4. Materiaali: Tiedostavat sanakirjamoduulit¶
Viimeiset asiat ennen maailmanloppua¶
Viime materiaalissa pääsimme pisteeseen, jossa kykymme tuottaa ohjelmalogiikkaa saavutti rajapyykin, jossa monenlaiset ohjelman tulivat ainakin teoriassa mahdollisiksi. Olemme ottaneet haltuun muuttujat, funktiot, ehtorakenteet, tietorakenteet ja silmukat, sekä kourallisen perustietotyyppejä. Näiden lisäksi olemme tutustuneet erinäisiin suunnittelu- ja toteutusperiaatteisiin sekä oppineet käytäntöjä, joiden avulla koodaamiseen saa riittävästi selkeyttä. Viimeiset perusteet löytyvät tämän materiaalin tekstivirrasta. Enää ei puhuta niinkään ohjelmalogiikasta, vaan tavasta tehdä tiettyjä asioita. Tärkeimpänä asiana tässä materiaalissa on kuitenkin muiden työn hyödyntäminen.
Ohjelmoija ei ole koskaan yksin. Kuten jo alussa todettiin, pelkästään Pythonin mukana tulee ämpärikaupalla valmista koodia. Tämän lisäksi Internet on täynnä lisää vastaavia moduuleja, ja Pythonissa on jopa näiden asentamiseen sisäänrakennettu työkalu, jolla asennettiin jo aiemmin IPython. Tässä materiaalissa tutustumme joihinkin Pythonin sisäisiin moduuleihin sekä asennamme myös ulkopuolisen kirjaston.
Viimeistään tämä avaa ovet alkeista kohti ”oikeaa” ohjelmointia: valmiin koodin kautta pystyy pienellä vaivalla pakenemaan komentoriviohjelmista ikkunoituun käyttöliittymään tai verkkoon. Graafisiin käyttöliittymiin tarjotaan tällä kurssilla pintaraapaisu ja verkkoasiat jätetään oman kiinnostuksen varaan, mutta kaikki ne ovat pohjimmiltaan täysin samanlaista koodia kuin nämä alkeet. On hyvä muistaa, että ohjelmalogiikka ei juurikaan muutu, vaikka lopputulos näyttäisi hyvin erilaiselta.
Tässä materiaalissa perehdymme myös siihen miten Pythonilla voi käsitellä muita tiedostoja. Olkoonkin, että nykyään tiedostojen suora käpistely on varsin harvinaista, ja yleensä siitä vastaa jokin moduuli. Näiden moduulien toiminnan ymmärtämiseksi on kuitenkin hyvä käydä läpi, miten tiedostoja kirjoitetaan ja erityisesti luetaan ihan itse kirjoitetulla koodilla. Joissain tilanteissa myös ”tein itse ja säästin” -ratkaisu saattaa olla jouhevampi kuin mikään valmiina olemassaoleva – tai ainakin sopivampi juuri sinun miettimääsi tarkoitukseen.
Omien työkalujen tekeminen on myös hyvä syy oppia ohjelmoimaan. Vaikka kaikkeen olisi olemassa työkalu, usein itse tehty työkalu hoitaa asian sujuvammin. Tämä johtuu pitkälti juuri siitä, että kun työkalut tekee itse, niihin voi sisällyttää kaikki tehtäväkohtaiset yksityiskohdat – tehdä oletuksia, joita yleistä työkalua rakentaessa ei voi tehdä.
Listojen siivousta¶
Aloitetaan materiaali jatkamalla siitä mihin viime kerralla jäätiin. Kokoelmaohjelmaan jäi poiston ja muokkauksen mentävät aukot, ja itse asiassa pari muutakin joihin on tarkoitus perehtyä tällä kertaa. Keskeneräiset asiat on kuitenkin syytä hoitaa ensin, eli toteutetaan poistot ja muokkaukset.
Muistin virkistykseksi, tähän asti tapahtunutta:
Osaamistavoitteet: Miten listoista poistetaan alkioita ja mitä kommervenkkejä siihen liittyy. Miten listan alkioita voidaan muokata.
Listat laihiksella¶

Ohjelmassa on siis poista-
funktio
, joka ei tee mitään. Käyttöliittymästä kuitenkin kyseinen toiminto löytyy, joten olisi hyvä jos se myös tekisi jotain. Tätä tarkoitusta varten lienee syytä siis kurkistaa ensialkuun miten listoista ylipäätään poistetaan asioita. Alkioiden
poistamista varten listoilla
on remove-metodi
. Sen dokumentaatio kertoo seuraavaa:remove(...) method of builtins.list instance
L.remove(value) -> None -- remove first occurrence of value.
Raises ValueError if the value is not present.
Huomioita: poistaminen tapahtuu
arvon
perusteella; listasta poistetaan vain yksi kappale tätä arvoa, vaikka useampikin löytyisi. Kunhan arvo on täsmälleen sama, se poistetaan. Tämä toimii kohtalaisen helposti yksinkertaisia alkioita sisältäville listoille, mutta meidän ohjelmamme tapauksessa voi olla hieman liikaa vaatia käyttäjää syöttämään poistettavan levyn koko arkistoesitys (siis kokonainen sanakirja) - ja miten tämä oikeastaan edes onnistuisi merkkijonosyötteillä? Ehkä olisi inhimillisempää pyytää käyttäjää syöttämään
pelkästään poistettavan levyn ja sen artistin nimi (koska useilla artisteilla voi olla saman nimisiä levyjä, mutta samalla artistilla tyypillisesti ei, ellei haluta pitää kirjaa eri painoksista - mutta silloin niitä varten pitäisi olla oma kenttänsäkin). Eli jotakuinkin näin:Anna poistettavan levyn artisti: Mono Anna poistettavan levyn nimi: You Are There Levy poistettu
Tähän pääseminen vaatii hieman enemmän kuin pelkkää removea, mutta sen käytöstä on hyvä lähteä liikkeelle. Tarkastellaan siis seuraavaa koodipätkää, jollainen voisi löytyä vaikka jostain internetin persoonallisuustestin terminaaliversiosta (joka täysin autenttisesti antaa aina saman tuloksen):
viikko = ["maanantai", "tiistai", "keskiviikko", "torstai", "perjantai", "lauantai", "sunnuntai"]
print("Viikossa on seitsemän päivää:")
print(", ".join(viikko))
poisto = input("Minkä päivän haluat poistaa: ").lower()
viikko.remove(poisto)
print("Jätit viikkoosi seuraavat päivät:")
print(", ".join(viikko))
print("Tämä valinta on tyypillinen erityisesti paranormaaleista mielenhäiriöistä kärsiville yksilöille")
Koska removen dokumentaatiossa lukee, että se heittää
poikkeuksen
mikäli poistettavaksi tarkoitettua arvoa
ei löydy, tarvitaan tämän tyyppisessä käytössä try-rakenne:try:
viikko.remove(poisto)
except ValueError:
print("Päivää ei ole.")
print("Olemattomien päivien valinta on tyypillistä vainoharhaisille yksilöille")
else:
print("Jätit viikkoosi seuraavat päivät:")
print(", ".join(viikko))
print("Tämä valinta on tyypillinen erityisesti paranormaaleista mielenhäiriöistä kärsiville yksilöille")
Itse removen käyttö ei varsinaisesti ole mitään rakettitiedettä. Tarkalla arvolla poistaminen on kuitenkin vain yksi skenaario, ja usein halutaankin poistaa sellaisia
alkioita
, jotka täyttävät jonkin tietyn ehdon
. Tällöin tulee usein tarpeeseen käydä lista läpi for-silmukalla
, ja sopivia alkioita kohdattaessa poistaa ne. Samalla saadaan poistettua useampi kuin yksi esiintymä. Oppimateriaalin loputtomiin aaseihin kyllästynyt opiskelija kehitti seuraavan näköisen koodinpätkän, ja halusi varmuuden vuoksi poistaa kaikki a:lla alkavat eläimet.elukoita = ["koira", "kissa", "orava", "mursu", "aasi", "laama"]
for elain in elukoita:
if elain.startswith("a"):
elukoita.remove(elain)
print(", ".join(elukoita))
Sherlock de Bug ja sitkeän aasin arvoitus¶
Opittavat asiat: Opimme, että
listoista
alkioiden
poistaminen silmukassa ei ehkä olekaan aivan mutkatonta...Alustus:
Suoritamme saman koodin kuin aaseihin kyllästynyt opiskelija esimerkissä. Meillä on kuitenkin nyt käytössä uusi lista elukoista.
In [1]: elukoita = ["mursu", "apina", "aasi", "laama", "koala", "aropupu", "hirvi"]
In [2]: for elain in elukoita:
...: if elain.startswith("a"):
...: elukoita.remove(elain)
...:
In [3]: print(", ".join(elukoita))
Haettu vastaus:
Kopioi vastauslaatikkoon tulkin tulostama rivi.
 Anna palautetta
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?

Onko aaseissa sittenkin jotain erikoista? Ei sentään, mutta tämän koodinpätkän toiminnassa on. Ongelman ydin on se, että
silmukan
sisällä oleva koodi poistaa alkioita
listasta
, jota silmukka käy läpi. Läpikäynti etenee indeksistä
0 indeksiin N-1, missä N on listan pituus. Poistettaessa käy niin, että kaikkien poistettavan alkion jälkeisten alkioiden indeksit putoavat yhdellä. Läpikäytävä indeksi kasvaa jatkuvasti. Nämä kaksi tekijää yhdessä aiheuttavat sen, että osa listan alkioista hypätään yli. Kun poistetaan jotain indeksistä 2, indeksillä 3 ollut arvo putoaa indeksille 2, mutta läpikäynti jatkuu indeksiin 3 – eli siihen arvoon, joka oli aikaisemmin indeksissä 4. Alla havainnollistava animaatio.Animaatiossa on yksi pieni epätarkkuus:
silmukkamuuttuja
elain säilyttää poistetun arvon siihen asti, että siihen sijoitetaan
seuraavan kierroksen alussa uusi arvo. Lopputilanteessa siis elain-muuttujassa olisi tosiasiassa edelleen arvo
"aropupu". Tämä on jätetty animaatiosta pois siksi, että nykyisessä muodossaan animaatio demonstroi nimenomaan käsittelyssä olleen ongelman huomattavasti selkeämmin.Vian poistamiseksi onkin valittava
silmukassa
läpikäytäväksi listaksi
alkuperäisen sijaan sen kopio. Tällöin poistot alkuperäisestä listasta eivät vaikuta läpikäytävään listaan. Tämä saadaan aikaan hyvin pienellä muutoksella for-silmukan
määrittelyyn:for elain in elukoita[:]:
Uutuutena esiintyvä
[:] listan perässä on tutun asian uusi variaatio. Kyseessä on samanlainen listan leikkaus
kuin edellisen materiaalin lopussa, missä kaksoispisteen ympärillä oli vain numeroita ainakin toisella puolella. Koska nyt hakasuluissa on pelkkä kaksoispiste, otetaan listasta "osa", joka sisältää kaikki alkiot, mutta on alkuperäisen kopio. Tämä pieni muutos muuttaa koko silmukan toimintaa varsin merkittävällä tavalla:Tässäkään animaatiossa elain-muuttujan kohtalo ei aivan vastaa todellisuutta (oikeastihan sille jäisi lopussa arvoksi "hirvi"), mutta varsinainen demonstroitava asia kävi selväksi. Omassa levykatalogiohjelmassamme halusimme poistaa levyt, jotka vastaavat käyttäjän antamaa artistin nimi – levyn nimi -paria. Periaate on sama kuin eläinesimerkissä. Ainoastaan
ehtolause
silmukan
sisällä muuttuu hieman. Tässäkin on syytä käydä läpi alkuperäisen listan
kopiota siltä varalta, että poistettavia löytyy useampi kuin yksi.def poista(kokoelma):
print("Täytä poistettavan levyn nimi ja artistin nimi. Jätä levyn nimi tyhjäksi lopettaaksesi")
while True:
nimi = input("Anna poistettavan levyn nimi: ").lower()
if not nimi:
break
artisti = input("Anna poistettavan levyn artisti: ").lower()
for levy in kokoelma[:]:
if levy["artisti"].lower() == artisti and levy["albumi"].lower() == nimi:
kokoelma.remove(levy)
print("Levy poistettu")
Ehtolauseeseen ja syötteisiin on viljelty ylimääräistä lower-
metodia
, koska haluamme mieluiten tehdä vertailut välittämättä kirjainkoosta, mutta kuitenkin säilyttää itse kokoelmassa olevat nimet siinä muodossa, kuin ne on sinne alunperin kirjoitettu. Tästä funktiosta poistutaan vasta kun käyttäjä on poistanut kaikki haluamansa levyt. Testataan:Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [47:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Slipknot - Iowa (2001) [14] [1:06:24] -- paina enter jatkaaksesi tulostusta -- 11. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] Tee valintasi: p Täytä poistettavan levyn nimi ja artistin nimi. Jätä levyn nimi tyhjäksi lopettaaksesi Anna poistettavan levyn nimi: slipknot Anna poistettavan levyn artisti: iowa Levy poistettu Anna poistettavan levyn nimi: Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [47:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] Tee valintasi: q
Näin olemme saaneet kaikki perustoiminnot toteutettua. Ohjelma osaa nyt lisätä levyjä kokoelmaan, poistaa levyjä sekä tulostaa kokoelman sisällön.
Johdatus digitaalisiin suodattimiin¶
Suodattaminen on datan valmistelua käsittelyyn. Tavoitteena on tyypillisesti tehdä käsittelystä helpompaa, tai ylipäätään mahdollista. Yksi hyvin yksinkertainen suodatus on selkeiden virhearvojen poistaminen datasta. Siis sellaisten arvojen, jotka ovat vaikkapa useita kertaluokkia suurempia kuin odotetut mittausarvot. Tässä tehtävässä pääset tekemään funktion, joka toteuttaa tämän yksinkertaisen suodatusmenetelmän.
Opittavat asiat:
Alkioiden
poistaminen listasta
oikein silmukan
sisällä.Toteutettava funktio:
suodata_virhearvot- Parametrit:
- lista mittaustuloksista (lista, sisältää liukulukuarvoja)
- reuna-arvo (liukuluku)
Funktion kuuluu poistaa mittaustuloksista kaikki arvot, jotka ylittävät reuna-arvon. Huomaa, että funktiossa ei ole palautusta, joten poistojen tulee kohdistua suoraan parametrina saatuun mittaustuloslistaan.
Funktion testaaminen:
Voit testata funktion toimivuutta esimerkiksi seuraavanlaisella koodinpätkällä:
mittaukset = [12.2, 54.2, 42345.2, 23534.1, 55.7, 8982.4]
suodata_virhearvot(mittaukset, 8000)
print(mittaukset)
Esimerkit toiminnasta:
Annetulla pääohjelmalla pitäisi saada tulostukseksi:
[12.2, 54.2, 55.7]
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Muutostyö¶
Toisena tavoitteena olisi tehdä ohjelmasa puuttuva muokkaa-funktio, jotta huolimattomasti levyjä syöttänyt käyttäjä voi korjata virheensä jälkikäteen.
