Liukuhihnaprosessori¶
Osaamistavoitteet: Suorittimen liukuhihnatoteutuksen periaatteet sekä käskyjen ja datan riippuvuuksien aiheuttamista ongelmatilanteista selviäminen. Liukuhihnan suorituskyky.
Aiemmin esittelimme sekventiaalisen prosessorin, jossa jokainen käsky suoritetaan yhden kellojakson aikana. Tässä on kuitenkin haittana se, että koko käskyn suoritusaika määrittää kellojakson pituuden. Esimerkiksi von Neumann-arkkitehtuureissa pitäisi tehdä kaksi erillistä muistiosoitusta per käsky. Myös muistiosoituket ovat hitaita. Lisäksi sekventiaalisen prosessorin eri vaiheita toteuttavat osajärjestelmät ovat suurimman osan kellojaksosta tekemättä mitään.
Prosessorin toiminnan tehostamiseksi on esitetty osajärjestelmien liukuhihnoittamista (engl. pipeline), jossa osajärjestelmät ovat kokoajan käytössä, suorittaen peräkkäisten käskyjen eri vaiheita. Kun käskyt etenevät vaiheesta toiseen, niitä seuraava käsky tulee tilalle, ts. etenee nykyisen käskyn edelliseen vaiheeseen. Nyt kellojakson pituuden määrittää pisimpään kestävän osajärjestelmän suoritusaika, eikä koko käskyn suoritusaika.
Kuvassa alla esimerkki liukuhihnasta y86-prosessorissa. Kirjaimet viittaavat käskyn suorituksen eri vaiheisiin. Huomataan, ettei PC update-vaihetta enää ole, josta lisää hetken päästä..
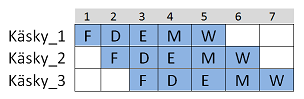
Nyt kolme käskyä sekventiaalisessa prosessorissa veisivät 15 (3 x 5) aikayksikköä. Liukuhihnalla ne saadaan suoritetuksi 7:ssa aikayksikössä. Voidaan siis saavuttaa merkittävä parannus ohjelman suoritusaikaan! (Kellojaksoina ajatellen sekventiaalinen suoritin veisi 3 pitkää kellojaksoa ja liukuhinatoteutus 7 lyhyttä kellojaksoa.)
Liukuhihnatoteutus ei ole ongelmaton (kaikkea muuta itseasiassa). Ensinnäkin, sekventiaalisen suorittimen mikroarkkitehtuurissa eri osajärjestelmät eri vaiheissa samoja signaaleja/rekistereitä. Esimerkiksi y86:sessa Fetch-vaiheen valC-signaali (vakioarvo) menee käskystä riippuen Execute-vaiheeseen saakka. Seuraava käsky Fetch-vaiheessa voi myös tarvita valC-rekisteriä vakioarvon välittämiseen, kun se on vielä edellisen käskyn käytössä.
Likuhihnatoteutuksissa ongelma hoidetaan asettamalla erillisiä liukuhihnarekistereitä vaiheiden väliin, joihin joka vaiheesta saadut output-arvot tallentuvat ja joita käytetään seuraavan vaiheen sisääntuloina. Näin välitulokset seuraavat käskyä vaihe vaiheelta ilman, että ne sotkeutuisivat muiden käskyjen vastaaviin signaaleihin. Nyt useaa eri käskyä voidaan suorittaa synkronoidusti samaan aikaan. Kuvassa alla jokaista vaihetta edeltää sen oma liukuhihnarekisteri. Seurauksena jokaisen vaiheen suoritusaika pitenee hieman.

Hasardit¶
Ihan vielä emme kaivaudu y86:sen liukuhihnatoteutukseen, vaan katsotaan ensin millaisia vaikutuksia liukuhihnoituksella on yleisesti ohjelmien suoritukseen. Liukuhihnatoteutuksissa yleinen ongelma on, että eri käskyjen välillä on riippuvuuksia.
