Transcendence¶
Consider the above state diagram. Let's assume you're a machine client. You are currently standing in the ArtistCollection node. The goal is to find and modify data about a various artists album titled "Transcendental" (collaboration of Mono and The Ocean). Which links have to be followed in order to do that? Does that path make sense to you?
For your answer, type the shortest list of link relations (use same names as in the diagram) that lead you from ArtistCollection to modifying the VA album's data.
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Entry Point¶
A final note about mapping API is the
entry point
concept. This should be at the root of the API (in our case: /api/. It's kind of like the API's index page. It's not a resource
, and isn't generally returned to (which is why it isn't in the diagram). It just shows the reasonable starting options a client has when "entering" the API. In our case it should have controls
to GET either the artists collection or the albums collection (potentially also the VA album collection). Enter the Maze¶
Create a JSON document of the MusicMeta APIs entry point. It should contain two hypermedia controls: link to the artist collection, and link to the albums collection. You should be able to figure out the link relations of these controls from the state diagram. Don't forget to use the mumeta namespace!
UPDATE: the checker has been changed from a static examiner to a system that generates requests using your JSON document and sends them to the reference server
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Advanced Controls with Schema¶
Up to now we have defined possible actions by using
hypermedia
. Each action comes with a link relation
that has an explicit meaning, address for the associated resource, and the HTTP method
to use. This information is sufficient for GET and DELETE requests, but not quite there for POST and PUT - we still don't know what to put in the request body
. Mason supports adding JSON Schema
to hypermedia controls. The schema defines what kind of JSON
document will be considered valid by the API. As an example, here's the complete schema for albums:{
"type": "object",
"properties": {
"title": {
"description": "Album title",
"type": "string"
},
"release": {
"description": "Release date",
"type": "string",
"pattern": "^[0-9]{4}-[01][0-9]-[0-3][0-9]$"
},
"genre": {
"description": "Album's genre(s)",
"type": "string"
},
"discs": {
"description": "Number of discs",
"type": "integer",
"default": 1
}
},
"required": ["title", "release"]
}
For objects, the schema itself is made of three attributes:
- "type" - this defines the type, usually "object" but sometimes "array"
- "properties" - an object that defines all the possible/expected attributes
- "required" - array that lists which of the properties are mandatory
Properties generally have "description" (for human readers) and "type". They can also have some other attributes as seen in the example: pattern - a
regular expression
that defines what kinds of values are valid for this attribute (compatible with strings only); default which is the value taken by this attribute in case it is omitted. These are just some basic things JSON schema can do. You can read more from its specification. A schema object like this one can be attached to a Mason hypermedia
control
by assigning it to the "schema" attribute. If the schema is particularly large or you have another reason to not include it in the response body, you can alternatively provide the schema from a URL on your API server (e.g. /schema/album/) and assign the URL to the "schemaUrl" attribute so that clients can retrieve it. The client can then use the schema to form a proper request when sending data to your API. Whether a machine client can figure out what to put into each attribute is a different story. One option is to use names that conform to a standard e.g. we could use the same attribute names as IDv2 tags in MP3 files. Schemas are particularly useful for (partially) generated clients that have human users. It's quite straightforward to write a piece of code that generates a form from a schema so that the human user can fill it. We'll show this in the last exercise of the course. On the API side schemas actually pull a double duty - they can be used to validate the client's requests too (e.g. with this). It's probably worth noting that the date pattern in our example is not foolproof (it'd accept something like 2000-19-39) which must be taken into account in the implementation. A completely foolproof regex would be quite a bit longer - feel free to see if you can come up with one.
Schemas can also be used for resources that use
query parameters
. In this case they will described the available parameters and values that are accepted. As an example we can add a query parameters that affects how the all albums collection is sorted. Here's the "mumeta:albums-all" control with the schema added. Note also the addition of "isHrefTemplate", and that "type": "object" is omitted from the schema.{
"@controls": {
"mumeta:albums-all": {
"href": "/api/albums/?{sortby}",
"title": "All albums",
"isHrefTemplate": true,
"schema": {
"properties": {
"sortby": {
"description": "Field to use for sorting",
"type": "string",
"default": "title",
"enum": ["artist", "title", "genre", "release"]
}
},
"required": []
}
}
}
}
Client Example¶
In order to give you some idea about why we're going through all this trouble and adding a bunch of bytes to our payloads, let's consider a small example from the client's perspective. Our client is a submission bot that browses its local music collection and sends metadata to the API for artists/albums that do not exist there yet. Let's say its local collection is grouped by artists, then albums. Let's say it's currently examining an artist folder ("Miaou") that contains one album folder ("All Around Us"). The goal is to see if this artist is in the collection, and whether it has this album.