Listan
sisältöä voidaan muokata muuttamalla yksittäistä alkiota
. Tällöin tyypillisesti valitaan listasta muutettava alkio indeksillä osoittamalla
ja muutetaan sitä joko sijoittamalla
sen paikalle uusi arvo
tai, mikäli alkio on muuntuvaa
tyyppiä kuten lista, muuttamalla sitä esim. metodilla
. Tässä on jälleen keskeistä muistaa, että muuntuvat ja muuntumattomat
tietotyypit eroavat toisistaan merkittävästi. Aloitetaan tutkimukset listasta, joka sisältää merkkijonoja
:In [1]: elukoita = ["mursu", "apina", "aasi", "laama", "koala", "aropupu", "hirvi"]
Kenties helpoin asia on listan alkion korvaaminen uudella:
In [2]: elukoita[1] = "norsu"
In [3]: elukoita
Out[3]: ['mursu', 'norsu', 'aasi', 'laama', 'koala', 'aropupu', 'hirvi']
Ihan kuin
sanakirjojen
avainten
arvoja muokatessa, vasemmalla puolella osoitetaan, mihin kohtaan listaa halutaan laittaa uusi arvo vanhan tilalle, ja uusi arvo itsessään tulee sijoitusmerkin oikealle puolelle ihan kuten aiemminkin. Indeksiosoitus listaan on sijoitusmerkin vasemmalla puolella, joten se on kohde, mihin arvo sijoitetaan. Uuden arvon sijoittaminen vanhan paikalle on ainoa tapa muokata muuntumattomia alkioita listassa, kuten merkkijonoja. Tästä osoituksena:In [4]: elukoita[2].upper()
Out[4]: 'AASI'
In [5]: elukoita
Out[5]: ['mursu', 'norsu', 'aasi', 'laama', 'koala', 'aropupu', 'hirvi']
Merkkijonometodi palauttaa aina muutetun kopion alkuperäisestä ja jättää alkuperäisen arvon sellaiseksi, kuin se oli. Jos siis halutaan muuttaa nimenomaan listan sisällä olevaa "aasi"-arvoa, täytyy metodin palauttama arvo sijoittaa vanhan paikalle:
In [6]: elukoita[2] = elukoita[2].upper()
In [7]: elukoita
Out[7]: ['mursu', 'norsu', 'AASI', 'laama', 'koala', 'aropupu', 'hirvi']
Lisäksi vielä merkittävä huomio siitä miten
muuttujat
käyttäytyvät:In [8]: elain = elukoita[3]
In [9]: elain = "karhu"
In [10]: elukoita
Out[10]: ['mursu', 'norsu', 'AASI', 'laama', 'koala', 'aropupu', 'hirvi']
Tässä kohtaa on äärimmäisen tärkeää muistaa, että muuttuja on
viittaus
arvoon
. Alussa elain-muuttuja viittaa listan
sisällä olevaan arvoon "laama". Sillä hetkellä, kun elain-muuttujaan sijoitetaan jokin uusi arvo eli tässä tapauksessa "karhu", itse elain-muuttujan viittaus muuttuu, mutta elukoita-listan viittaus "laama"-arvoon ei muutu. Eli näiden kahden ainoa yhteys on se, että ne viittasivat hetkellisesti samaan arvoon.Jos meillä on lista, joka sisältää listoja, asiat toimivat vähän eri tavalla, koska listat ovat
muuntuvia
. Esimerkkilistassa on Blackjakin aloituskäsiä listassa.In [1]: kadet = [["A", "8"], ["5", "7"], ["3", "10"]]
Käden vaihtaminen toiseksi tapahtuu samalla tavalla kuin
merkkijonoja
sisältävän listan kohdalla:In [2]: kadet[2] = ["4", "8"]
In [3]: kadet
Out[3]: [['A', '8'], ['5', '7'], ['4', '8']]
Jos taas halutaan muokata yhtä
alkiota
metodilla
, esim. nostaa käteen yksi uusi kortti, sijoitusta ei tarvitse tehdä:In [4]: kadet[0].append("5")
In [5]: kadet
Out[5]: [['A', '8', '5'], ['5', '7'], ['4', '8']]
Tämä johtuu siitä, että
listat
ovat muuntuvia
arvoja, jolloin esimerkin ensimmäinen rivi muuttaa sisempää listaa suoraan. Sen sijaan kadet-listan sisällä olevat listat sisältävät merkkijonoja, joten niihin tietenkin pätevät samat säännöt kuin merkkijonoihin yleisesti. Jos siis kortti halutaan vaihtaa jostain kädestä toiseksi, pitää tehdä näin:In [6]: kadet[2][0] = "9"
In [7]: kadet
Out[7]: [['A', '8', '5'], ['5', '7'], ['9', '8']]
Tässä esitellään samalla uusi
syntaksi
: miten osoitetaan
listaan, joka on listan sisällä. Ensimmäisen osoituksen perässä on uudet hakasulut osoittamaan sisemmän listan alkioon. Ensimmäinen hakasulkuosoitus palauttaa sisemmän listan, joten toinen hakasulkuosoitus korvaa sisemmän listan ensimmäisen alkion
.Jos otetaa listan alkio
muuttujaan
ja sijoitetaan
samaan muuttujaan uusi arvo
, käy samoin kuin merkkijonojen
tapauksessa:In [8]: kasi = kadet[0]
In [9]: kasi = ["10", "5"]
In [10]: kadet
Out[10]: [['A', '8', '5'], ['5', '7'], ['9', '8']]
Sen sijaan jos otetaan sama muuttujaan sijoitus ja sovelletaan append-metodia muuttujaan:
In [11]: kasi = kadet[0]
In [12]: kasi.append("2")
In [13]: kadet
Out[13]: [['A', '8', '5', '2'], ['5', '7'], ['9', '8']]
Sherlock de Bug ja kolmannen asteen yhteys¶
Tässä tehtävässä tutustutaan kaksiulotteisten listojen (eli listojen, jotka sisältävät listoja) kopiointiin. Listojen kopiointihan todettiin aiemmin hyödylliseksi, kun listasta piti poistaa jotain silmukan sisällä. Tässä tehtävässä selviää miksi kaksiulotteisten listojen kopiointi aiemmin esitetyllä tavalla ei ehkä olekaan hyvä idea... Tarkoitus on herättää nälkää, jotta seuraava pätkä tulisi luettua ajatuksella.
Opittavat asiat: Mitä tapahtuu, kun muutetaan
listan
kopion sisällä olevaa listaa. Alustus:
Lähtötilanne
tulkissa
:In [1]: kadet = [["A", "8"], ["5", "7"], ["3", "10"]]
In [2]: kopio = kadet[:]
Tehdään kaksi asiaa. Ensin lisätään kopio-muuttujassa olevaan listaan uusi lista:
In [3]: kopio.append(["2", "9"])
Ennen kuin jatkat, kannattaa selvittää miltä kumpikin lista näyttää. Seuraavaksi muutetaan kopio-listan ensimmäisen listan ensimmäinen alkio A:sta kolmoseksi, eli:
In [4]: kopio[0][0] = "3"
Haettu vastaus:
Jotta pääset kunnolla ihmettelemään mitä tässä tapahtuu, haluamme kaiken kaikkiaan neljä riviä vastaukseen. Nämä rivit ovat (tässä järjestyksessä):
- kopio-listan sisältö appendin jälkeen
- kadet-listan sisältö appendin jälkeen
- kopio-listan sisältö kolmosen sijoittamisen jälkeen
- kadet-listan sisältö kolmosen sijoittamisen jälkeen
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Tehtävän tuloksille on täysin looginen selitys. Merkintä
kopio = kadet[:] luo kyllä uuden listan
, mutta tämä uusi lista sisältää viittaukset
samoihin muuntuviin
listoihin kuin alkuperäinen. Niinpä tätä listaa itseään koskevat muutokset (1. vaiheen append) muokkaavat ainoastaan tätä kopiota, mutta sen sisällä oleviin listoihin kohdistuvat muutokset muokkaavat salakavalasti sekä alkuperäistä että kopiota. Näistä sisällä olevista listoista ei ole olemassa kopioita, joten kaikki muutokset kohdistuvat aina siihen ainoaan olemassaolevaan, johon sekä alkuperäinen ulompi lista että sen kopio viittaavat. Tämä asia on syytä pitää mielessä erityisesti miinoja haravoidessa.Näillä tiedoilla varustettuna voimme hyökätä levykatalogiohjelmamme muokkaa-
funktion
kimppuun. Itse muokkaamisen toteuttamista suurempi haaste on oikeastaan muokattavan levyn ja kentän valinta. Valintaan voidaan käyttää samaa periaatetta kuin poistossa, eli käyttäjä syöttää
haluamansa levyn nimen ja artistin. Kopioidaan siis poista-funktion sisältö muokkaa-funktioon:def muokkaa(kokoelma):
print("Täytä poistettavan levyn nimi ja artistin nimi. Jätä levyn nimi tyhjäksi lopettaaksesi")
while True:
nimi = input("Anna poistettavan levyn nimi: ").lower()
if not nimi:
break
artisti = input("Anna poistettavan levyn artisti: ").lower()
for levy in kokoelma[:]:
if levy["artisti"].lower() == artisti and levy["albumi"].lower() == nimi:
kokoelma.remove(levy)
print("Levy poistettu")
Muokatessa tulee lisäksi kysyä, mitä kenttää halutaan muokata ja mikä sen uudeksi arvoksi tulee. Muutokset kohdistuvat siis for-silmukkaan. Samalla voidaan korvata print-kutsuista poistoon viittaavat sanat muokkaamiseen viittaavilla. Koska tämä koodi on pätevä hakukriteereihin sopivien levyjen etsintään, on yksittäisen levyn muokkaus parasta tehdä omassa funktiossaan. Kutsuttakoon sitä nimellä
muuta_kenttia. Vaihdetaan tämän kohta luotavan funktion kutsu ylemmän koodin remove-rivin paikalle:def muokkaa(kokoelma):
print("Täytä muutettavan levyn nimi ja artistin nimi. Jätä levyn nimi tyhjäksi lopettaaksesi")
while True:
nimi = input("Anna muutettavan levyn nimi: ").lower()
if not nimi:
break
artisti = input("Anna muutettavan levyn artisti: ").lower()
for levy in kokoelma[:]:
if levy["artisti"].lower() == artisti and levy["albumi"].lower() == nimi:
muuta_kenttia(levy)
print("Levyn tiedot muutettu")
Tässä tapauksessa on järkevämpää tehdä kaksi varsin saman näköistä funktiota. Vaikka erot funktioissa ovat suhteellisen pieniä, niitä on hankala tehdä siten, että funktiot korvattaisiin yhdellä yleisemmällä funktiolle, jolle erot välitettäisiin
parametrien
kautta. Jos ohjelma suunniteltaisiin hieman eri tavalla, voitaisiin tämäkin epäkohta tosin korjata. Esim. siten, että ensin suoritetaan levyn valinta yleisellä hakufunktiolla ja sen jälkeen valitaan levylle tehtävä operaatio.Toteutetaan kuitenkin sen sijaan varsinainen muuta_kenttia-funktio. Funktion tarkoituksena on siis yksittäisen kokoelmassa olevan levyn tietojen muuttaminen. Perinteiseen tapaan voimme hyödyntää
while-silmukkaa
, jossa käyttäjä valitsee muokattavia kenttiä yksitellen kunnes haluaa lopettaa:def muuta_kenttia(levy):
print("Nykyiset tiedot:")
print("{artisti}, {albumi}, {kpl_n}, {kesto}, {julkaisuvuosi}".format(**levy))
print("Valitse muutettava kenttä syöttämällä sen numero. Jätä tyhjäksi lopettaaksesi.")
print("1 - artisti")
print("2 - levyn nimi")
print("3 - kappaleiden määrä")
print("4 - levyn kesto")
print("5 - julkaisuvuosi")
while True:
kentta = input("Valitse kenttä (1-5): ")
if not kentta:
break
elif kentta == "1":
levy["artisti"] = input("Anna artistin nimi: ")
elif kentta == "2":
levy["albumi"] = input("Anna levyn nimi: ")
elif kentta == "3":
levy["kpl_n"] = kysy_luku("Anna kappaleiden määrä: ")
elif kentta == "4":
levy["kesto"] = kysy_aika("Anna levyn kesto: ")
elif kentta == "5":
levy["julkaisuvuosi"] = kysy_luku("Anna julkaisuvuosi: ")
else:
print("Kenttää ei ole olemassa")
Pääasiassa
funktio
on vanhan toistoa. Koska listamme sisältää muuntuvia
arvoja (sanakirjoja
), varsinaiset muutokset näkyvät ainoastaan sanakirjan avaimiin
sijoitteluna, mutta niiden tulokset heijastuvat suoraan kokoelmalistaan. Joudumme tekemään ehtorakenteeseen
haaran jokaiselle kentälle erikseen, koska kenttien hyväksymät arvot eroavat toisistaan. Esimerkkiajo toimivuuden osoittamiseksi:Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: m Täytä muutettavan levyn nimi ja artistin nimi. Jätä levyn nimi tyhjäksi lopettaaksesi Anna muutettavan levyn nimi: modern times Anna muutettavan levyn artisti: iu Nykyiset tiedot: IU, Modern Times, 13, 47:14, 2013 Valitse muutettava kenttä syöttämällä sen numero. Jätä tyhjäksi lopettaaksesi. 1 - artisti 2 - levyn nimi 3 - kappaleiden määrä 4 - levyn kesto 5 - julkaisuvuosi Valitse kenttä (1-5): 4 Anna levyn kesto: 32:14 Valitse kenttä (1-5): Levyn tiedot muutettu Anna muutettavan levyn nimi: Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [32:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Slipknot - Iowa (2001) [14] [1:06:24] -- paina enter jatkaaksesi tulostusta -- 11. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] Tee valintasi: q
Nyt kun edellisessä materiaalissa kaavaillut toiminnot on viimein saatu tehtyä loppuun, on aika siirtyä uusien haasteiden pariin.
Tiedostot avautuvat koodarille¶
Tiedosto: senkin laiska laama!
Koodari: o_o;
Koodari: o_o;
Aivan ensimmäisenä voimme korjata kaikkein huutavimman puutteen: kokoelmaa ei ole pystytty tallentamaan ohjelman suorituksen päättyessä eikä lataamaan käynnistettäessä. Kokoelman sisältö on toistaiseksi kirjoitettu suoraan koodiin, mutta tämä ei tietenkään ole kovin hyvää ohjelmointia. Parempi tietysti olisi tallentaa tiedot erilliseen tiedostoon.
Tätä varten pääsemme tutustumaan siihen miten Python käsittelee tekstitiedostoja. Prosessiin kuuluu kaksi vaihetta: tietojen kirjoittaminen tiedostoon ja niiden lukeminen sieltä. Koska kirjoittaminen on yksinkertaisempaa, aloitamme siitä. Alla on esitetty kokoelmaohjelman koodi, jota lähdetään nyt muokkaamaan.
Osaamistavoitteet: Tästä osiosta pitäisi jäädä käteen miten tiedostoja avataan, kirjoitetaan ja luetaan. Lisäksi mielen sopukoihin pitäisi jäädä hieman filosofiaa siitä, mitä mutkia tekstimuotoisen datan käsittelyyn liittyy.
Tiedostojen lyhyt filosofia¶
Esitetyssä koodissa tallenna_kokoelma-
funktio
on jätetty varsin lyhyeksi:def tallenna_kokoelma(kokoelma):
"""
Tallentaa kokoelman, joskus tulevaisuudessa.
"""
pass
Jatkossa tässä funktiossa tulisi siis oksentaa kokoelma-listan sisältö
tekstitiedostoon
siten, että se saadaan sieltä myöhemmin luettua. Tiedostoja käyttäessä oikeastaan suurin ongelma on sopivan tallennusformaatin
kehittäminen. Itse tallentaminen on hyvin yksinkertaista ja mekaanista.Kun tallennetaan
listaa
, joka sisältää sanakirjoja
, on tyypillistä tallentaa tiedostoon yksi rivi jokaista sanakirjaa kohden. Esimerkin tapauksessa siis yhden levyn tiedot ovat aina yhdellä rivillä tekstitiedostossa. Avaimia
ei siis tallenneta, ladatun datan palauttaminen oikeisiin avaimiin tehdään latausfunktiossa. Seuraava hyvin yleinen periaate on, että käytetään erotinta
, jolla listan sanakirjan arvot erotetaan toisistaan tekstitiedostossa. Aiemmin on tehty vastaavaa:Anna muutettava arvo ja yksikkö: 12 yd 12 yd on 10.97 m
Tässä siis erottimena oli välilyönti. Koska tietokoneelle on mahdotonta tietää mikä on erotinta ja mikä osa dataa, erotin pitää valita siten, ettei sitä voi esiintyä datassa. Hyvin tyypillinen erotin on pilkku, ja sitä käyttäville tiedostoille on jopa olemassa oma nimityksensä: CSV eli comma separated values. Jos katsomme millaista dataa meillä on, voidaan todeta, ettei siellä ainakaan vielä ole pilkkuja.
Riski on toki olemassa, koska musiikin maailmassa ei varsinaisesti ole mitään sääntöä etteikö artistin tai albumin nimessä saisi olla pilkkuja. Toisaalta sellaista
erotinta
ei olekaan, jota ei teoriassa voisi olla nimessä. Ennustamme, että tarpeeseen voi tulla jokin sofistikoituneempi tallennusmuoto
. Nykyiselle datalle kuitenkin kelpaa pilkulla erottaminen aivan hyvin. Sovitaan siis, että haluamme tuottaa kokoelmasta tämän näköisen tekstitiedoston:Alcest, Kodama, 6, 0:42:15, 2016 Canaan, A Calling to Weakness, 17, 1:11:17, 2002 Deftones, Gore, 11, 0:48:13, 2016 ...