- Kun riippuvuuksia on käskyjen operadien välillä, puhutaan data-hasardista (engl. data hazard). Esimerkiksi toisen käskyn output voi olla toisen input.
- Kun riippuvuuksia on käskyjen välillä, puhutaan kontrolli-hasardista (engl. control hazard). Esimerkiksi ehdolliset käskyt, joiden suoritus riippuu tilabiteistä.
Katsotaanpa tarkemmin, millaisia riippuvuuksia on ja miten niistä (yleisesti) selvitään.
Datankäsittelyn hasardit¶
Tarkastellaan esimerkkikoodia, jossa ei sekventiaalisella prosessorilla suoritettaessa ole mitään ihmeellistä.
irmovq $10,%rdx # rdx=10
irmovq $3,%rax # rax=3
addq %rdx,%rax # rax=rax+rdx
halt
Kun koodi ajetaan liukuhihnaprosessorissa, kohtaamme ongelman. Kaksi ensimmäistä käskyä eivät ehdi Write back-vaiheeseen, jossa niiden arvot kirjoitettaisiin kohderekistereihin, ennenkuin kolmas käsky tarvitsee niiden arvoja Decode-vaiheessa.
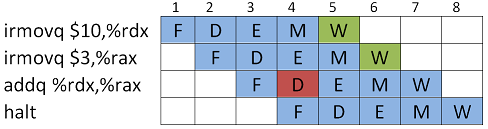
Data-hasardien selvittämiseksi on onneksi käytössä useita keinoja.
Viivyttäminen¶
Käskyn suoritusta voidaan viivyttää (engl. delay) lisäämällä väliin
nop-käskyjä, kunnes inputit ovat saatavilla. nop-käsky on tässä kätevä, koska se ei muuta suorittimen rekisterien sisältöjä mitenkään. 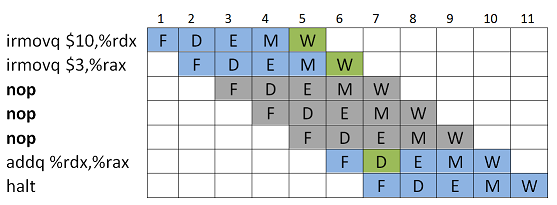
Lisäämällä väliin 3 nop-käskyä, saadaan kahden käskyn Write Back-vaiheet suoritettua ennenkuin arvoja tarvitaan kolmannen käskyn Decode-vaiheessa.
Stalling¶
Tässä käskyt jäävät kontrollilogiikan ohjaamana suorittamaan sen hetkistä vaihettaan, kunnes päästään etenemään. Tässä siis suoritetaan Decode-vaihetta (ja Fetch) kunnes inputit ovat saatavilla. Tämä voidaan tehdä jäädyttämällä PC-rekisteri ja lisäämällä ohjelmaan väliin bubbleja jotka säilyttävät liukuhihnarekisterien arvot. Erona on, ettei bubble välttämättä ole käsky, mutta usein bubble toteutetaan viemällä väliin nop-käskyjä.

Tässä inputit tarvittiin kellojaksolla 4, joten jäädytetään PC ja lisätään väliin bubble:ja alkaen kellojaksosta 5. Seurauksena on, että kaikki muutkin tätä seuraavat käskyt jäävät suorittamaan sen hetkistä vaihettaan, kunnes inputit saadaan kellojaksolle 7.
Forwarding¶
Haittana aiemmissa keinoissa on, että lisäämällä väliin tyhjiä käskyjä tai "tyhjäkäynnillä" suorittimen suorituskyky ei ole optimaalinen, vaan kellojaksoja hukataan.