- bot enters the api and finds the artist collection by looking for a hypermediacontrolnamed "mumeta:artists-all"
- bot sends a GET to the artist collection using the hypermedia control's href attribute
- bot looks for an artist named "Miaou" but doesn't find it
- bot looks for "mumeta:add-artist" hypermedia control
- bot compiles a POST request using the control's href attribute and the associated JSON schema
- after sending the POST request, the bot discovers the artist's address from the response's location header
- bot sends a GET to the address it received
- from the artist representation the bot looks for the "mumeta:albums-by" hypermedia control
- bot send a GET to the control's href attribute, receiving an empty album collection
- since the album is not there, bot looks for "mumeta:add-album" control
- bot compiles a POST request using the control's href attribute and the associated JSON schema
The important takeaway from this example is that the bot doesn't need to now any
URIs
besides /api/. For everything else it has been programmed to look for link relations
. All the addresses it visits are parsed from the responses it gets. They could be completely arbitrary and the bot would still work. Depending on the bot's AI it can survive quite drastical API changes (for example when it GETs the artist representation and finds a bunch of controls, how exactly has it been programmed to follow "mumeta:albums-by"?) One really cool thing about hypermedia APIs is that they usually have a generic client to browse any API if it's valid. The client will generate a human-usable web site by using hypermedia controls to provide links from one view to another, and schemas to generate forms.
Hypermedia Profiles¶
By adding
hypermedia
we have managed to create APIs that machine clients can navigate once they have been taught the meaning of each link relation
, and the meaning of each attribute in resource representations
. But how exactly does the machine learn these things? This is a ongoing challenge for API development - for now one way is to educate the human developers by using resource profiles
. Profiles describe the semantics of resources in human-readable format. This way human developers can transfer this knowledge to their client, or a human user of a client can use this knowledge when navigating the API.What's in a Profile?¶
There's no universal consensus about what exactly should be in a profile, or how to write one. Regardless of how it's written, the profile should have semantic descriptors for attributes (of the resource representation) and protocol semantics for actions that can be taken (or a list of link relations associated with the resource). Collections don't necessarily have their own profiles, like in our example they don't. Except for album since it is both an item and a collection.
If your resource represents something that is relatively common, using attributes defined in a standard (or standard proposal) is recommended. If your entire resource representation can conform to a standard, all the better. You can look for standards in https://schema.org/. One important future step for our example API would be to use attributes from this schema for albums and tracks.
Distributing Profiles¶
Like
link relations
, information about your profiles
should be accessible from somewhere. In our example we have chosen to distribute them as HTML pages from the server using routing
/profiles/{profile_name/. Links to profiles can be inserted as hypermedia
controls
using the "profile" link relation. For example, to link the track profile from a track representation
:{
"@controls": {
"profile": {
"href": "/profiles/track/"
}
}
}
Another possibility is to use HTTP Link
header
in responses. Link: <http://where.ever.the.server.is/profiles/track/>; rel="profile"
However this is somewhat more ambiguous. Our album
resource
is an example that actually should link to two profiles - album and track. For this reason we have included profiles as hypermedia controls, and for collection types we have included one with every item. API Documentation¶
Ultimately your API is only as good as its documentation. APIs should be documented using one of the prevalent standards, i.e. API Blueprint or OpenAPI. Both standards come with a nice set of related tools: from documentation browsing to automated test generation (see API Blueprint tools section for way more examples). For this exercise we have chosen to use API Blueprint, and the Apiary editor for creating interactive documentation.
The syntax of API Blueprint is relatively simple. You can start by going through the official tutorial. You can learn the rest from our example. You should also create an Apiary account and use the editor there for going through the remaining examples and tasks.