Tätä formaattia voidaan helposti lukea käyttämällä pelkästään
merkkijonojen
split-metodia
. Kaikki mitä tekstitiedostosta luetaan, luetaan nimittäin merkkijonoksi. Koska tosielämässä ei ole käytännössä mitään takuuta etteikö mikä tahansa merkkijono voisi esiintyä artistin tai albumin nimessä, tarvittaisiin tallennusratkaisu, joka ei luota pelkästään splitin käyttöön. Jostain on silti lähdettävä liikkeelle.Avoin kirja¶
Tiedostot avataan open-
funktiolla
riippumatta siitä avataanko tiedosto kirjoittamista vai lukemista varten. Avattu tiedosto voidaan sijoittaa muuttujaan
. Tämä muuttuja toimii tiedostokahvana
, jota käytetään kuvainnollisesti tiedostoon tarttumiseen. Sen kautta voidaan siis lukea tai kirjoittaa.kahva = open("muntiedosto")
Avatessa open-funktiolle tulee kertoa avataanko tiedosto lukemista vai kirjoittamista varten. Jos tiedosto avataan lukemista varten, sen pitää olla olemassa; jos kirjoittamista varten, tiedosto luodaan kirjoitushetkellä, mikäli sitä ei vielä ollut. Kirjoitus
moodista
riippuen mahdollisesti olemassaoleva saman niminen tiedosto korvataan uudella, tai uusi data kirjoitetaan sen loppuun. Alla on esitetty kolme perustapaa käyttää open-funktiota:luku = open("aasi.txt")
korvaus = open("aasi.txt", "w")
lisays = open("aasi.txt", "a")
Tästä näemme, että lukumoodi on oletustoiminta. Kaksi muuta ovat w (write) ja a (append). Jälkimmäinen on nimenä tuttu listojen append-metodista, ja samalla tavalla se lisää jotain loppuun. Yleensä tiedostojen avaamista ei kuitenkaan esiinny koodissa yllä kuvatulla tavalla. Sen sijaan käytetään
with-lausetta
. Se näyttää tältä:with open("aasi.txt") as luku:
Tämän lauseen sisälle (sisennettynä) kirjoitetaan tiedostoa käsittelevät operaatiot. Käytettäessä with-lausetta,
muuttuja
johon tiedostokahva
sijoitetaan
löytyy as-avainsanan
oikealta puolelta. Vastaavasti sen vasemmalta puolelta löytyy tiedoston avaava koodinpätkä, tyypillisesti open-funktiokutsu.Etuna with-lauseessa on se, että kun sisällä olevat operaatiot on lopetettu – joko suoritettuna tai
poikkeuksen
vuoksi – Python huolehtii automaattisesti tiedoston sulkemisesta. Muuten jäisi koodarin vastuulle sulkea tiedosto käyttämällä close-metodia. Tällöin pitäisi erikseen tunnistaa kaikki tapaukset, jolloin tiedosto on suljettava.Sen lisäksi, että tiedosto on hyvä avata with-lauseessa, tulee myös ottaa huomioon mahdolliset poikkeukset tiedoston avaamisessa. Tätä käsittelemme seuraavassa tehtävässä.
Sherlock de Bug ja kadonneen tiedoston arvoitus¶
Tuttuun tapaan, jotta poikkeus voidaan ottaa kiinni, meidän täytyy ensin selvittää, mikä se on.
Opittavat asiat: Mikä
poikkeus
syntyy, jos avattavaa tiedostoa ei ole olemassa.Alustus:
Kokeile
tulkista
käsin Python-koodilla avata mikä tahansa tiedosto, josta tiedät, ettei sitä ole olemassa. Noin niin kuin esimerkiksi:In [1]: with open("tätätiedostoaeioleolemassa.null.void") as lahde:
...: print(lahde.read())
Jos jostain syystä tuon niminen tiedosto on olemassa, keksi jokin muu nimi...
Haettu vastaus:
Vastaukseen riittää poikkeuksen nimi. Nimi kannattaa painaa mieleen, koska sitä tarvitaan aika usein tiedostoja aukovissa ohjelmissa...
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Koska open-
funktiokutsu
, joka poikkeuksen heittää, on with
-lauseessa, koko komeus tulee laittaa try:n sisälle:try:
with open("aasi.txt") as luku:
sisalto = lue_tiedosto(luku)
except ??:
print("Tiedoston avaaminen epäonnistui")
Luonnollisesti esimerkissä ?? korvataan tehtävässä kysytyllä
poikkeuksella
. Normaalisti tiedoston avaava koodi näyttää aina tältä.Tiedot talteen¶
Nyt kun tiedämme kaiken tarpeellisen
tiedostojen
avaamisesta, voimme viimein kirjoittaa niihin jotain. Aloitetaan siis kirjoittamalla perusrakenne tallenna_kokoelma-funktioon:def tallenna_kokoelma(kokoelma, tiedosto):
try:
with open(tiedosto, "w") as kohde:
pass
except IOError:
print("Kohdetiedostoa ei voitu avata. Tallennus epäonnistui")
Vaivihkaa lisäsimme funktioon myös uuden
parametrin
. Ennakoimme tässä, että kenties jatkossa haluamme mahdollistaa mielivaltaisen kokoelman käsittelyn ja ylipäätään sen, että käyttäjä voi päättää, mistä tiedostosta kokoelma ladataan ja mihin se tallennetaan. Siksi on järkevää jo tässä vaiheessa käsitellä tiedoston nimeä muuttujana
, jotta koodia ei tarvitse myöhemmin muuttaa uudestaan, kun tallennettava tiedosto vaihtuu. Yleisesti ottaen, mitä vähemmän oletuksia tekee työkalufunktioita koodatessa, sen parempi.Olemme päässeet siihen pisteeseen, että enää tarvitsee korvata pass-komento koodilla, joka toteuttaa tiedostoon kirjoittamisen. Tiedostoon kirjoittamisessa ajatuksena on siis kirjoittaa yksi rivi jokaista kokoelma-
listan
alkiota
kohti. Vastaavanlaisen ongelmanmäärittelyn kohtasimme jo listasta tulostaessa. Ratkaisu voisi olla siis jälleen tuttu silmukka
:for levy in kokoelma:
Tiedostoon kirjoittaminen hoidetaan
tiedostokahvan
write-metodilla
, joka eroaa kahdella merkittävällä tavalla print-funktiosta
. Ensinnäkin, write ei suostu kirjoittamaan muuta kuin merkkijonoja
:In [1]: with open("aasi.txt", "w") as kohde:
...: kohde.write(5)
...:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-174567876ea2> in <module>()
1 with open("aasi.txt", "w") as kohde:
----> 2 kohde.write(5)
3
TypeError: write() argument must be str, not int
Tämä tarkoittaa sitä, että kaikki tiedostoon kirjoitettavat asiat täytyy muuttaa merkkijonoiksi valitulla tavalla. Yksinkertainen tapa on käyttää str-funktiota, mutta yleensä erittäin toimiva tapa on muotoilla koko tallennettava rivi yhdeksi merkkijonoksi
format-metodin
avulla. Tässäkin voidaan käyttää suoraan jo tuttua tapaa:for levy in kokoelma:
print(
f"{levy['artisti']}, {levy['albumi']}, {levy['kpl_n']}, "
f"{levy['kesto']}, {levy['julkaisuvuosi']}"
)
Nyt vain korvataan print tiedoston write-metodilla:
def tallenna_kokoelma(kokoelma, tiedosto):
try:
with open(tiedosto, "w") as kohde:
for levy in kokoelma:
kohde.write(
f"{levy['artisti']}, {levy['albumi']}, {levy['kpl_n']}, "
f"{levy['kesto']}, {levy['julkaisuvuosi']}"
)
except IOError:
print("Kohdetiedostoa ei voitu avata. Tallennus epäonnistui")
Valmista? Melkein.
Sherlock de Bug ja liimatut rivit¶
Kun asioita kirjoitetaan tiedostoon write-metodilla, sen toiminnassa on yksi huomioitava ero ruudulle tulostukseen nähden. Tässä tehtävässä eroa ei ole huomioitu, joten koodietsivä joutuu ihmettelemään outoja tuloksia.
Opittavat asiat: Mitä ilmaantuu tiedostoon kun write-
metodia
kutsutaan useita kertoja koodissa.Alustus:
Loihdi
tulkkiin
seuraavat rivit:In [1]: with open("bileet.txt", "w") as kohde:
...: kohde.write("aasi")
...: kohde.write("svengaa")
...:
Kiinnitä myös huomiota siihen mistä kansiosta avasit tulkin. Tämän jälkeen pitäisi nimittäin löytää tuo juuri luotu bileet.txt, ja se tulee löytymään juuri siitä kansiosta, josta tulkki käynnistettiin. Avaa tiedosto jollain järjellisellä tekstieditorilla ihmeteltäväksi.
Haettu vastaus:
Vastaukseen halutaan bileet.txt-tiedoston koko sisältö sellaisenaan kopioituna - ei enempää eikä vähempää.
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Huomataan, että write-metodi ei harrasta samanlaista taikuutta kuin print-funktio. Jälkimmäinen siis avuliaasti heittää aina tulosteen loppuun rivinvaihdon, mutta write ei tätä tee. Niinpä sellainen täytyy laittaa tulostettavaan
merkkijonoon
ihan itse – mutta miten? Kakkosmateriaalin asiat palaavat kummittelemaan. Siellä nähtiin aivan erityistä käyttöä \-merkille merkkijonojen sisällä:print("Tuuma (in tai \")")
Merkkiä kutsuttiin
pakomerkiksi
, ja sen merkitys oli, että sitä seuraava merkki tulkitaan tavallisesta poikkeavalla tavalla. Toistaiseksi käyttö on ollut sitä, että saadaan merkkijonon rikkova merkki sisällytettyä merkkijonoon puhtaana merkkinä. Se toimii kuitenkin myös toiseen suuntaan: kun pakomerkki laitetaan sopivan kirjaimen eteen, syntyy uusi merkitys. Kolme kohtalaisen yleistä ovat n, r ja t – mutta erityisesti n, joka tulee sanasta newline. Merkkijonossa siis \n tuottaa rivinvaihtomerkin. \t tuottaa sarkainmerkin ja \r on asioita, joista voi järkevä ihminen vain kysyä "miksi?"
.Ongelmaamme on siis helppo ratkaisu: lyödään yksi rivinvaihtomerkki merkkijonon perään:
def tallenna_kokoelma(kokoelma, tiedosto):
try:
with open(tiedosto, "w") as kohde:
for levy in kokoelma:
kohde.write(
f"{levy['artisti']}, {levy['albumi']}, {levy['kpl_n']}, "
f"{levy['kesto']}, {levy['julkaisuvuosi']}\n"
)
except IOError:
print("Kohdetiedostoa ei voitu avata. Tallennus epäonnistui")
Ja lopuksi lisätään tiedoston nimi
funktiokutsuun
toiseksi argumentiksi pääohjelmassa
:tallenna_kokoelma(kokoelma, "kokoelma.txt")
Tiedoston
päätteellä ei ole juurikaan merkitystä meille, mutta Windows tietenkin tykkää nuuskia, mitä ohjelmaa avaamiseen tulisi käyttää sen perusteella. Laitetaan .txt, niin Windows osaa avata tiedoston oletuksena tekstieditorilla. Nyt kokoelma saadaan tallennettua tiedostoon, kunhan vain kertaalleen avataan ja lopetetaan ohjelma.
Kuin pistäisi rahaa pankkiin¶
Jos tallennettavassa datassa esiintyy jokin merkki, kyseistä merkkiä ei ole yleensä järkevää käyttää tallennusmuodossa erottimena. Tässä tehtävässä pääset tutustumaan tällaiseen tapaukseen. Englanniksi kun käsitellään isoja lukuja, käytetään usein pilkkua tuhansien erottimena, esim. rahaa pyöriteltäessä: $10,930,698. Käytimme aiemmin pilkkua erottimena, mutta nyt se ei selkeästikään käy!
Opittavat asiat: Listassa olevien datarivein kirjoittaminen tiedostoon siten, että ne voidaan sieltä vielä myöhemmin lukea takaisin dataksi.
Tavoite: Funktio, joka kirjoittaa dataa tiedostoon.
Toteutettava funktio:
tallenna_summat- Parametrit:
- tallennettava data (lista, joka sisältää listoja, jotka sisältävät merkkijonoja)
- kohdetiedoston nimi (merkkijono)
Tallennettavat luvut tulevat listassa, joka sisältää listoja. Kussakin sisemmässä listassa on neljä
alkiota
– eli neljä esimerkissä kuvatussa muodossa olevaa rahasummaa. Tallenna tiedostoon kukin neljän rahasumman sarja omalle rivilleen. Käy parametrina saatu lista läpi for-silmukalla
kuten materiaaliesimerkeissä on tehty. Tällä kertaa lista vain sisältää listoja sanakirjojen sijaan.Yksittäisten rivien tallennukseen voi käyttää mm. merkkijonon
muotoilua
tai join-metodia
. Koska pilkku esiintyy luvuissa säännöllisesti, käytä riville tulevien summien erottimena
kaksoispistettä. Tiedosto pitää luonnollisesti avata ja sulkea funktion sisällä. Funktion testaaminen:
Voit kirjoittaa kooditiedostoosi seuraavat koodirivit
pääohjelmaksi
, jolloin voit testata funktiota omalla koneellasi. Koodinpätkästä näet myös esimerkin siitä miltä funktiolle annettavat argumentit
näyttävät. Yksi alkio kuvaa yhtä vuotta, jonka sisällä on jokaisen kvartaalin tulos.kvartaalitulokset = [
["$123,123,123", "$56,548", "$666,666,666,666", "$945,246,000"],
["$45", "$645,231", "$765,312,765", "$12,000,000,001"],
["$18,618,639", "$911", "$312", "$517,629,086"],
["$633,811", "$243,632,851,833,606", "$328,421,688,104", "$803"],
["$626", "$235,493,388", "$469,980", "$985,435,012,285,386"],
["$34,934", "$829,830,625,455", "$757,180,630,342,645", "$615,239"],
["$214,081", "$350,257", "$669", "$98,002,803,712,471"],
["$807,266,013,233", "$43,931,320,272,886", "$106,873,623,674", "$409,966"],
["$901", "$23,797,858,928,694", "$916", "$648,091,994,611"]
]
tallenna_summat(kvartaalitulokset, "kvartaalit_2001-2009.txt")
Esimerkit toiminnasta:
Yllä annetun pääohjelman suorituksen pitäisi toimivan funktion kanssa tallentaa tiedosto
kvartaalit_2001-2009.txt, jonka sisältö on seuraavanlainen:$123,123,123:$56,548:$666,666,666,666:$945,246,000 $45:$645,231:$765,312,765:$12,000,000,001 $18,618,639:$911:$312:$517,629,086 $633,811:$243,632,851,833,606:$328,421,688,104:$803 $626:$235,493,388:$469,980:$985,435,012,285,386 $34,934:$829,830,625,455:$757,180,630,342,645:$615,239 $214,081:$350,257:$669:$98,002,803,712,471 $807,266,013,233:$43,931,320,272,886:$106,873,623,674:$409,966 $901:$23,797,858,928,694:$916:$648,091,994,611
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Lukupiiri¶
Nyt kun kokoelma on onnistuneesti tallennettu, voidaan miettiä miten se saadaan luettua. Kuten jo aiemmin vihjattiin, split-
metodia
tullaan käyttämään. Toistaiseksi luotetaan siis siihen, että kokoelmaan ei sisälly nimiä, joissa esiintyisi pilkku. Tiedosto avataan tällä kertaa lukumoodissa, mutta muuten avaamisesta ja lukemisesta huolehtiva rakenne näyttää hyvin samanlaiselta:def lataa_kokoelma(tiedosto):
# Rivillä oleva järjestys vastaa seuraavia sanakirjan avaimia:
# 1. "artisti" - artisti nimi
# 2. "albumi" - levyn nimi
# 3. "kpl_n" - kappaleiden määrä
# 4. "kesto" - kesto
# 5. "julkaisuvuosi" - julkaisuvuosi
kokoelma = []
try:
with open(tiedosto) as lahde:
pass
except IOError:
print("Tiedoston avaaminen ei onnistunut. Aloitetaan tyhjällä kokoelmalla"
return kokoelma
Alussa kokoelma alustetaan tyhjäksi. Jos tiedostoa ei satu löytymään, saadaan tällä tavalla aloitettua tyhjä kokoelmalla palauttamalla tyhjä
lista
. Tähänkin funktioon
on lisätty tiedosto-parametri
, aiemmin mainituista syistä.Tiedostojen sisältöä luetaan pääasiassa kahdella eri
tiedostokahvan
metodilla
: read ja readlines. Näistä ensimmäinen lukee tiedoston koko sisällön yhdeksi merkkijonoksi
, kun taas jälkimmäinen antaa listan, jossa kukin tiedoston rivi on omana alkionaan
. Useimmissa tapauksissa jälkimmäinen on käytännöllisempi – erityisesti kaikissa sellaisissa tapauksissa, joissa yksi rivi vastaa yhtä datayksikköä. Jos siis käsiteltävänä on vaikka tämän näköinen tiedosto:Eeyore, depression Pooh, eating disorder Piglet, anxiety Rabbit, OCD Christopher Robin, schizophrenia Tigger, ADHD
Olkoon tiedosto nimeltään "puh.txt".