Forwarding (tai bypassing) pääsee ongelmasta eroon siten, että kontrollilogiikka yhdistää edellisten käskyjen välitulokset nykyisen käskyn inputteihin. Toisinsanoen, jos käskyn inputtia ei ole vielä saatavilla, tarkistetaan olisiko tulos jossain liukuhihnalla jo laskettu. Tietenkin tämä voidaan tehdä vain saman kellonjakson aikana tarjolla oleville signaaleille ja seurauksena tästä kellojakson suoritusaika hieman pitenee.
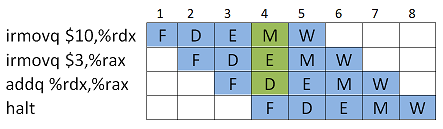
Kuvassa siis ensimmäisen ja toisen käskyn välitulokset kellojaksosta 4 on kytketty
addq-käskyn Decode-vaiheen input-signaaleiksi. Koska input-arvoja käytetään vasta Execute-vaiheessa, ne ehditään tässä kohti lukea. Load / Use-hasardi¶
Kun käsky tekee muistiosoituksia hakeakseen inputin rekisterikutsujen sijaan, voi syntyä load/use-hasardi.
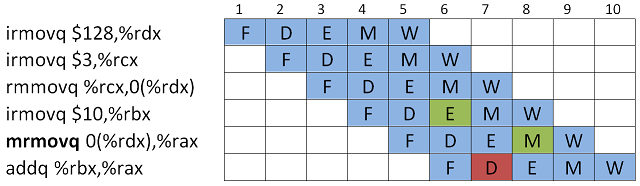
Nyt
addq-kutsulle ei saada asetettua molempia operandeja kellojaksossa 7. Neljännen käskyn (irmovq) output on jo saatavilla Execute'-vaiheen jälkeen, mutta viidennen käskyn output saadaan vasta Memory-vaiheen jälkeen. Tässä ei voi käyttää Forwarding'':ia, koska molempien inputit on saatavilla vasta 8. kellojaksossa. Ratkaisu on yhdistää Stalling ja Forwarding. Eli lisätään bubble ja
addq-käsky suorittaa Decode-vaihettaan, kunnes molemmat inputit on saatavilla Forwarding:iä varten. 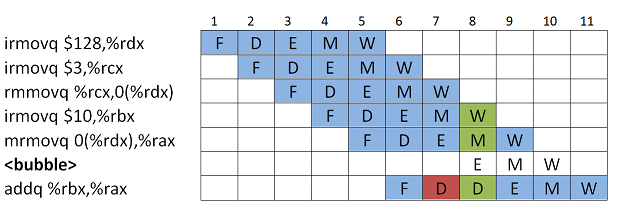
Liukuhihnan kontrollivirheet¶
Kontrolli-hasardi (engl. control hazard) tarkoittaa sitä, että käskyjen välillä on riippuvuuksia (engl. control dependency). Riippuvuus tässä tarkoittaa, että käskyn tulos vaikuttaa siihen, mistä koodin suoritusta jatketaan. Eli mikä on seuraavan käskyn muistiosoite.
Aliohjelmahasardi¶
Tarkastellaan
ret-kutsusta johtuvaa mahdollista hasardia koodiesimerkin kautta. call funktio
irmovq $10,%rdx
halt
funktio:
irmovq $3, %&rcx
ret
Alla ohjelman suoritus liukuhihnalla. Nyt, aliohjelmaan hypätään ja se suoritetaan, mutta paluuosoite on tiedossa vasta
ret-käskyn Write back-vaiheessa, kun se on haettu pinosta ja talletettu PC-rekisteriin.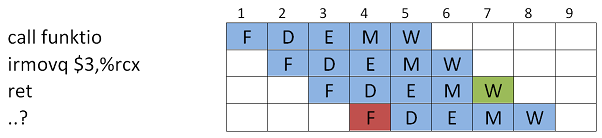
Ratkaisu tässäkin on lisätä väliin bubbleja, kunnes voidaan hyödyntää Forwarding:ia Fetch-vaiheeseen. Bubble tässä kuvaa sitä tilannetta, ettei suoritin voi tehdä yhtään mitään muuta kuin odottaa.