Describing a Resource¶
This is a very brief guide about how each
resource
should be represented in your documentation. Resource description starts with its name, followed by its URI
in square braces, e.g. Underneath you can write a human-readable description.## Album Collection [/api/albums/]
If the resource URI contains variables, these should be described as parameters, like this:
## Albums by Artist [/api/albums/{artist}/]
+ Parameters
+ artist (string) - artist's unique name (unique_name)
After this, each action should be described using a descriptive title and
HTTP method
. This can be followed by a human-readable description.### List all albums [GET]
For each action, you should include its
link relation
. You also need to include a request section, and response sections for each possible status code. All of these sections should also contain examples of valid requests, and of API responses. For example, documentation for Albums by Artist's GET method (message bodies omitted for brevity, see the full example later). ### List albums by artist [GET]
+ Relation: albums-by
+ Request
+ Headers
Accept: application/vnd.mason+json
+ Response 200 (application/vnd.mason+json)
+ Body
...
+ Response 404 (application/vnd.mason+json)
+ Body
...
Hypermedia Issue¶
Warning: intentional tool abuse ahead. We have one inconvenience when using these otherwise very nice standards: they don't support
hypermedia
. That is to say, the syntax doesn't have any way for including link relations
or resource
profiles
into the same document. This is why we are actually just serving the from the server as HTML files. However for our API Blueprint examples, and also for the final task, we're actually just going to do a little bit of abuse. More specifically, we are going to include two groups: link relations and profiles, and inside those groups each link relation and profile will be added using the syntax for resources. Doing this creates documentation that is nicer to browse for humans as everything will appear neatly in the index, and we can put anchor links inside the documentation for quick access to different sections. However, this intentional abuse does not play nicely with automated tools because they try to treat everything as resources. There are existing proposals to include hypermedia properly into the syntax, but for now we have only these two options: either we don't include link relation and profile information in the Apiary documentation, or we put them in as "resources".
API Blueprint Example¶
Below is an example that documents the album-related resources of our API. The text file itself is rather long; if you want to get a better browsing experience, we'd recommend that you copypaste the contents into a new Apiary project.
Important caution: the editor doesn't seem to autosave. Be sure to mash the Save button religiously after changes - just make sure your document is valid first (and yes, do fix warnings). Everything should be indented with 1 tab or 4 spaces, except body elements - those should be indented twice in relation to the
+ Body section header.You can also go to the Documentation tab to browse the API documentation using the whole screen width. Click on the various requests in the document to open details about that request (and possible responses) to the right side of the documentation browser.
API Blueprint Artist¶
We're totally not done with lame pun titles. To wrap up this exercise and learn a bit of API Blueprint, we want you to fulfill part of the Music Meta API documentation. The example we provided contains the album resource group. Your job is to add the resource group for artists.
Learning goals: Learn how to write valid API Blueprint syntax. Learn how to properly document a resource.
Before you begin:
You should make your additions to the example. If you haven't downloaded it yet and put it into Apiary, do so now. Add the resource group for artists, and start working on two new resource descriptions. You should also keep the state diagram from earlier at hand, as well as the database models we showed in the beginning. As a general tip: follow the examples. Your resource descriptions must contain all the same information. You can come up with your own artist examples for the data.
Artist Collection resource
The artist collection includes all artists. For each artist, all column values except ID are shown in their collection entries, using the same names as the database columns. The resource supports two methods: GET to retrieve the description, and POST to create a new artist.
For GET you must include an example response body which includes all the controls leading away from the ArtistCollection resource in the state diagram. Note that some of the controls are located artist entries, not in the root level, and don't forget to use namespaces. Also note that add-artist needs to include a JSON schema. The response body should also include at least one artist's data. The artist entries should be an array in the "items" attribute, and the first artist must be one that you know to exist (i.e. one from the other examples, or the one in your POST example request).
For POST you must include a valid example request body that has values for all fields. You must also include responses for the following error codes: 400 and 415. You don't need to include response bodies.
Artist resource
The artist resource includes the same information as the collection for one artist. The resource supports three methods: GET, PUT and DELETE. The resource should describe an artist that you know to exist.
For GET you must include an example response body which includes all the controls leading away from the Artist resource in the state diagram. The edit link must also include a JSON schema. In addition to the 200 reponse, also add 404 (no response body needed).
For PUT you must include a valid example request body that has values for all fields. You must also include responses for the following error codes: 400, 404, 415.
For DELETE you just need to have responses with the correct status codes. The only error is 404.
UPDATE: The checker is now live. It performs tests by generating requests using information from your API blueprint and its JSON example requests/responses. This is once again very experimental technology, let us know if there are any problems.
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Anna palautetta
Kommentteja materiaalista?