In [1]: with open("puh.txt") as puh:
...: sisalto = puh.read()
...:
In [2]: sisalto
Out[2]: 'Eeyore, depression\nPooh, eating disorder\nPiglet, anxiety\nRabbit, OCD\nChristopher Robin, schizophrenia\nTigger, ADHD'
In [3]: with open("puh.txt") as puh:
...: sisalto = puh.readlines()
...:
In [4]: sisalto
Out[4]:
['Eeyore, depression\n',
'Pooh, eating disorder\n',
'Piglet, anxiety\n',
'Rabbit, OCD\n',
'Christopher Robin, schizophrenia\n',
'Tigger, ADHD']
Rivinvaihdot lisätty tulostukseen jälkikäteen. Kuten mainostettua, ensimmäinen tuottaa yhden merkkijonon ja jälkimmäinen merkkijonoja sisältävän listan. Huomataan myös, että readlines-metodin lopputulos ei ole täysin sama kuin read-metodin tuottaman merkkijonon splittaaminen rivinvaihdon kohdalta:
In [5]: with open("puh.txt") as puh:
...: sisalto = puh.read().split("\n")
...:
In [6]: sisalto
Out[6]:
['Eeyore, depression',
'Pooh, eating disorder',
'Piglet, anxiety',
'Rabbit, OCD',
'Christopher Robin, schizophrenia',
'Tigger, ADHD']
Eli readlines jättää
rivinvaihtomerkit
paikoilleen. Ne on kuitenkin varsin helppo poistaa jälkikäsittelyssä strip-metodilla
, jolla voidaan samalla eliminoida ylimääräisiä välilyöntejä datasta.Kuten puhuttua, jatkokäsittely koostuu usein siitä, että rivit splitataan ennaltamäärätyn
erottimen
kohdalta, jolloin saadaan yksittäiset alkiot
. Nämä voidaan sitten siirtää kätevästi esim listaan
tai sanakirjaan
. Yleensä toimitaan siten, että readlines-metodin tulosta käytetään for-silmukan
läpikäytävänä sekvenssinä:with open("puh.txt") as puh:
for rivi in puh.readlines():
lue_rivi(rivi)
Usein vielä näitä yksittäisien rivien lukutuloksia kootaan johonkin listaan:
potilaat = []
with open("puh.txt") as puh:
for rivi in puh.readlines():
potilaat.append(lue_rivi(rivi))
Tämä on tyypillisin tapa lukea yksinkertaista, rivitettyä dataa tiedostosta takaisin ohjelman sisään listaksi. Tallentamisen ja lataamisen pointtina on juuri se, että ohjelma tallentaa sellaiset tiedot, joiden perusteella se pystyy palauttamaan sulkemisen aikaisen
tilansa
– tai käsittelemänsä datan tilan.Prosessi saattaa toki muuttua varsin monimutkaiseksi, jos mietitään vaikka miten pelit tallentavat tilansa – kuinka paljon tietoa täytyy tallentaa, jotta pelitilanne saadaan palautettua esim. jossain Skyrimin kaltaisessa massiivisessa avoimen maailman pelissä? Palataksemme kuitenkin tähän yksinkertaiseen tapaukseen, yllä esitetty koodi voidaan siirtää suoraan ohjelmaamme:
def lataa_kokoelma(tiedosto):
# Rivillä oleva järjestys vastaa seuraavia sanakirjan avaimia:
# 1. "artisti" - artisti nimi
# 2. "albumi" - levyn nimi
# 3. "kpl_n" - kappaleiden määrä
# 4. "kesto" - kesto
# 5. "julkaisuvuosi" - julkaisuvuosi
kokoelma = []
try:
with open(tiedosto) as lahde:
for rivi in lahde.readlines():
kokoelma.append(lue_rivi(rivi))
except IOError:
print("Tiedoston avaaminen ei onnistunut. Aloitetaan tyhjällä kokoelmalla")
return kokoelma
Tämä
funktio
jättää enää mysteeriksi sen miten yksittäiset rivit luetaan. Ongelma on siirretty lue_rivi-funktion toteutukseen.Ennen funktion toteutusta on hyvä selvittää hieman millaisia potentiaalisia ongelmia liittyy siihen kun tekstirivi luetaan
listaksi
splitin avulla. Pitkälti ongelmat ovat toisintoa viime materiaalista, kun splitattiin input-funktion antamia syötteitä
käyttäjältä.Tiedostoihin
voidaan tässä tapauksessa luottaa käyttäjän syötteitä enemmän, koska ainakin periaatteessa ne ovat saman ohjelman tuottamia kuin niitä lukeva ohjelma. On kuitenkin aina hyvä huomioida mahdollisuus, että joku sankari käy niitä käsin kopeloimassa.
Tarkoitus on siis päästä tästä:
"Agalloch, The Mantle, 9, 1:08:36, 2002\n"
tähän:
{
"artisti": "Agalloch",
"albumi": "The Mantle",
"kpl_n": 9,
"kesto": "1:08:36",
"julkaisuvuosi": 2002
}
Ajetaan prosessi läpi
tulkissa
, jotta välivaiheet jäävät hyvin näkyviin. Homma alkaa splitillä, koska ilman sitä ei ole mitään keinoa käsitellä pilkun erottamia merkkijonon
osia erikseen.In [1]: rivi = "Agalloch, The Mantle, 9, 1:08:36, 2002\n"
In [2]: osat = rivi.split(",")
In [3]: osat
Out[3]: ['Agalloch', ' The Mantle', ' 9', ' 1:08:36', ' 2002\n']
Tästä nähdään, että tallennusmuodossa käytetyt "hyvätapaiset" välilyönnit pilkkujen jälkeen aiheuttavat listan sisältöön ylimääräisiä välilyöntejä, joista tulisi hankkiutua eroon. Samalla kertaa on hyvä poistaa ylimääräinen \n.
In [4]: for i, osa in enumerate(osat):
...: osat[i] = osa.strip()
...:
In [5]: osat
Out[5]: ['Agalloch', 'The Mantle', '9', '1:08:36', '2002']
Tässä nähtiin myös uusi temppu: miten muokataan
silmukan
sisällä sellaisen listan
sisältöä, joka sisältää muuntumattomia
arvoja. Periaate on, että listasta otetaan silmukkamuuttujaan
sijoitetusta alkiosta
muutettu kopio ja sijoitetaan se alkuperäisen alkion päälle. Tämä täytyy tehdä sijoittamalla indeksiosoituksen
kautta - jos tuo rivi olisi osa = osa.strip(), luotaisiin erillinen osa-muuttuja, joka ei enää viittaisi samaan arvoon kuin osat[i].Olemme siis päässeet tähän asti:
['Agalloch', 'The Mantle', '9', '1:08:36', '2002']
Puuttuu enää kahden alkion muuttaminen kokonaisluvuiksi, joka tehdään suoraan listaan esimerkin yksinkertaisuuden nimissä. Periaatteessa tämän voisi tehdä myös siinä vaiheessa kun listan alkiot puretaan sanakirjaan.
In [8]: osat[2] = int(osat[2])
In [9]: osat[4] = int(osat[4])
In [10]: osat
Out[10]: ['Agalloch', 'The Mantle', 9, '1:08:36', 2002]
Listan
sanakirjaan
purkaminen tehdään vasta koodiesimerkissä. Kokonaisuutena prosessi ei ollutkaan ihan parin rivin temppu, joten tässä vaiheessa viimeistään alkaa hyvin näkyä, miksi se on aiheellista sijoittaa omaan funktioonsa. Sitten seuraakin hauskoista hauskoin ajatusleikki: mikä kaikki tässä voi mennä vikaan?Sherlock de Bug ja lukihäiriö, osa 1¶
Kaksiosaisessa bugidekkarissa selvittelemme miten kaikilla hienoilla tavoilla tiedoston lukeminen voi mennä pieleen. Aloitetaan tutkimukset tapauksesta, joka voi tällä hetkellä sattua pelkästään ohjelmaa aivan oikein käyttämällä. Paljon on puhuttu siitä mitä tapahtuu, jos nimissä on pilkkuja. Nyt saat tehtäväksi selvittää miten tarkalleen edellä kuvattu prosessi menee rikki, jos levyn nimessä esiintyy pilkkuja.
Opittavat asiat: Havaita minkä
poikkeuksen
ylimääräiset pilkut aiheuttavat tässä tapauksessa, sekä tunnistaa mikä lause
koodissa aiheuttaa ongelman. Alustus:
Ongelman aikaansaanti vaatii, että meillä on
muuttuja
, joka sisältää luettavan datarivin. Oikeasti rivi olisi luettu tiedostostosta, mutta tässä riittää, että kirjoitamme muuttujan sisällön suoraan: In [1]: rivi = "Canaan, Of Prisoners, Wandering Souls and Cruel Fears, 22, 1:41:06, 2012\n"
Tämän jälkeen voimme yrittää tehdä saman kuin edellä:
In [2]: osat = rivi.split(",")
In [3]: osat[2] = int(osat[2])
In [4]: osat[4] = int(osat[4])
Haettu vastaus:
Vastaukseen haetaan kahta asiaa, kukin omalle rivilleen ja annetussa järjestyksessä:
- mikä suoritetuista koodiriveistä aiheuttaa virheen - kopioi vastaukseen rivin sisältö yltä (ilman tulkkiväkäsiä)
- minkä niminen poikkeus ongelmasta syntyy
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Sherlock de Bug ja lukihäiriö, osa 2¶
Tutkimuksia ei kannata jättää yhteen tapaukseen. Seuraavaksi selvitetään mikä voi mennä vikaan, jos tiedostoa on editoitu käsin, ja sieltä saadaan käsittelyyn tämän näköinen rivi. Käyttäjä ei ole siis tiennyt albumin kestoa, ja on yrittänyt nokkelana lisätä albumin suoraan tiedostoon ilman tätä tietoa.
Opittavat asiat: Mitä tapahtuu, jos käsiteltävällä rivillä on liian vähän dataa.
Alustus:
Homman nimi on sama kuin yllä, eli määritellään rivi:
In [1]: rivi = "Void of Silence, The Grave of Civilization, 6, 2010\n"
Ja koitetaan suorittaa sama purkuprosessi:
In [2]: osat = rivi.split(",")
In [3]: osat[2] = int(osat[2])
In [4]: osat[4] = int(osat[4])
Haettu vastaus:
Vastaukseen haetaan jälleen kahta asiaa, eli:
- mikä suoritetuista koodiriveistä aiheuttaa virheen - kopioi vastaukseen rivin sisältö yltä (ilman tulkkiväkäsiä)
- minkä niminen poikkeus ongelmasta syntyy
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Ensimmäisen tehtävän näyttämä tapa selvittää, onko
listassa
liikaa alkioita
, ei ole järin hyvä. Parempi olisi huomata heti splitatessa, että tavaraa ei ole tarpeeksi tai sitä on liikaa. Tästä syystä voitaisiin oikeastaan splitata suoraan muuttujiin
. Tällöin ei tarvitse muistaa erikseen, mihin kenttään mikäkin indeksi viittaa.def lue_rivi(rivi):
try:
artisti, albumi, n, kesto, vuosi = rivi.split(",")
except ValueError:
print(f"Riviä ei saatu luettua: {rivi}")
Tässä ratkaisussa ei tietenkään voida tehdä aiemmin nähtyä
silmukkaa
, jossa käytettäisiin strip-metodia
. Toisaalta kaksi viidestä kentästä tarvitsee erikoiskäsittelyä stripin lisäksi, joten sillä, että jokainen muuttuja käsitellään erikseen ei kauheasti hävitä. Muutenkin arvot pitäisi sijoittaa sanakirjaan
, joka onnistuu kaikkein helpoiten tässä kohdassa. Tehdään tämä tällä kertaa siten, että luodaan uusi sanakirja käyttäen arvoina muuttujista johdettuja arvoja.def lue_rivi(rivi):
try:
artisti, albumi, n, kesto, vuosi = rivi.split(",")
levy = {
"artisti": artisti.strip(),
"albumi": albumi.strip(),
"kpl_n": int(n),
"kesto": kesto.strip(),
"julkaisuvuosi": int(vuosi)
}
except ValueError:
print(f"Riviä ei saatu luettue: {rivi}")
Sattumoisin ValueError on
poikkeus
, joka syntyy splitin purkamisesta väärällä määrällä arvoja kuin myös int-funktiokutsusta
, joten yksi except riittää. Huomataan myös, että int-funktiota ei kiinnosta jos merkkijonon sisältä löytyy tyhjää tarkoittavia merkkejä (siis välilyönti, sarkain, rivinvaihto).Jäljelle jää enää sanakirjan
palauttaminen
funktiosta ja sen miettiminen, miten ohjelma käyttäytyy, jos riviä ei saada luettua. Toistaiseksi ainoastaan tulostetaan virheilmoituksen kera se rivi, jonka lukeminen tuotti ongelmia. Jollain tapaa pitäisi kuitenkin kertoa myös lataa_kokoelma-funktiolle, että tätä epäonnistunutta riviä ei tulisi lisätä kokoelmaan.Vaihtoehtoja on ainakin kolme:
- lue_rivi voi palauttaa arvon, joka kertoo ongelmasta, ja lataa_kokoelma voi tarkistaa ehtolauseellaonko palautettu arvo tämä poikkeusarvo vai oikea sanakirja
- lue_rivi voi jättää ValueError-poikkeuksen käsittelemättä, ja sen käsittely voidaan siirtää lataa_kokoelma-funktioon
- kokoelma voidaan antaa toisena argumenttinalue_rivi-funktiolle, jolloin lisääminen on sen harkinnan varassa.
Näistä kaikki ovat täysin hyvätapaisia keinoja, ja valinta riippuu monesta tekijästä. Tällä kertaa valitaan viimeinen, joten muutetaan lue_rivi-funktiota:
def lue_rivi(rivi, kokoelma):
try:
artisti, albumi, n, kesto, vuosi = rivi.split(",")
levy = {
"artisti": artisti.strip(),
"albumi": albumi.strip(),
"kpl_n": int(n),
"kesto": kesto.strip(),
"julkaisuvuosi": int(vuosi)
}
kokoelma.append(levy)
except ValueError:
print(f"Riviä ei saatu luettue: {rivi}")
Mitään ei tarvitse
palauttaa
, koska lisäys listaan
tehdään tässä funktiossa
. Muutetaan lataa_kokoelma-funktiota siten, että se antaa lue_rivi-funktiota kutsuessaan funktiolle toisenkin argumentin:def lataa_kokoelma(tiedosto):
# Rivillä oleva järjestys vastaa seuraavia sanakirjan avaimia:
# 1. "artisti" - artisti nimi
# 2. "albumi" - levyn nimi
# 3. "kpl_n" - kappaleiden määrä
# 4. "kesto" - kesto
# 5. "julkaisuvuosi" - julkaisuvuosi
kokoelma = []
try:
with open(tiedosto) as lahde:
for rivi in lahde.readlines():
lue_rivi(rivi, kokoelma)
except IOError:
print("Tiedoston avaaminen ei onnistunut. Aloitetaan tyhjällä kokoelmalla")
return kokoelma
Lisätään vielä
pääohjelmaan
lataa_kokoelma-funktion vaatima argumentti:kokoelma = lataa_kokoelma("kokoelma.txt")
Kokeillaan:
Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [47:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Slipknot - Iowa (2001) [14] [1:06:24] -- paina enter jatkaaksesi tulostusta -- 11. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] Tee valintasi: l Täytä lisättävän levyn tiedot. Jätä levyn nimi tyhjäksi lopettaaksesi Levyn nimi: All Around Us Artistin nimi: Miaou Kappaleiden lukumäärä: 10 Kesto: 59:39 Julkaisuvuosi: 2008 Levyn nimi: Tee valintasi: q
Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [47:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Slipknot - Iowa (2001) [14] [1:06:24] -- paina enter jatkaaksesi tulostusta -- 11. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] 12. Miaou - All Around Us (2008) [10] [59:39] Tee valintasi: q
Lisätty levy on ilmestynyt kokoelman loppuun, koska missään välissä ei järjestetty kokoelmaa uudestaan. Ainakin näemme nyt helposti, että muutokset ovat säilyneet suoritusten välillä.
Tähän päätämme tiedostojen lukemista käsittelevän osion. Periaatteessa niiden lukemiseen ja tallentamiseen liittyy jos jonkinlaisia kommervenkkejä, mutta mitä vaikeammalta homma alkaa näyttää, sitä todennäköisemmin kannattaa siirtyä tein-itse-ja-säästin -ratkaisusta johonkin valmiiseen, jossa kaikenlaiset poikkeustilanteet on jo Jonkun Muun (tm) toimesta otettu huomioon.
Tuloksellisia tiedostoja¶
Useimmiten tiedostoista luetaan dataa tietorakenteisiin, koska niille halutaan tehdä jotain muutakin kuin vain tulostaa rivien sisältö sellaisenaan. Tätä operaatiota kutsutaan yleensä datan parsimiseksi. Tässä tehtävässä pääset tutustumaan yksinkertaiseen jälkikäsittelyyn, joka vaatii, että tiedoston sisältö on tietorakenteessa. Tehtävässä on myös yksi miina. Olemme tarkoituksella jättäneet kertomatta mikä se on, koska itse huomaamalla tai siihen astumalla muistat toivon mukaan jatkossa paremmin välttää sen.