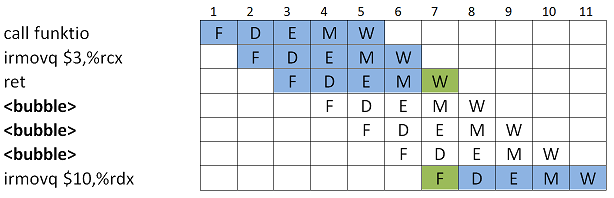
Ehdollinen hyppy¶
Ehdollinen hyppy on moderneissa suorittimissa toteutettu kahdella tavalla ennakoivasti. Voidaan ajatella, että ehdollinen hyppy toteutuu aina tai hyppy ei toteudu. Ongelma ennustamisessa on se, että riippuen ehdon tuloksesta saatetaan noutaa vääriä käskyjä jos ehdon tulos on eri kuin ennustettu.
Koodiesimerkki ehdollisesta hypystä y86:sessa.
0000: xorq %rax,%rax 0002: jne target # Oletus: hyppy toteutuu aina! 000b: irmovq $1,%rax 0015: halt 0016: target: 0016: irmopq $2,%rdx 0020: irmovq $3,%rbx 002a: ret
Ja koodin suoritus alla, nyt seuraavat (punaiset) käskyt on siis haettu oletuksen hyppy toteutuu aina mukaan. Oikea hyppyosoite selviää kuitenkin vasta käskyn Execute-vaiheessa.
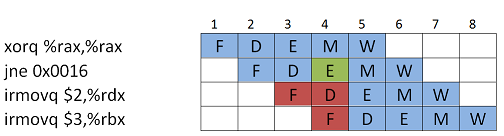
Ratkaisuna on poistaa liukuhihnalta väärät käskyt ja sitten lisätä bubble:ja tilalle.
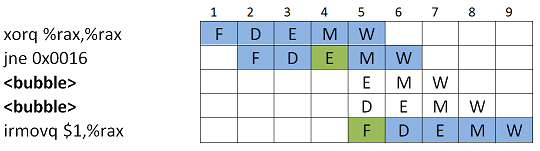
Hox! Oikeissa toteutuksissa bubble voidaan toteuttaa nop-käskyillä..
Käskyjen uudelleenjärjestely¶
Joskus on mahdollista suorittimen (tai ohjelmoijan..) muokata tai muuttaa lennosta ohjelman suoritusta niin, että
nop-käskyjen tai bubble:n tilalta suoritettaisiinkin tulossa olevia ohjelman käskyjä, joissa ei ole riippuvuuksia jumissa oleviin käskyihin. Kuten arvata saattaa, tämä vaatiikin jo varsin edistynyttä ohjausta..y86-liukuhihnatoteutus¶
Ok, hasardeista selvittyämme ymmärrämme (ja osaamme ehkä arvostaa..) y86-liukuhihnatoteutusta.
1. Fetch¶
Materiaalin ensimmäisessä kuvassa huomattiin, ettei liukuhihnasuorittimessa ole PC update-vaihetta. Liukuhihnatoteutuksessa se siiretään Fetch-vaiheeseen, jotta seuraavan käskyn osoite haettaisiin mahdollisimman myöhään. Yleisesti liukuhihnatoteutuksissa tarvitaan lisäksi muistiosoitteen ennustamista (engl. branch prediction) suorituskyvyn parantamiseksi. Tästä lisää myöhemmin..
Tämän vaiheen liukuhihnarekisteri on
F:pred_PC:- Jos käsky ei ole ehdollinen tai hyppy, seuraavan käskyn osoite on
valP:ssa. - Koska ehto toteutuu aina, tähän rekisteriin on tallentunut edellisessä käskyssä annettu osoite signaaleista
valCtaivalP. - Jos ehto ei toteudu, seuraava osoite saadaan edellisen käskyn signaaleista
valAtaivalMjoko Memory- tai Write Back-vaiheista (valitaan vastaavan icode:n ja cnd:n perusteella).
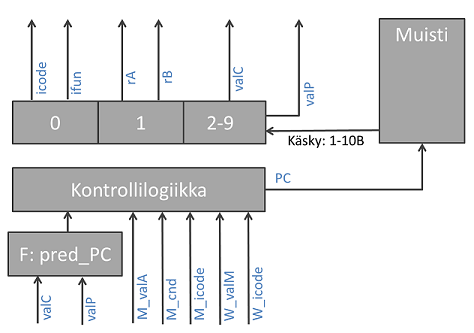
Etuliite
M_ tarkoittaa, että osoite tulee Memory-vaiheen käskyn signaalista ja W_ että osoite tulee Write back-vaiheesta. 2. Decode¶
Decode-vaihe on muuten sama kuin sekventiaalisessa prosessorissa, mutta kontrollilogiikassa on enemmän vaihtoehtoja signaaleille
valA, valB, joka mahdollistaa aiempien käskyjen tulosten vaiheista Execute, Memory ja Write back käyttämisen nykyisen käskyn operandeina. Kuvassa x_ viittaa johonkin aiempaan vaiheeseen E,M tai W. 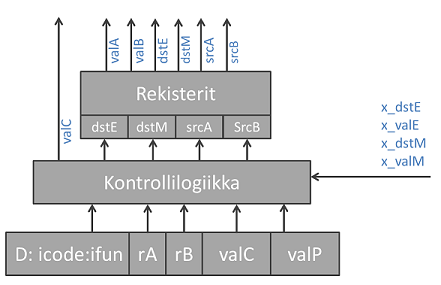
Ok, mutta mistä tiedetään mikä näistä signaaleista valitaan? y86-liukuhihnaprosessorissa on asetettu prioriteetti eri signaaleille ja sen mukaan valitaan arvo käskystä, jonka vaihe on lähinnä omaa vaihetta.
Esimerkiksi, jos tarjolla on arvot vaiheista Execute tai Memory, valitaan Execute-vaiheen käskyn signaalit, koska se on lähinnä omaa vaihetta Decode. Alla oleva koodi ei toimisi oikein, jos näin ei tehtäisi.
irmovq $10,%rdx # Vaiheessa M: -> M_valE = 10
irmovq $3,%rdx # Vaiheessa E: -> E_valE = 3
rrmovq %rdx,%rax # Vaiheessa D: valA <- E_valE = 3
3. Execute¶
Tämä vaihe on identtinen sekventiaalisen prosessorin kanssa. Huomataan kuitenkin, että ulos lähtee enemmän signaaleja, joita voidaan käyttää seuraavien käskyjen operandeina takaisinkytkennän kautta.
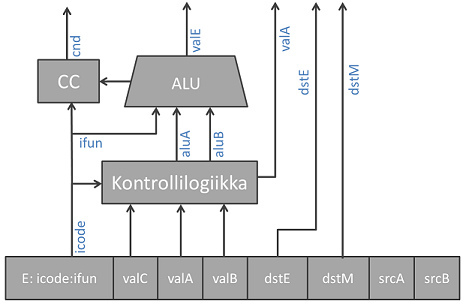
4. Memory¶
Vaihe on myös identtinen sekventiaalisen prosessorin kanssa ja ulos lähtee enemmän signaaleja seuraavien käskyjen operandeiksi.
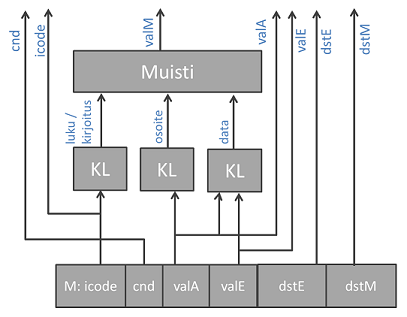
5. Write back¶
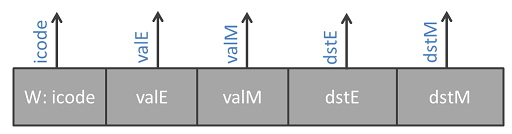
Vaihe on myös identtinen sekventiaalisen prosessorin kanssa ja ulos lähtee enemmän signaaleja seuraavien käskyjen operandeiksi.