Opittavat asiat: Datan lukeminen tiedostosta Python-
tietorakenteeseen
ja sen hyvin yksinkertainen jatkokäsittely. Lisäksi kohtaamme hyvin konkreettisesti yhden tiedostoihin liittyvän ominaisuuden.Tavoite: Funktio, joka lukee dataa tiedostosta ja tulostaa sen eri muodossa.
Toteutettava funktio:
nayta_tulokset- Parametrit:
- luettavan tiedoston nimi (merkkijono)
Funktio lukee tiedostoa, jossa on kullakin datarivillä seuraavat tiedot, tässä järjestyksessä:
pelaajan 1 nimi, pelaajan 2 nimi, pelaajan 1 pisteet, pelaajan 2 pisteet
Jotta rivien ulkoasua voidaan muokata tulostusta varten, ne täytyy lukea
listaksi
. Tässä apuna on hyvä käyttää merkkijonojen metodeja
. Uusi tulostusjärjestys onnistuu vaikkapa indeksiosoitusta
käyttämällä. Tulostus on muotoa: pelaaja pisteet - pisteet pelaaja
Jossa tietenkin kummallakin puolen viivaa on eri pelaajan pisteet. Tarkempia esimerkkejä löydät alempaa. Kaikki rivit voidaan olettaa virheettömiksi, eli virheentarkistusta ei tarvita.
Tiedosto tulee luonnollisesti avata funktion sisällä.
Funktion testaaminen:
Voit testata koodiasi seuraavan osion esimerkkitiedostolla kun laitat pääohjelmaksi seuraavan rivin:
nayta_tulokset("hemulicup.csv")
Esimerkit toiminnasta:
Alla annetun esimerkkitiedoston lukemisen pitäisi tuottaa seuraava
Hemuli 13 - 4 Muumipappa Abbath 6 - 6 Fenriz
Tiedoston sisältö (vaihda tallentaessa pääte .csv:ksi!)
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Jonkun Toisen Ongelma¶
Tosielämän koodauksessa harvemmin tehdään tallennusratkaisuja näin alusta alkaen. Riippuen ohjelman luonteesta sekä tallennettavan datan määrästä käytetään joko jotain valmista työkalua tallentamiseen tai tietokantaa. Pelkästään Pythonin sisäänrakennetuissa moduuleissa löytyy useampi ratkaisu, joilla dataa voidaan tallentaa ohjelman suoritusten välissä. Ehkä yksinkertaisin näistä on csv, joka tallentaa dataa pilkulla erotetuille riveille - siis käytännössä valmis versio siitä mitä yritimme tehdä. Ohjelmaamme sopii kuitenkin paremmin JSON (JavaScript Object Notation), jota käytetään mm. webbipalvelujen välisessä viestinvälityksessä ja sovellusten konfiguraatiotiedostoissa. Pythonissa on myös pickle, jolla Python-objekteja voidaan tallentaa ajojen välissä. Se on kuitenkin vähemmän yleistettävä ratkaisu, siinä missä JSONia voi käsitellä kielellä kuin kielellä.

Osaamistavoitteet: Nähdä miten helppoa Pythonin json-moduulilla on tallentaa kokoelmatyyppistä dataa. Lisäksi selvitetään miten
komentoriviargumenteilla
voi määrittää ohjelmalle asetuksia käynnistyksen yhteydessä.JSON lyhyesti¶
Peruskäyttö on äärimmäisen yksinkertaista. JSON-muotoinen datatiedosto saadaan aikaan Pythonin tietorakenteita syövällä dump-funktiolla, ja ladataan load-funktiolla:
In [1]: import json
In [2]: mittaus_1 = {
...: "pvm": "2014-08-03",
...: "paikka": "aasinsilta",
...: "tulokset": [12.54, 6.35, 20.38, 13.76, 45.51],
...: "kommentti": "aasit on painavia"
...: }
...:
In [3]: with open("mittaus.json", "w") as kohde:
...: json.dump(mittaus_1, kohde)
...:
Tuottaa tiedoston:
{"pvm": "2014-08-03", "tulokset": [12.54, 6.35, 20.38, 13.76, 45.51], "kommentti": "aasit on painavia", "paikka": "aasinsilta"}
ja se voidaan ladata yhtä helposti:
In [4]: with open("mittaus.json") as lahde:
...: mittaus_1 = json.load(lahde)
...:
In [5]: mittaus_1
Out[5]:
{'pvm': '2014-08-03',
'tulokset': [12.54, 6.35, 20.38, 13.76, 45.51],
'kommentti': 'aasit on painavia',
'paikka': 'aasinsilta'}
Jos tätä sovelletaan nykyiseen kokoelmaohjelmaan, havaitaan, että lataus ja tallennus yksinkertaistuvat "hieman". JSON-formaatin perusrajoitus on, että dokumentti voi sisältää vain yhden objektin. Tämä ei tosin haittaa, koska se yksi voi olla
lista
, joka voi sisältää sanakirjoja
tai muita listoja jne. Kaikessa yksinkertaisuudessa voidaan siis muuttaa tallennusfunktio tähän muotoon:def tallenna_kokoelma(kokoelma, tiedosto):
try:
with open(tiedosto, "w") as kohde:
json.dump(kokoelma, kohde)
except IOError:
print("Kohdetiedostoa ei voitu avata. Tallennus epäonnistui")
Tässä vaiheessa vaihdetaan myös pääohjelman lopussa oleva tallennuskutsu siten, että vaihdetaan kohde uudeksi:
tallenna_kokoelma(kokoelma, "kokoelma.json")
Ajetaan koodi kerran, jotta saadaan data ladattua vanhalla mekanismilla ja tallennettua uudella. Sen jälkeen voidaan tehdä latausfunktio:
def lataa_kokoelma(tiedosto):
try:
with open(tiedosto) as lahde:
kokoelma = json.load(lahde)
except (IOError, json.JSONDecodeError):
print("Tiedoston avaaminen ei onnistunut. Aloitetaan tyhjällä kokoelmalla")
return kokoelma
Huomaa, että lue_rivi-funktio on poistunut käytöstä. Tämä on niitä hetkiä kun pääsee tuntemaan itsensä vähän aasiksi: toteutettiin ensin vaivalla (puutteellinen) latausratkaisu, ja sitten huomataan, että valmista moduulia käyttämällä koko homma hoituu kahdella koodirivillä. Oikeastaan ainoa huomion arvoinen asia tässä on exceptiin lisätty toinen poikkeus:
json.JSONDecodeError. Kyseessä on siis json-moduulissa määritetty poikkeus, joka syntyy mikäli ladattava tiedosto ei ole JSON-syntaksin mukainen. Vaihdetaan myös pääohjelman latausfunktio käyttämään JSON-tiedostoa, ja voidaan testaamalla osoittaa, että pilkut nimissä eivät enää tuota ongelmia.Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: l Täytä lisättävän levyn tiedot. Jätä levyn nimi tyhjäksi lopettaaksesi Levyn nimi: Black Tar Prophecies Volumes 4, 5 & 6 Artistin nimi: Grails Kappaleiden lukumäärä: 12 Kesto: 50:36 Julkaisuvuosi: 2013 Levyn nimi: Tee valintasi: q
Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista: (L)isää uusia levyjä (M)uokkaa levyjä (P)oista levyjä (J)ärjestä kokoelma (T)ulosta kokoelma (Q)uittaa Tee valintasi: t 1. Alcest - Kodama (2016) [6] [42:15] 2. Canaan - A Calling to Weakness (2002) [17] [1:11:17] 3. Deftones - Gore (2016) [11] [48:13] 4. Funeralium - Deceived Idealism (2013) [6] [1:28:22] 5. IU - Modern Times (2013) [13] [47:14] -- paina enter jatkaaksesi tulostusta -- 6. Mono - You Are There (2006) [6] [1:00:01] 7. Panopticon - Roads to the North (2014) [8] [1:11:07] 8. PassCode - Clarity (2019) [13] [49:27] 9. Scandal - Hello World (2014) [13] [53:22] 10. Slipknot - Iowa (2001) [14] [1:06:24] -- paina enter jatkaaksesi tulostusta -- 11. Wolves in the Throne Room - Thrice Woven (2017) [5] [42:19] 12. Miaou - All Around Us (2008) [10] [59:39] 13. Grails - Black Tar Prophecies Volumes 4, 5 & 6 (2013) [12] [50:36]
Argumentti paremman käytettävyyden puolesta¶
Ainakin kertaalleen on puhuttu siitäkin, että ohjelman miellyttävyyden kannalta olisi mukavaa, jos käyttäjä voisi itse määritellä ohjelmaa käynnistäessä tai suorituksen aikana mistä tiedostosta kokoelma ladataan ja mihin se tallennetaan. Tallennus- ja lataus-
funktiomme
on suunniteltu jo valmiiksi tätä varten, mutta varsinainen sijainnin kysyminen puuttuu vielä ohjelmasta. Tämä voitaisiin tehdä tuttuun tapaan input-funktion avulla, mutta on olemassa myös toinen tapa antaa ohjelmalle lisäohjeita. Siinä missä input-funktiota käytetään tyypillisesti suorituksen aikana, seuraavaksi katsomme miten ohjelmalle voi antaa lisäohjeita käynnistyksen yhteydessä. Meillä kokoelma ladataan ja tallennetaan vastaavasti käynnistyksen alussa ja sammutuksen loppussa. Voisi siis olla loogista, että ladattava kokoelma määritetään käynnistyksen yhteydessä.Tähänkin löytyy vastaus
moduuleista
. Tällä kertaa napataan apuun sys-moduuli, jota käytetään kaikenlaiseen hieman syvällisempään kommunikointiin tietokoneen käyttöjärjestelmän kanssa. Raaputamme vain hieman pintaa, sillä käytämme sieltä vain yhtä ominaisuutta – joka ei ole edes funktio. Ominaisuuden nimi on argv, joka on lyhenne sanoista argument vector. Se sisältää ohjelman käynnistämiseen käytetyt argumentit
. Käynnistämiseenhän käytetään tyypillisesti komentoa tyyliin:ipython kokoelma.py
Tässä rivissä
ipython on ajettava komento, ja kokoelma.py on sen ensimmäinen ja ainoa argumentti. Asia ei kuitenkaan jää tähän: ohjelmille voi antaa lisää argumentteja – itse asiassa mielivaltaisen määrän. Niiden käsittely on ohjelman vastuulla. Eli periaatteessa voitaisiin käynnistää ohjelma vaikka kirjoittamalla hiukan lisää tavaraa:ipython kokoelma.py aasi svengaa dibadii dabadaa
Koska ohjelmamme ei millään tavalla reagoi ylimääräisiin argumentteihin, tämä ei aiheuta minkäänlaista muutosta toiminnassa. Se, mitä haluaisimme tehdä on tämän näköinen käyttötilanne:
ipython kokoelma.py kokoelma.json
Eli käyttäjä antaa kokoelmatiedoston
nimen
argumenttina. Mahdollisesti voitaisiin tehdä vielä niin, että mikäli käyttäjä haluaa tallentaa kokoelman eri tiedostoon kuin mistä lataa sen, voisi käyttäjä laittaa ylimääräisen argumentin, jossa on kohdetiedosto:ipython kokoelma.py kokoelma.json kopio.json
Argumenttivektoria on hieman hankala demonstroida interaktiivisessa tulkissa, joten tehdään sitä varten hyvin pieni tiedosto:
C:\polku\johonkin>ipython arg.py aasi svengaa "dibadii dabadaa" ['arg.py', 'aasi', 'svengaa', 'dibadii dabadaa']
Josta helposti nähdään että argumenttivektori on itse asiassa ihan tavallinen
lista
, joka sisältää merkkijonoja
. Nähdään myös, että normaalisti arvot erotetaan toisistaan välilyönnin perusteella, mutta lainausmerkkien sisällä olevat välilyönnit tulkitaan pelkästään välilyöntimerkeiksi. Koska tiedoston nimi välitetään lataa_kokoelma-funktiolle merkkijonona, sen poimiminen listasta ei pitäisi olla meille tässä vaiheessa suurikaan haaste. Sen sijaan argumenttivektorille saattaa joutua tekemään hieman virheenkäsittelyä ja tarvittaessa ohjeistaa käyttäjää. Tätä varten on parasta tehdä jälleen uusi funktio
:def lue_argumentit(argumentit):
pass
Funktion tulisi siis
palauttaa
kaksi tiedostonnimeä
: tiedosto, josta kokoelma ladataan ja tiedosto johon se tallennetaan. Mikäli tallennustiedostoa ei ole määritelty, käytetään lataustiedostoa myös tallennustiedostona. Tapaus on aika yksinkertainen: jos argumentteja
löytyy kolme, sieltä pitäisi löytyä molemmat tiedostot; jos niitä on kaksi, on määritetty vain lataustiedosto; jos niitä on yksi (eli pelkkä ohjelman nimi), käyttäjä ei ole antanut tarpeeksi informaatiota ja ohjelmaa ei voida suorittaa. Funktio palauttaa aina kaksi arvoa. Arvot jätetään tyhjiksi (None), jos funktion suoritus epäonnistuu. Tällöin pääohjelma voi paluuarvosta tarkistaa löytyikö tiedoston nimiä argumenteista.def lue_argumentit(argumentit):
if len(argumentit) >= 3:
lahde = argumentit[1]
kohde = argumentit[2]
return lahde, kohde
elif len(argumentit) == 2:
lahde = argumentit[1]
return lahde, lahde
else:
return None, None
Vastaavasti
pääohjelmaa
muokataan hieman:lahde, kohde = lue_argumentit(sys.argv)
if lahde:
valikko(lahde, kohde)
else:
print("Ohjelman käyttö:")
print("python kokoelma.py lahdetiedosto (kohdetiedosto)")
Alkuun pitää myös lisätä uusi
import
:import json
import math
import sys
Samalla siirretään edellinen pääohjelma valikko-funktioon, jotta sitä ei tarvitse laittaa tuon yhden if-lauseen sisälle kaikkine kilkkeineen.
def valikko(lahdetiedosto, kohdetiedosto):
kokoelma = lataa_kokoelma(lahdetiedosto)
print("Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista:")
print("(L)isää uusia levyjä")
print("(M)uokkaa levyjä")
print("(P)oista levyjä")
print("(J)ärjestä kokoelma")
print("(T)ulosta kokoelma")
print("(Q)uittaa")
while True:
valinta = input("Tee valintasi: ").strip().lower()
if valinta == "l":
lisaa(kokoelma)
elif valinta == "m":
muokkaa(kokoelma)
elif valinta == "p":
poista(kokoelma)
elif valinta == "j":
jarjesta(kokoelma)
elif valinta == "t":
tulosta(kokoelma)
elif valinta == "q":
break
else:
print("Valitsemaasi toimintoa ei ole olemassa")
tallenna_kokoelma(kokoelma, kohdetiedosto)
Tämä uusi jako mahdollistaa myös aiemin esitellyn nätin käsittelyn Ctrl+C:n painamiselle:
lahde, kohde = lue_argumentit(sys.argv)
if lahde:
try:
valikko(lahde, kohde)
except KeyboardInterrupt:
print("Ohjelma keskeytettiin, kokoelmaa ei tallennettu")
else:
print("Ohjelman käyttö:")
print("python kokoelma.py lähdetiedosto (kohdetiedosto)")
Kun koko valikko-funktiokutsu laitetaan tällä tavalla try:n sisään, painoi käyttäjä Ctrl+C:tä missä tahansa vaiheessa, tapahtuu siisti
komentoriville
palaaminen. Jälleen vaihtoehtona olisi, että try:n alle laitettaisiin kaikki valikko-funktiossa oleva koodi. Voinemme kuitenkin olla samaa mieltä, että tämä ratkaisu näyttää selkeästi elegantimmalta. Tässä vaiheessa voidaan jälleen ihastella ohjelmaa kokonaisuutena.Mikäli tarvitsee monimutkaisempaa komentoriviargumenttien käsittelyä, pelkkä sys.argv:n käpistely käsin alkaa nopeasti käydä työstä. Tällöin on syytä tutustua vaikkapa argparse-moduuliin.