Liukuhihnan suorituskyky¶
Liukuhihnaprosessorin suorituskyvylle voimme esittää kaksi laskennallista parametriä:
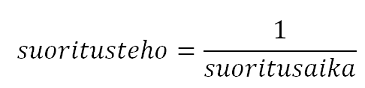
- Suoritusaika/latenssi (engl. latency), joka kertoo käskyn/osajärjestelmän suoritusajan, yksikkö nykyään pikosekunti (ps)
- Suoritusteho (engl. throughput), eli suoritettujen käskyjen määrä sekunnissa, yksikkö IPS (instructions per second)
Näiden avulla voimme laatia erilaisia liukuhihnaratkaisuja, joissa maksimoidaan suoritustehoa. Mikroarkkitehtuurissa voi suunnittelija jakaa käskyn suorituksen niin moneen vaiheeseen (teoriassa) kun on tarpeen ja viedä väliin niin monta liukuhintarekisteriä kun tarvitaan. Itseasiassa moderneissa suoritintoteutuksissa esimerkiksi on jo 18 vaihetta! Tällöin käskyn suoritusajassa pitää sitten ottaa huomioon lisääntyneen logiikan viive, jota kuvataan kirjoitusaika tulosrekisteriin/liukuhihnarekistereihin.
Alla esimerkkivertailu sekventiaalisen ja liukuhihnaprosessorin suoritustehon erosta.
1. Sekventiaalinen prosessori
1. Sekventiaalinen prosessori

- Latenssi: käskyn suoritusaika (300ps) + tuloksen kirjoittaminen tulosrekisteriin (20ps) = 320ps
- Suoritusteho: 1 / (320*10^-12) = 3,125 GIPS (giga-IPS)
2. Liukuhihnaprosessori, jossa käskyn suoritus jaettu kolmeen vaiheeseen.

- Latenssi: osajärjestelmän suoritusaika (kesto 100ps) + tuloksen kirjoittaminen liukuhihnarekisteriin (20ps) = 120ps
- Nyt kuitenkin koko käskyn suoritusaika on 3 x 120ps = 360ps
- Suoritusteho: 1 / (120*10^-12) = 8,333 GIPS
Nyt
8,333 GIPS / 3,125 GIPS = 2,67 , josta nähdään, että liukuhihnaprosessori oli huomattavasti suorituskykyisempi ohjelmien suorituksen kannalta, koska käskyjä saadaan ulos nopeammassa tahdissa, vaikka yksittäisen käskyn suoritusaika onkin pidempi: 360 / 320 = 1.125.Toteutuksia¶
Seuraavaksi tarkastellaan esimerkin vuoksi oikeita sekventiaali- ja liukuhihnatoteutuksia Intelin x86-arkkitehtuuriperheen eri prosessorisukupolvissa.
8088-prosessorissa (8-bittinen arkkitehtuuri) on sisäinen neljän käskyn mittainen käskyjono, josta käskyt siirretään sekventiaalisesti suoritettavaksi. Tällä tekniikalla pystytään vähentämään hitaita muistiosoituksia.