Kolmannen asteen ratkaisut¶
Ennen pitkää tulee vastaan tilanne, jossa ei pääse enää eteenpäin pelkästään Pythonin sisältä löytyvillä
moduuleilla
. Teoriassa niillä on toki mahdollista tehdä kaikkea maan ja taivaan väliltä, mutta monet asiat ovat kovin työläitä erityisesti ottaen huomioon sen, että joku on sen työn todennäköisesti jo kertaalleen tehnyt. Tässä materiaalin osiossa tutustumme lyhyesti niin sanottuihin kolmansien osapuolien tekemiin moduuleihin, joista löytyy ratkaisu jotakuinkin mihin tahansa vähänkään yleisempään ongelmaan. Käymme ulkopuolisten moduulien käyttöä läpi lisäämällä viimeisen ominaisuuden kokoelma-ohjelmaamme.Kuka jaksaa kirjoittaa käsin levykokoelmansa tiedot johonkin ohjelmaan? Varsinkin kun nykyaikana on todennäköistä, että niiden levyjen sisältö löytyy myös koneelta musiikkikirjastona (tai sitten ei, koska Spotify, mutta mihinpä tätä ohjelmaakaan silloin tarvii...). Luonnollisesti olisi siis varsin järkevää, jos ohjelma osaisi lukea musiikkikirjaston sisällön ja muodostaa kokoelman sitä kautta. Jos kokoelma on hyvin järjestetty, voidaan aika helposti pelkästään Pythonin sisäisiä moduuleja käyttämällä kirjoittaa
funktiot
, jotka parsivat koneelta löytyvien levyjen nimet ja artistit hakemistojen nimistä. Myös kappaleiden määrät voi lukea laskemalla levyhakemistossa olevat musiikkitiedostot, ja mahdollisesti julkaisuvuosikin löytyy osana hakemiston nimeä. Mutta entäs ne kestot? Musiikkitiedostoista tämä kyllä löytyy metadatasta, mutta miten siihen pääsee käsiksi?Yksi vaihtoehto on tietenkin opiskella tiedostoformaatin spesifikaatiosta miten metadataa voi lukea, mutta toinen vaihtoehto on asentaa sopiva moduuli, joka on tarkoitettu tähän.
Tämä osio on hieman enemmän esimerkkihenkinen aikaisempiin verrattuna, eikä jokaista koodissa tehtyä ratkaisua selitetä kauhean tarkkaan. Niistä voi kysyä sähköpostilla, chatissa tai harjoituksissa jos jää kaivelemaan. Pääpaino on esitellä miten muiden tekemiä moduuleja otetaan käyttöön ja miten tehdään omia moduuleja, joita muutkin voisivat teoriassa käyttää.
Osaamistavoitteet: Tämän osion jälkeen tiedät mistä Python-paketteja kannattaa haeskella ja miten niitä asennetaan. Lisäbonuksena näemme hieman kiintolevyn sisällön tonkimiseen sopivaa esimerkkikoodia sekä teemme oman moduulin.
Paketteja internetin ihmemaasta¶
Kuten tavallista, ihan mitä tahansa roskaa ei koneelleen kannata asentaa eikä ihan miten sattuu. Oletuspaikka, josta Python-moduuleja eli paketteja kannattaa etsiä on Python Package Index eli PyPI. PyPI on Python Software Foundationin ylläpitämä sivusto, joten sen voidaan olettaa olevan varsin luotettava lähde. Lisäksi kaikki PyPIssä olevat paketit voidaan asentaa Pythonin mukana tulevalla asennusskriptillä, joka toimii samalla tavalla alustalla kuin alustalla, ja sitä käytettiin jo kurssin alussa IPythonin asentamiseen. Paketteja ei tarvitse siis erikseen latailla verkkoselaimella ja asentaa itse. Kirjoitetaan vain sopiva haku hakukenttään, kuten "mp3 tag read", mikä tuottaa nipun tuloksia. Tuloksien kuvauksista voi päätellä, että muutamakin paketti voisi sopia meidän tarkoitukseemme. Mistä sitten tietää mikä on sopivin? Yleensä paketin dokumentaatio tai koodiesimerkit auttavat asiassa.
Tällä kertaa valitaan tinytag, koska sen etusivulla on suoraan käyttöesimerkit ja se näyttää niiden perusteella yksinkertaiselta käyttää. Lisäksi se on selkeästi elossa oleva projekti, koska viimeisin päivitys on (tätä päivittäessä, eli 2020 keväällä) samalta kuukaudelta. Se tukee vain tagien lukemista, mutta tämä on meidän ohjelmamme kannalta täysin riittävää. Lisenssi on MIT, joka myös sopii meille, koska se sallii vapaan käytön. Nämä kaikki ovat tekijöitä, jotka tulee ottaa huomioon sopivaa Python-pakettia valitessa. Omiin tarkoituksiin yleensä riittää jotakuinkin mikä tahansa joka toimii eikä ole vahingollinen.
PyPIssä olevat paketit voi asentaa pip-skriptillä, joka tulee Pythonin mukana. Valitsemamme tinytag-paketin sivulla näkyy sille yksinkertainen käyttöohje:
pip install tinytag
Joka siis kirjoitetaan terminaaliin.
C:\joku\kansio>pip install tinytag Collecting tinytag Using cached https://files.pythonhosted.org/packages/74/cb/844151777ec728692b7 1bced33db355d6f889cf612f949325b2d2b62657c/tinytag-1.3.1.tar.gz Installing collected packages: tinytag Running setup.py install for tinytag ... done Successfully installed tinytag-1.3.1
Skriptin ajaminen tarvitsee kirjoitusoikeudet Pythonin kansioon – mikäli käyttäjälläsi ei ole niitä, komento pitää ajaa admin-oikeuksilla varustetussa komentorivikehotteessa. Kurkkaa ohjeet esitehtävistä ja ohjeista jos olet unohtanut. Tämän asennuksen jälkeen moduuli voidaan importata Pythonissa ihan kuin mikä tahansa Pythonin oma moduuli. Kovin kummoisesta hommasta ei siis ollut kyse. Jäljelle jää vielä koodin kirjoittaminen tätä pakettia apuna käyttäen.
Mikäli käytät Linuxia on kuitenkin parasta ensin tarkistaa mikä on jakelusi suositeltu tapa Python-pakettien hallintaan. Mikäli et pysty hankkimaan tarvittavia oikeuksia asentamiseen, voit tutustua virtuaaliympäristöjen käyttämiseen. Virtuaaliympäristöt ovat ylipäätään erittäin hyvä tapa omaksua Python-ohjelmien kehittämisessä. Niihin tutustuminen on kuitenkin jälleen aika kaukana alkeista, joskaan ei kovin pitkä oppitunti.
Nuuskintamoduuli¶
Nyt kun meillä on uusi hieno työkalu, sitä pitää tietenkin päästä käyttämään. Tehdään tätä varten kokonaan uusi
kooditiedosto
, joka voidaan sitten linkittää ohjelmaamme. Tuleepa samalla tämäkin prosessi tutuksi. Annettakoon tiedostolle nimeksi vaikka nuuskija.py. Aloitetaan parilla tyhjällä funktiolla
ja yhdellä importilla
:import tinytag
def lue_kansio(kansio):
pass
def lue_tiedot(tiedosto, kokoelma):
pass
Näistä lue_tiedot on se funktio, joka lukee yksittäisen tiedoston metadatasta asioita. Koko ohjelma etenee siten, että se aloittaa määritetystä kansiosta, ja etenee kaikkiin sen alikansioihin (ja niiden alikansioihin), tutkien kaikki musiikkitiedostot. Aina kun löydetään uusi levy (uusi artisti+albumi-kombinaatio), luodaan uusi
sanakirja
ja lisätään se listaan
. Tämä vastaa aiemmin nähtyä kokoelma-listan rakennetta. Musiikkitiedoston metadatasta voidaan lukea julkaisuvuosi. Lopulta sanakirjaan lisätään uusi avain: "kestot". Tämä tulee olemaan lista, johon lisätään kaikkien levylle kuuluvien yksittäisten kappaleiden kestot. Haun päätyttyä tästä tiedosta lasketaan levyn kokonaiskesto, ja alkioiden
lukumäärästä kappaleiden lukumäärä.Aloitetaan toteutus yksittäisen tiedoston lukemisesta, jotta pääsemme tutustumaan uuteen leluumme. Dokumentaation mukaisesti tagi saadaan luettavaksi seuraavan näköisellä koodirivillä:
tag = TinyTag.get('/some/music.mp3')
Tosin koska olemme käyttäneet normaalia
importia
from-importin sijaan, meillä esimerkki näyttäisi tältä:tag = tinytag.TinyTag.get('/some/music.mp3')
Meidän kohdallamme musiikkitiedoston sijainti ja nimi tulee funktioon tiedosto-
parametrina
. Tiedot voidaan siis lukea seuraavanlaisesti:def lue_tiedot(tiedosto, kokoelma):
tiedot = tinytag.TinyTag.get(tiedosto)
albumi = tiedot.album
artisti = tiedot.artist
vuosi = tiedot.year
kesto = tiedot.duration
Koska emme ole vielä testanneet tekeekö tinytag mitä odotamme, ja mitä se tarkalleen antaa ulos, tässä vaiheessa on hyvä kokeilla heittää hieman testitulostuksia koodiin:
print(artisti)
print(albumi)
print(vuosi)
print(kesto)
Ja tehdään lyhyt
pääohjelma
, joka kutsuu funktiota
että näemme mitä tapahtuu. Jos haluat testata omalla koneellasi, tarvitset luonnollisesti ainakin yhden musiikkitiedoston testattavaksi. Huomioi, että tiedosto-argumentissa
tulee olla tiedoston absoluuttinen
tai relatiivinen
polku
kokonaisuudessaan, jotta tiedosto löytyy. Tässä esimerkissä on absoluuttinen polku ulkoiseen asemaan Windowsissa. Kokoelma voi olla tässä tyhjä lista, koska sille ei vielä tehdä mitään funktiossa.lue_tiedot("E:/Music/Encore Show/Scandal - 10 - Cute!.mp3", [])
Joka antaa tämän näköisen tuloksen:
Scandal Encore Show 2013 272.6661224489796
Tämä kertoo kaksi asiaa: 1) tinytag toimii odotetulla tavalla, eli saamme tiedot kaivettua; ja 2) kappaleen kesto annetaan sekunteina, mikä kyllä lukee paketin dokumentaatiossakin. Nyt kun olemme testanneet, että todellakin saamme tiedot esiin, voimme poistaa testitulostukset funktiosta (testikoodin voi jättää pääohjelmaan toistaiseksi). Seuraavaksi tarvitaan tuttu koodinpätkä, joka etsii löytyykö levyä kokoelmasta:
for levy in kokoelma:
if levy["artisti"].lower() == artisti.lower() and levy["albumi"].lower() == albumi.lower():
Tämä käy pidemmän päälle raskaaksi, koska se täytyy toistaa jokaiselle löydetylle tiedostolle. Tämä voi kokoelma kasvaessa tehdä koko prosessin suoritusajasta hyvin pitkän. Ei kuitenkaan huolehdita siitä nyt – koodia ei koskaan kannata lähteä optimoimaan jos ei ole pakko – varsinkin kun itse tagin lukeminen kesti myös hetken. Suorituskyky ei siis välttämättä tule olemaan erityisemmin tästä
silmukasta
kiinni. Mikäli levy siis jo löytyy kokoelmasta, lisätään vain sen "kestot"-avaimeen uusi alkio: for levy in kokoelma:
if levy["artisti"].lower() == artisti.lower() and levy["albumi"].lower() == albumi.lower():
levy["kestot"].append(kesto)
break
Mikäli levyä ei vielä ole merkitty kokoelmaan, se pitäisi sinne lisätä. Koska tuossa silmukan sisällä olevassa
ehtolauseessa
ei vielä voida todeta että levyä ei lyötynyt (koska kaikkia ei ole vielä välttämättä käyty läpi), siihen ei voida liitää else-haaraa. Sen sijaan voidaan käyttää jälleen uutta temppua, eli for-silmukan
else-osaa. Tämä on harvemmin käyttöä näkevä, mutta juuri tähän tilanteeseen sopiva ominaisuus. Silmukoiden else-osa on sellainen johon mennään mikäli silmukka suoritetaan loppuun asti ilman keskeytystä (esim. break
tai return silmukan sisällä). Jos siis lisätään tässä olevaan silmukkaan else-osa, se tarkoittaa sitä, että siellä oleva koodi suoritetaan jos ja vain jos mikään kokoelmassa ollut levy ei sopinut silmukan sisällä olevaan ehtolauseeseen. for levy in kokoelma:
if levy["artisti"].lower() == artisti.lower() and levy["albumi"].lower() == albumi.lower():
levy["kestot"].append(kesto)
break
else:
kokoelma.append({
"artisti": artisti,
"albumi": albumi,
"kestot": [kesto],
"julkaisuvuosi": vuosi
})
Tässä vaiheessa siis kokoelmaan lisättävillä levyillä ei ole vielä kenttiä kesto ja n, koska niitä ei voida vielä tietää. Toimintaa voitaisiin jälleen testata. Lisätään pääohjelmaan rivi, joka tulostaa kokoelman funktiokutsun jälkeen:
kokoelma = []
lue_tiedot("E:/Music/Aura/Saor - 01 - Children of the Mist.mp3", kokoelma)
print(kokoelma)
Ja suorittamalla nähdään, että lisäys on tapahtunut:
[{'vuosi': '2014', 'artisti': 'Saor', 'albumi': 'Aura', 'kestot': [733.4138775510204]}]
Testataan samalla toimiiko kestojen lisääminen listaan ottamalla samalta levyltä toinen kappale:
kokoelma = []
lue_tiedot("E:/Music/Aura/Saor - 01 - Children of the Mist.mp3", kokoelma)
lue_tiedot("E:/Music/Aura/Saor - 02 - Aura.mp3", kokoelma)
print(kokoelma)
Tämäkin osoittautuu toimivaksi:
[{'vuosi': '2014', 'artisti': 'Saor', 'albumi': 'Aura', 'kestot': [733.4138775510204, 817.1885714285714]}]
Tässä vaiheessa voimme siis todeta, että tämä funktio toimii odotetulla tavalla. Siihen ei tarvi toivon mukaan siis enää koskea, ellei toimintaa haluta muuttaa jatkossa, tai siitä paljastu joitain yllättäviä
bugeja
kun testataan oikealla datalla eikä pelkästään parilla testitapauksella.Orava hakemistopuussa¶

Hankalampi vaihe – tai ainakin sellainen, missä kohdataan taas jotain uutta – on kansioiden läpikäynti. Peruskaava on aika selkeä: otetaan listaus hakemiston sisällöstä ja käydään se läpi yksi elementti kerrallaan: kansiot avataan jatkokäsittelyyn, musiikkitiedostot luetaan. Tästä nousee kuitenkin yksi kysymys: miten pystytään navigoimaan ennaltatuntematon kansiopuu, kun ei voida tietää miten monta tasoa alikansioita sieltä löytyy? Keinoja on kaksi: toista kutsutaan rekursioksi, jossa
funktio
kutsuu itseään uusilla argumenteilla
; toisessa kerätään läpikäytäviä kansioita listaan
sitä mukaa kun niitä löytyy. Tässä skenaariossa, jossa voidaan olettaa, että kansiorakenteet eivät ole erityisen syviä, rekursio on parempi ratkaisu. Sen sijaan mm. miinaharavoijien on syytä välttää rekursiota, koska Python alkaa murista mikäli sisäkkäisiä funktiokutsuja
kasaantuu liikaa.Molemmissa on joka tapauksessa sama ajatus: algoritmi merkitsee itselleen tulevaisuudessa suoritettavia tehtäviä (eli avattavia kansioita) joko laittamalla funktiokutsuja jonoon tai laittamalla kansioita listaan. Aina kun kansio on avattu ja käsitelty loppuun, se poistetaan työlistasta. Algoritmi siis määrittää itse omien toistojensa määrän. Koska läpikäytävä rakenne on hierarkinen ja siinä liikutaan vain yhteen suuntaan, ikuiseen silmukkaan päätymisestä ei ole pelkoa ja jokainen kansio käydään läpi vain kerran.
Toteutettava funktio on siis lue_kansio. Sille annetaan kansio-
parametrissa
läpikäytävän kansion polku
. Ensimmäinen vaihe on siis tietenkin selvittää mitä kansiosta löytyy. Tämä onnistuu ottamalla avuksi os-moduuli, ja erityisesti sieltä tiedostoja ja hakemistoja käsittelevät funktiot, joista löytyy listdir-funktio. Tätä voidaan testata nopeasti vaikka tulkissa
:In [1]: import os
In [2]: os.listdir("E:/Music/Aura")
Out[2]:
['Saor - 04 - Farewell.mp3',
'Saor - 05 - Pillars of the Earth.mp3',
'Saor - 01 - Children of the Mist.mp3',
'Saor - 02 - Aura.mp3',
'Saor - 03 - The Awakening.mp3']
Funktio siis palauttaa listan löytämistään tiedostojen (ja kansioiden nimistä). Mistä sitten tunnistetaan mikä on kansio ja mikä tiedosto? Tähän vastaus löytyy os.path-alimoduulista, joka käsittelee käyttöjärjestelmän
polkuja
. Sieltä löytyy isdir-funktio, joka kertoo milloin kyseessä on hakemisto. Muuten kyseessä on tietenkin tiedosto. Toinen ongelma on, että muut kuin musiikkitiedostot pitäisi tietenkin ohittaa. Vaihtoehtoisesti voimme tutkia ehtolauseella
tiedostopäätteitä, tai sitten selvittää minkä poikkeuksen
tinytag aiheuttaa jos tiedostoa ei voi lukea. Jälkimmäinen on jälleen kerran parempi lähestymistapa, sillä musiikkikansioita tonkiessa voidaan aika hyvin olettaa, että sieltä löytyy pääasiassa musiikkia. Selvitetään siis ihan ensimmäisenä mikä poikkeus syntyy:In [1]: import tinytag
In [2]: tinytag.TinyTag.get("nuuskija.py")
---------------------------------------------------------------------------
TinyTagException Traceback (most recent call last)
<ipython-input-2-db5293e53a65> in <module>()
----> 1 tinytag.TinyTag.get("nuuskija.py")
/usr/local/lib/python3.7/site-packages/tinytag/tinytag.py in get(cls, filename, tags, duration, image)
124 return TinyTag(None, 0)
125 if cls == TinyTag: # if `get` is invoked on TinyTag, find parser by ext
--> 126 parser_class = cls._get_parser_for_filename(filename, exception=True)
127 else: # otherwise use the class on which `get` was invoked
128 parser_class = cls
/usr/local/lib/python3.7/site-packages/tinytag/tinytag.py in _get_parser_for_filename(cls, filename, exception)
115 return tagclass
116 if exception:
--> 117 raise TinyTagException('No tag reader found to support filetype! ')
118
119 @classmethod
TinyTagException: No tag reader found to support filetype!