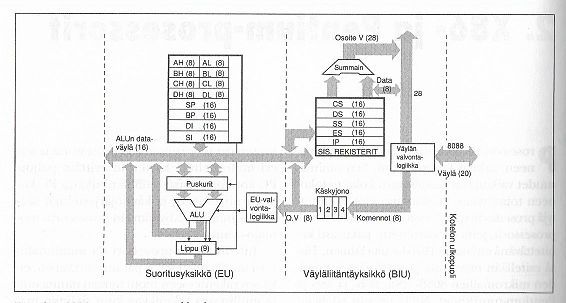
80286-prosessorissa (8/16-bittinen arkkitehtuuri) sisäiseen käskyjonoon haetaan automaattisesti aina kaksi tavua kerrallaan. Käskyt suoritetaan sekventiaalisesti. Jos haettu käsky on hyppykäsky, hylätään koko jono ja täytetään se uudelleen hyppykäskyn osoittamasta paikasta.
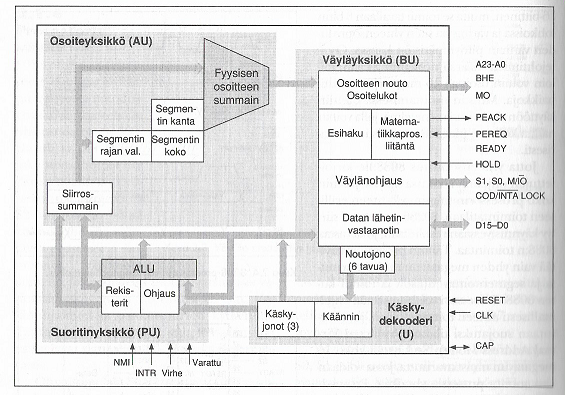
80386-prosessoreissa (32-bittinen arkkitehtuuri) toteutus perustui kaksivaiheeseen liukuhihnaan, eli seuraava käsky haetaan kun nykyistä ollaan suorittamassa. Hyppykäskyissä haettu seuraava käsky voidaan hylätä.
80486-prosessoreissa (32-bittinen arkkitehtuuri) yhden käskyn suorituksessa kuluu neljä kellojaksoa: käskyn nouto muistista, käskyn tulkitseminen (decode), operandin nouto muistista ja suoritus (execute). 486:sen liukuhihnassa taas on viisi vaihetta: käskyn nouto, käskyn tulkitseminen, muistiosoitteiden muodostus, suoritus ja takaisinkirjoitus (write back). 486:sessa oli myös suorittimeen integroitu matematiikkaprosessori liukulukulaskentaan, kun aiemmissa prosessorimalleissa se oli erillinen piiri samalla piirikortilla.
Pentium-prosessoreissa (alunperin 32-bittinen arkkitehtuuri) liukuhihnassa on viisi vaihetta, kuten 486:sessa. Pentium on itseasiassa superskalaaritekniikalla (tästä myöhemmin lisää..) toimiva prosessori, jolloin siinä on useita erillisiä mutta rinnakkaisia suoritusjonoja ja ALUja. Pentiumeissa on kaksi ALUa kokonaislukulaskentaan, joista toinen suoritti yksinkertaisia käskyjä (V-linja) ja toinen (U-linja) suoritti kaikkia käskyjä. Pentiumeissa on lisäksi liukulukulaskentaan oma matematiikkaprosessori, jolla on kahdeksanosainen liukuhihna. Näin ollen Pentiumissa itseasiassa on kolme eri tavoin liukuhihnoitettua ALUa!

Okei, esitetään lisää oikeita prosessoritoteutuksia myöhemmin..
Lopuksi¶
Liukuhihnatoteutuksista on siis merkittävästi hyötyä suorittimen suorituskyvylle, mutta hintana on yksittäisen käskyn suoritusajan piteneminen ja vaativampi mikroarkkitehtuurin toteutus.
Oikeissa suorittimissa (M)IPS ei ole kovin hyvä mittari suoritusteholle, koska se ilmoittaa parhaan mahdollisen tuloksen ja oikeita ohjelmia suorittaessa IPS vaihtelee. Eli keskimääräisesti se on jotain muuta kuin paras mahdollinen. Suorituskykyä tarkastelemme vielä lisää myöhemmässä materiaalissa..
Anna palautetta
Kommentteja materiaalista?