Muistetaan, että tämä poikkeus on tinytag-moduulin oma, joten siihen tarvitaan nykyisellä importilla tinytag eteen. Tällä tiedolla varustettuna pystymme kirjoittamaan jälleen ensin testifunktion (tässä näkyy myös lisätty
import
):import os
import tinytag
def lue_kansio(kansio, kokoelma):
sisalto = os.listdir(kansio)
for nimi in sisalto:
polku = os.path.join(kansio, nimi)
if os.path.isdir(polku):
print("Löytyi kansio:", nimi)
else:
try:
lue_tiedot(polku, kokoelma)
except tinytag.TinyTagException:
print("Ohitetaan", nimi)
Silmukan
ensimmäinen rivi yhdistää hakemistosta löytyneen nimen hakemiston polkuun
– muuten tiedosta etsitään väärästä paikasta (siitä hakemistosta jossa ohjelma käynnistettiin). Printit jotka kertovat verbaalisesti mitä ohjelma tekee ovat hyviä testaamiseen. Testiä varten luodaan ylimääräinen tyhjä kansio hakemistoon, jossa on musiikkitiedostoja. Olkoon vaikka nimeltään "testi". Luodaan lisäksi sinne tekstitiedosto. Tällöin nähdään kaikki tapaukset. Muutetaan pääohjelmaa testaamaan nyt tätä funktiota:kokoelma = []
lue_kansio("E:/Music/Aura", kokoelma)
print(kokoelma)
Löytyi kansio: test
Ohitetaan aasi.txt
[{'kestot': [733.4138775510204, 817.1885714285714, 606.3804081632653, 499.9836734693878, 729.5738775510204], 'artisti': 'Saor', 'albumi': 'Aura', 'julkaisuvuosi': '2014'}]
Nyt kun jälleen voidaan todeta, että ehto- ja try-rakenteet toimivat odotetulla tavalla, voidaan muokata koodi lopulliseen muotoonsa, eli tulostuksen sijaan kutsutaan
ehtolauseen
sisällä uudestaan samaa funktiota
. Poikkeuksen käsittelyyn voidaan laittaa pelkästään pass. Koska ohjelma saattaa myös pyöriä aika pitkään, käyttäjän mielenrauhaa saattaa auttaa, jos aina uutta kansiota aloittaessa ilmoitetaan mikä kansio on käsittelyssä. Näin käyttäjä voi seurata ohjelman etenemistä sen sijaan, että tuijottaa mustaa ruutua ja miettii onko ohjelma jumittunut vai kestääkö sen suoritus vain pitkään.def lue_kansio(kansio, kokoelma):
print("Avataan kansio:", kansio)
sisalto = os.listdir(kansio)
for nimi in sisalto:
polku = os.path.join(kansio, nimi)
if os.path.isdir(polku):
lue_kansio(polku, kokoelma)
else:
try:
lue_tiedot(polku, kokoelma)
except tinytag.TinyTagException:
print("Ohitetaan", nimi)
Tämän voikin sitten suorittaa koko musiikkikansiolleen muuttamalla pääohjelman testikoodia:
kokoelma = []
lue_kansio("E:/Music", kokoelma)
for levy in kokoelma:
print(levy)
Tässä voikin sitten kestää, riippuen kokoelman suuruudesta. Alla mallipätkä suorituksesta, josta nähdään ainakin se, että os.listdir ei anna kansioita ainakaan aakkosjärjestyksessä. Suorituksesta on suurin osa pätkitty pois, mitä kuvaavat kolmipisteoperaattorit:
Avataan kansio: E:/Music
Avataan kansio: E:/Music\Exercises in Futility
Avataan kansio: E:/Music\Pelagial
Avataan kansio: E:/Music\Moonlover
Avataan kansio: E:/Music\Guardians
...
{'artisti': 'Mgla', 'kestot': [478.58938775510205, 468.5583673469388, 278.02122448979594, 285.7534693877551, 495.6734693877551, 529.5804081632654], 'albumi': 'Exercises in Futility', 'julkaisuvuosi': '2015'}
{'artisti': 'The Ocean', 'kestot': [72.48979591836735, 356.31020408163266, 264.5420408163265, 198.11265306122448, 267.36326530612246, 207.934693877551, 305.34530612244896, 67.1869387755102, 557.9232653061224, 545.410612244898, 355.6048979591837], 'albumi': 'Pelagial', 'julkaisuvuosi': '2013'}
{'artisti': 'Ghost Bath', 'kestot': [87.04, 548.6497959183673, 524.6432653061224, 287.63428571428574, 243.905306122449, 453.48571428571427, 385.5412244897959], 'albumi': 'Moonlover', 'julkaisuvuosi': '2015'}
{'artisti': 'Saor', 'kestot': [692.610612244898, 632.0065306122449, 669.2832653061224, 687.8824489795918, 679.3926530612245], 'albumi': 'Guardians', 'julkaisuvuosi': '2016'}
...
Paketti kasaan¶
Vielä yksi toiminto puuttuu: tällä hetkellä luettu data ei vastaa kokoelma-ohjelman käyttämää muotoa. Sen vaatimat kesto- ja n-kentät pitää vielä laskea datasta. Lisäksi kesto on tällä hetkellä sekunteina, kun haluasimme sen olevan kestoa kuvaavana merkkijonona. Hätä ei ole tämän näköinen, sillä time-
moduulista
löytyy sopivia työkaluja. Käyttöön tarvitaan strftime-funktio
, joka muuntaa ajan merkkijonoksi. Merkkijonoon voi määritellä miten sinne sijoitellaan aikaleiman eri osat. Aikamuodon määrittelyyn löytyy ohjeet strftime-funktion kohdalta.Esim. kirjoituspäivän päivämäärän voisi tulostaa näin.
In [1]: import time
In [2]: time.strftime("%d.%m.%Y", time.localtime())
Out[2]: '10.10.2018'
Useimmiten tosin päivämäärät halutaan esittää toisenlaisessa muodossa. Lisätään myös kellonaika mukaan, jotta saadaan kunnollinen aikaleima:
In [3]: time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
Out[3]: '2018-10-10 11:49:07'
Missä näkyykin lopussa miten muotoillaan kokoelmaohjelman käyttämä muoto levyn kestolle. Kesto on kuitenkin tällä hetkellä sekunteina, ja jos sitä koittaa suoraan antaa strftime-funktiolle, siitä ei hyvä heilu.
In [4]: time.strftime("%H:%M:%S", 453)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-c2ee80529b06> in <module>()
----> 1 time.strftime("%H:%M:%S", 453)
TypeError: Tuple or struct_time argument required
Poikkeus siis kertoo, että meillä pitäisi olla
monikko
tai mysteerinen struct_time-tyyppinen arvo. Aiemmin käyttämämme localtime-funktio palauttaa oletuksena nykyisen ajan tässä halutussa muodossa, mutta sille voidaan myös antaa argumentiksi sekuntien määrä. Kolmen minuutin kappaleelle siis esim:In [5]: time.localtime(180)
Out[5]: time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=2, tm_min=3, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)
Tuossa näkyy vähän kaikenlaista informaatiota. Päivämäärä on tietokoneen ajanlaskun virallinen nollakohta, eli 1.1.1970 klo 00:00:00. Halutessa tuon tyyppisestä rakenteesta voidaan myös poimia yksittäisiä aikakomponentteja seuraavasti:
In [6]: kesto = time.localtime(180)
In [7]: kesto.tm_min
Out[7]: 3
In [8]: kesto.tm_hour
Out[8]: 2
Hetkinen mistäs tuo 2 tuntia lisää tuli kestoon? Aikavyöhykkeistä, koska localtime huomioi ne mukaan. Tämä on kätevää, jos halutaan nykyinen aika, mutta vähemmän kätevää, jos halutaan sekunneista levyn tai kappaleen kesto. Onneksi time-moduulista löytyy myös gmtime-funktio, joka laskee ajan ilman aikavyöhykettä. Rivi jolla sekunneista saa siis keston oikein olisi:
In [9]: time.strftime("%H:%M:%S", time.gmtime(180))
Out[9]: '00:03:00'
Tätä soveltamalla voidaan kirjoittaa funktio, joka käy koko kokoelman läpi muuttaen kestotiedot
listoista
suoraan kuvatun mukaisiksi merkkijonoiksi.def parsi_kestotiedot(kokoelma):
for levy in kokoelma:
levy["kesto"] = time.strftime("%H:%M:%S", time.gmtime(sum(levy["kestot"])))
levy["n"] = len(levy["kestot"])
levy.pop("kestot")
Koeajo antaa:
{'artisti': 'Mgla', 'albumi': 'Exercises in Futility', 'julkaisuvuosi': '2015', 'kesto': '00:42:16', 'kpl_n': 6}
{'artisti': 'The Ocean', 'albumi': 'Pelagial', 'julkaisuvuosi': '2013', 'kesto': '00:53:18', 'kpl_n': 11}
{'artisti': 'Ghost Bath', 'albumi': 'Moonlover', 'julkaisuvuosi': '2015', 'kesto': '00:42:10', 'kpl_n': 7}
{'artisti': 'Saor', 'albumi': 'Guardians', 'julkaisuvuosi': '2016', 'kesto': '00:56:01', 'kpl_n': 5}
...
Lopulta tehdään vielä funktio, jota kokoelma-ohjelma voi kutsua kun halutaan lukea kokoelma kansiosta. Tämä muistuttaa aika paljon pääohjelmaa jota on käytetty toimintojen testaamiseen.
def lue_kokoelma(kansio):
kokoelma = []
lue_kansio(kansio, kokoelma)
parsi_kestotiedot(kokoelma)
return kokoelma
Sitten vain toteuttamaan uutta toimintoa kokoelma-ohjelmaan. Ennen kuin importataan uusi moduuli kokoelma-ohjelmassa, perehdytään kuitenkin erääseen moduulien kirjoittamiseen liittyvään asiaan. Lähestytään asiaa tehtävän kautta.
Vuotava pallo¶
Kun vanhaa koodia muutetaan moduuleiksi, on tärkeää muistaa lisätä ehto, joka estää pääohjelman suorittamisen kun koodia otetaan käyttöö muualta. Tässä tehtävässä demonstroimme mitä tapahtuu, kun tätä ehtoa ei muista. Käytetään tässä esimerkissä aivan supermuinaista koodia, eli otetaan avuksi 1. harjoitusten esimerkkikoodista alunperin liikkeelle lähtenyt pallokoodi. Haluamme tässä esimerkissä ottaa aiemmin tehdystä pallokoodimoduulista käyttöön funktiot laske_ala ja laske_tilavuus. Kopioinnin sijaan haluamme ne käyttöön importin kautta.
Opittavat asiat: Nähdä mitä tapahtuu, kun
moduulista
on unohtunut if __name__ == "__main__": ehtolause
pääohjelmasta
. Alustus:
Lataa alla annettu kooditiedosto koneellesi ja tallenna se nimellä
pallo.py. Avaa sama kansio terminaalissa
ja käynnistä interaktiivinen tulkki
. Kirjoita tulkkiin: In [1]: import pallo
Haettu vastaus:
Vastaukseen haetaan ensimmäistä riviä, joka tulostuu terminaalin kun em. rivi on kirjoitettu tulkkiin.
Resurssit:
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Eivät
importit
aikaisemmin ole mitään tämmöistä tehneet! Onko moduulien
kirjoittamisessa sittenkin jotain erilaista kuin muun koodin? Ei varsinaisesti. Asia on vain niin, että import-lause tosiasiassa suorittaa käyttöönotettavan moduulin. Tässä auttaa jos muistaa, että def on lause, joka suoritettaessa luo uuden funktion
. Ongelma on vain siinä, että meidän moduulissamme on muutakin koodia kuin def-lauseita ja importeja. Pääohjelma
tulee siis ikävästi suoritettua importin aikana, mikä ei ole toivottavaa. Tietenkin voitaisiin luopua nuuskija-moduulissa olevasta testikoodista, jotta siinä ei olisi lainkaan pääohjelmaa. Tämä ei kuitenkaan helpota sitä, että joskus haluamme ottaa osia käyttöön ohjelmasta, jota on myös tarkoitus käyttää itsenäisesti.Onneksi Pythonista löytyy tähänkin keino. Kun moduuleja suoritetaan, niillä on sisäiseen käyttöön tarkoitettu
muuttuja
nimeltään __name__. Normaalisti __name__ sisältää moduulin nimen, mutta mikäli ohjelma on suoritettavana ohjelmana, __name__ saakin arvon "__main__". Tällä tavalla voidaan erottaa milloin ohjelmaa suoritetaan ja milloin se on importattu muualta (jolloin ei siis haluta suorittaa pääohjelmaa). Testi tehdään yksinkertaisella ehtolauseella
:if __name__ == "__main__":
Koko pääohjelma laitetaan siis tämän ehtolauseen sisälle. Tehdään siis tämä temppu pallomoduulille:
Jos nyt kokeillaan importia:
In [1]: import pallomoduuli
Ei tapahdu mitään näkyvää – ja juuri näin kuuluukin olla. Nyt on suoritettu moduulista pelkästään
funktioiden
määrittelyt ja jätetty pääohjelma
suorittamatta. Sen sijaan jos käynnistetään pallomoduuli komennolla ipython pallomoduuli.py, pääohjelma suorittuu. Tehdään siis sama temppu nuuskija-moduulin testikoodille, ja miksipä ei samantien myös kokoelma-ohjelman pääohjelmalle. Tämän jälkeen voidaan ottaa uusi moduuli käyttöön kokoelma-ohjelmassa lisäämällä alkuun uusi import-lause:import json
import nuuskija
import sys
import time
Lisätään päävalikkoon mahdollisuus lukea kokoelma kiintolevyltä:
def valikko(lahdetiedosto, kohdetiedosto):
kokoelma = lataa_kokoelma(lahdetiedosto)
print("Tämä ohjelma ylläpitää levykokoelmaa. Voit valita seuraavista toiminnoista:")
print("(R)akenna kokoelma")
print("(L)isää uusia levyjä")
print("(M)uokkaa levyjä")
print("(P)oista levyjä")
print("(J)ärjestä kokoelma")
print("(T)ulosta kokoelma")
print("(Q)uittaa")
while True:
valinta = input("Tee valintasi: ").strip().lower()
if valinta == "r":
kokoelma = rakenna_kokoelma()
elif valinta == "l":
lisaa(kokoelma)
elif valinta == "m":
muokkaa(kokoelma)
elif valinta == "p":
poista(kokoelma)
elif valinta == "j":
jarjesta(kokoelma)
elif valinta == "t":
tulosta(kokoelma)
elif valinta == "q":
break
else:
print("Valitsemaasi toimintoa ei ole olemassa")
tallenna_kokoelma(kokoelma, kohdetiedosto)
Jäljelle jää enää rakenna_kokoelma-funktion toteuttaminen:
def rakenna_kokoelma():
kansio = input("Syötä kansio josta haluat rakentaa kokoelman: ")
try:
kokoelma = nuuskija.lue_kokoelma(kansio)
except FileNotFoundError:
print("Kansiota ei löytynyt")
return kokoelma
Tässä toteutuksessa rakennettu kokoelma korvaa mahdollisen ladatun kokoelman. Nyt kun kokoelmassa on viimein oikeasti vähän enemmän tavaraa, voidaan sivutus tulostusfunktiosta muuttaa takaisin alunperin mietittyyn arvoon 20. Lopulliset kooditiedostot ovat alla:
Omien
moduulien
tekemistä pääsee harjoittelemaan harjoituksissa. Entä kannattaako lopputyötä jakaa useisiin moduuleihin? Normaalisti ei. Lopputyön koodimäärät ovat yleensä kohtalaisen pieniä, eikä moduuleihin jakamisesta ole mitään suurta etua selkeyden kannalta. Tietenkin lopputyönsä saa jakaa moduuleiksi, jos tuntee, että sillä tavalla saa asiat paremmin itselleen jäsennettyä. Moduuleihin jakamisessa pätee sama sääntö kuin monessa muussakin asiassa: miten tahansa teetkin, toimi johdonmukaisesti. Koodin voi jakaa moduuleihin vaikka temaattisesti, esim miinaharavassa voi olla päävalikkoa varten oma moduulinsa, ja jokaista sen toimintoa varten omansa.Graafista loistoa¶
Terminaalissa pyörivät tekstiohjelmat ovat hiukan liian 80-lukua. Nykyaikana voisi ehkä edes yrittää tehdä jotain mikä avautuu omaan ikkunaansa ja jota voi tökkiä hiirellä tai kosketusnäytöllä. Viimeistellään siis urakka siirtämällä kokoelmaohjelma terminaalista ikkunaan. Tässä opittavat asiat eivät varsinaisesti kuulu alkeisiin, mutta nykyaikana suuri osa ohjelmoinnista perustuu tässä läpikäytäviin käsitteisiin. Lisäksi nykyaikana työkalut grafiikan tekoon koodilla ovat sen verran päheitä, että pienellä pintaraapaisullakin saa paljon aikaan.
Ilman suunnitelmaa ei kannata tähänkään projektiin ryhtyä. Ei ole ehkä syytä lähteä tavoittelemaan kuuta taivaalta, joten tyydytään hienojen käyttökokemusten sijaan lähinnä siihen, että saadaan ohjelman nykyiset tekstimuotoiset valikkorakenteet muutettua graafisiksi siten, että päätoiminnot löytyvät painikkeina ohjelman pääkäyttöliittymästä ja alivalikot aukeavat tarpeen mukaan erillisiin ali-ikkunoihin. Kokoelman sisältö näkyy jonkinlaisessa taulukossa tai tekstilaatikossa pääikkunassa. Tarvitaan siis
kirjasto
, joka kykenee tarjoamaan nämä perustoiminnot.Kannattaa myös esimerkkiä lukiessa pitää mielessä, että se on monimutkaisempi kuin lopputyön minimivaatimukset - siellä siis pääsee vähemmällä.
Osaamistavoitteet: Oppia hyvin minimaaliset perusteet siitä miten modernit käyttöliittymäkirjastot toimivat. Tähän kuuluu aivan erityisesti
käsittelijäfunktioiden
sielunelämän ymmärtäminen ja siihen miten niiden välillä tulisi jakaa informaatiota. Lisäksi opitaan miten yksi kurssin lopputöitä varten tehty graafinen käyttöliittymäkirjasto toimii. Toinen opitaan viimeisestä harjoitusesimerkistä.Kirjastoesittely¶
Normaalisti tässä vaiheessa tehtäisiin hieman tutkimusta siitä mikä kirjasto sopii parhaiten tarkoitukseen. Tämä jätetään kuitenkin tällä kertaa tekemättä, koska alkeiskurssin tiedoilla ei oikeasti voi vielä kovin hyvin tällaista arvioida. Pythonin mukana tulee TKinter-kirjasto, joka on vanha kuin taivas, ja jonka tuottama jälki on rumaa kuin suolaisen Dota-pelaajan käytös kolmelta aamuyöllä, mutta se sattuu tekemään kaikki graafisen käyttöliittymän perusteet aika yksinkertaisella tavalla. Ei tosin niin yksinkertaisella, että niitäkään olisi syytä alkaa tässä tarkemmin purkaa. Sen sijaan käytämme tätä kurssia varten tehtyä palikkaa, joka yksinkertaistaa TKinterin toiminnoista osan muutamaan helposti käsitettävään
funktioon
. Koodi on myös dokumentoitu dokumenttimerkkijonoilla
kohtalaisen yksityiskohtaisesti.Tämä on muuten sama kuin Spektriä pukkaa ja Piiri pieni pyörii lopputöissä käytettävä kirjasto, mutta tästä on poistettu matplotlib-tuki, jotta haravoijien ei tarvitse asentaa sitä pelkästään esimerkkejä testatakseen. Kirjastoa ei käydä sen tarkemmin läpi kuin siltä osin mitä esimerkissä tarvitaan. Muuten se jätetään kotitehtäväksi lopputyötä tehdessä.
Ihmemaan takaisinkutsut¶
Takaisinkutsua
käytettiin hyvin lyhyellä esittelyllä listojen
järjestämisessä. Listan sort-metodille
pystyttiin antamaan argumenttina funktio
, jota käytettiin järjestämisen aikana vertailuarvojen
saamiseen - näiden avulla siis pystyttiin valitsemaan minkä tiedon perusteella listan alkiot
järjestetään. Esim:kokoelma.sort(key=valitse_kesto, reverse=kaanna)
Erikoista tässä asetelmassa on siis se, että emme kutsu missään vaiheessa omassa koodissa valitse_kesto-funktiota - sitä kutsutaan silloin, kun ohjelman ohjaus on luovutettu tilapäisesti sort-metodille.
Argumentin
antaminen siis kertoo sort-metodille mitä funktiota sen tulee kutsua, kun sen tarvii saada vertailuarvo listan alkiolle. Koska argumenttien antamisesta vastaa sort-metodi, emme voi vaikuttaa siihen mitä funktiolle annetaan emmekä myöskään siihen mitä sen paluuarvolla tehdään. Takaisinkutsufunktioita tehtäessä onkin tärkeää selvittää hyvin tarkasti mitä argumentteja funktio saa ja mitä sen paluuarvolla tehdään, jotta voidaan asettaa oikea määrä parametrejä
sekä palauttaa
oikeanlainen arvo. Esimerkissä käytettyä funktiota katsomalla selviää, että sillä tulee olla yksi parametri (listan yksi alkio) ja se palauttaa yhden arvon:def valitse_kesto(levy):
return levy["kesto"]
Tämän asian kertaaminen on tärkeää, koska sama ilmiö toistuu käyttöliittymä- ja pelikirjastojen kanssa, mutta paljon laajempana. Niille on nimittäin tyypillistä se, että koko ohjelmaa ohjaava pääsilmukka sijaitsee jossain kirjaston syövereissä. Nykyisessä kokoelmaohjelmassa valikko-funktiossa oleva
while True:-silmukka on siis pääohjelmasilmukka, ja tällaista ei tulla lainkaan näkemään koodissa kun se muutetaan käyttämään graafista kirjastoa. Ohjelman kulkua tullaan siis ohjaamaan ikään kuin ulkopuolelta. Syytäkään ei tarvi kauaa ihmetellä: pääsilmukan pitäisi pystyä reagoimaan siihen kun käyttäjä on vuorovaikutuksessa käyttöliittymän kanssa, joten siihen kuuluu aika paljon koodia. Tätä koodimäärää ei ole kauhean mielekästä alkaa itse kirjoittaa, joten se on parempi ulkoistaa kirjastolle.Jos ohjelman kulun hallinta on poistettu ohjelmoijan omista kätösistä jonnekin mystisen kirjaston syövereihin, miten tässä päästään toteuttamaan yhtään mitään? Vastaus löytyy nimenomaan takaisinkutsufunktioista joita myös
käsittelijäfunktioiksi
kutsutaan. Ennen pääsilmukan käynnistämistä koodari voi kertoa kirjastolle millaiset tapahtumat
ohjelmaa kiinnostavat. Tapahtuma tarkoittaa esim. sitä, kun pääsilmukka havaitsee käyttäjän tekevän jotain. Näihin tapahtumiin voidaan kiinnittää käsittelijäfunktio. Jos määritetty tapahtuma kohdataan, kutsutaan siihen kiinnitettyä käsittelijää.Käyttöliittymäkirjastojen tapauksessa on yleistä, että kuhunkin aktiiviseen käyttöliittymäelementtiin kiinnitetään oma käsittelijä. Tämä tehdään siinä yhteydessä kun käyttöliittymän komponentit ylipäätään määritellään. Eli jos vaikka halutaan luoda nappi, siihen voidaan luomisen yhteydessä määrittää funktio, jota käyttöliittymäkirjasto kutsuu kun käyttäjä painaa nappia. Meidän yksinkertainen kirjastomme toteuttaa tämän siten, että siellä on tasan yksi napinluontifunktio, jolle annetaan kolme argumenttia:
- kehyselementti johon nappi sijoitetaan (ks. seuraava osio)
- napissa lukeva teksti (merkkijono)
- funktio joka toimii napin käsittelijänä
Korkealla tasolla ajateltuna se mitä tapahtuu kun graafista käyttöliittymää tarjoava ohjelma käynnistetään on siis seuraavanlainen prosessi:
- ohjelma määrittelee käyttöliittymän elementit käsittelijäfunktioineen
- ohjelma kutsuu funktiota, joka käynnistää käyttöliittymäkirjaston pääsilmukan
- käyttöliittymäkirjasto seuraa käyttäjän toimia
- käyttäjä tekee jotain, mikä kiinnostaa ohjelmaa (= tapahtuma, johon on kytkettykäsittelijä)
- käyttöliittymäkirjasto kutsuu käsittelijäfunktiota, jolloin ohjaus palaa varsinaiselle ohjelmalle
- käsittelijäfunktion suorituksen päätyttyä ohjaus siirtyy takaisin käyttöliittymäkirjastolle
- ohjelmassa oleva käsittelijäfunktio kutsuu funktioita, joka sammuttaa käyttöliittymäkirjaston pääsilmukan ja ohjaus palautaa ohjelmalle
- ohjelma voi suorittaa lopetukseen liittyvät toimenpiteet (esim. datan tallennus)
- ohjelma päättyy
Käyttöliittymäsimulaattori¶
Jotta toimintaperiatteeseen saadaan hieman kosketusta, tutkitaan hetki oheista approksimaatiota siitä millainen käyttöliittymäkirjasto voisi olla. Esitetty koodi on moninkertaisesti yksinkertaisempi kuin oikea käyttöliittymäkirjasto, mutta käyttäytyy kuitenkin samanlaisella logiikalla. Kirjaston funktioilla voidaan siis määrittää nappeja, ja se voidaan käynnistää jolloin se keräilee "klikkauksia" (jotka tuotetaan tässä tapauksessa satunnaisina pistepareina hiiren lukemisen sijaan), ja suorittaa nappien toimintoja mikäli klikkaus osuu johonkin niistä.
Tärkeintä tässä approksimaatiossa on se, että sen voisi korvata em. ikkunasto-kirjastolla - määritettyjen funktioiden rajapinnat ovat nimittäin samat kirjastoa käyttävän moduulin näkökulmasta. Käyttöliittymäkirjastojen toiminnan ymmärtämiseksi on tarpeen tarkastella kahta tässä esiintyvää funktiota, sekä sitä miten niitä käytettäisiin varsinaisessa ohjelmassa. Tätä varten on luotu siis oheinen testiohjelma, joka luo muutaman napin sisältävän käyttöliittymän.
Koodin suoritus ei luo näkyvää ikkunaa, koska kirjasto ainoastaan simuloi oikean kirjaston toimintaa. Sen sijaan
terminaaliin
tulostuu pisteitä ja välillä "aasi" tai "hemuli" - yksi piste kuvaa yhtä klikkausta, ja sanan ilmestyminen tarkoittaa, että klikkaus osui johonkin määritellyistä napeista. Samaten ohjelma päättyy, kun klikkaus osuu lopetusnappiin. Suoritus voi siis näyttää esim tältä:..................................aasi ............hemuli ..aasi ......................................................aasi ..................aasi ..terve, ja kiitos kaloista
Koska simulaattorin koodi on paljon yksinkertaisempaa, syy-seuraus-suhteet ovat myös helpompia seurata. Tarkastellaan erityisesti kahden kirjastossa olevan funktion toimintaa. Tavoitteena on siis ymmärtää miksi lopullinen ohjelma (eli kirjastotesti.py) toimii kuten se toimii. Ensimmäinen puoli on käyttöliittymän asettelu. Varsinaisen ohjelman näkökulmasta käyttöliittymä muodostuu kehyksistä (sarakkeita) ja napeista (rivejä sarakkeiden sisällä). Ohjelma voi siis luoda kehyksiä, ja tuupata uusia nappeja niihin. Kirjaston puolella nappien luomisesta vastaa
luo_nappi-funktio.def luo_nappi(kehys, teksti, toiminto):
vasen = ikkuna.index(kehys) * NAPPI_LEVEYS
oikea = vasen + NAPPI_LEVEYS
yla = len(kehys) * NAPPI_KORKEUS
ala = yla + NAPPI_KORKEUS
kehys.append({
"vasen": vasen,
"oikea": oikea,
"yla": yla,
"ala": ala,
"teksti": teksti,
"toiminto": toiminto
})
Tämä funktio laskee napin varsinaisen sijainnin ikkunan sisällä ja tallentaa napin reunoja vastaavat x- ja y-arvot
sanakirjaan
. Tässä siis rajataan käyttöliittymän alue, joka kuuluu tälle napille. Yhden napin leveys on 200 yksikköä ja korkeus 60 yksikköä, sijainti perustuu siihen mikä on kehyksen indeksi
ikkunan sisällä, sekä siihen montako nappia kehyksessä jo on. Toinen erittäin tärkeä asia joka talletetaan sanakirjaan on toiminto-parametrin
arvo, joka on siis funktio
. Tämä funktio siis suorittaa varsinaisen nappiin sidotun toiminnon - mutta vasta sitten kun nappia painetaan! Funktiota ei siis kutsuta vielä.Varsinaisen ohjelman puolella nappi luodaan siis
luo_nappi-funktiota kutsumalla, kun ensin ollaan määritelty toiminnoksi annettava funktio:def tulosta_aasi():
print("aasi")
ikkuna = kirjasto.luo_ikkuna("testi")
kehys = kirjasto.luo_kehys(ikkuna)
kirjasto.luo_nappi(kehys, "nappi 1", tulosta_aasi)
Tärkeää tässä on kiinnittää huomiota siihen, että funktiota käsitellään kuin
muuttujaa
: sitä ei siis kutsuta, se vain annetaan argumenttina
. Esimerkkiohjelmassa luodaan kolme nappia, jonka jälkeen meillä on alla olevaa kuvaa vastaa "käyttöliittymä".
Napit ovat siis ikkunaan merkittyjä alueita, ja hiiren klikkaaminen kursorin ollessa napin alueen sisällä aiheuttaa napin painamisen. Tämä on se vaihe, missä ohjelman kontrolli luovutetaan kirjastolle - tarkalleen ottaen siellä olevalle
kaynnista-funktiolle. Funktiosta on poistettu hiukan ylimääräistä tavaraa, jotta logiikka näkyy selkeämmin:def tunnista_nappi(x, y, ikkuna):
for kehys in ikkuna:
for nappi in kehys:
if nappi["vasen"] <= x <= nappi["oikea"]:
if nappi["yla"] <= y <= nappi["ala"]:
funktio = nappi["toiminto"]
funktio()
return
def kaynnista():
tila["kaynnissa"] = True
while tila["kaynnissa"]:
print(".", end="", flush=True)
hiiri_x, hiiri_y = lue_klikkaus()
tunnista_nappi(ikkuna, hiiri_x, hiiri_y)
# lisätty jotta ohjelma ei pyöri liian nopeasti
time.sleep(0.1)
Oikean käyttöliittymäkirjaston vastaava funktio on tietenkin paljon monimutkaisempi, mutta pohjimmillaan siinä tehdään samat asiat:
- luetaan hiiren klikkauksen sijainti
- etsitään osuuko klikkaus jonkin käyttöliittymäelementin sisälle
- jos osuu, suoritetaan toiminto ja
- lopetetaan etsintä
Tätä siis toistetaan ikuisessa silmukassa kunnes ohjelman suoritus päättyy. Meidän simulaattorissamme vaihe 1 hoituu kutsumalla
lue_klikkaus-funktiota, josta saadaan (kuvitellun) klikkauksen x- ja y-koordinaatit. Vaihe 2 tapahtuu käymällä läpi kaikki kehykset sekä niissä olevat nappeja kuvaavat sanakirjat, ja vertaamalla niissä määriteltyjä rajoja klikattuun pisteeseen. Mikäli piste osuu rajojen sisällä, napin toiminto suoritetaan ottamalla sanakirjan "toiminto" avaimesta
viittaus
kutsuttavaan funktioon, ja kutsutaan sitä (ilman argumentteja).Tärkeintä tässä on siis nähdä konkreettisesti millaisessa kontekstissa napin toiminnoksi annettua funktiota tullaan lopulta kutsumaan. Kuten tästä nähdään, funktiolle annettavat argumentit määritellään kutsun yhteydessä (ja tässä tapauksessa niitä ei ole). Syntaksista myös ilmenee, että mikäli muuttuja sisältää funktion ja sen perään laitetaan kutsusulut, muuttuu kyseinen rivi muuttujaan talletetun funktion
kutsumiseksi
. Tässä vaiheessa siis kontrolli palaa varsinaisen ohjelman puolelle, ja tarkalleen siellä olevan käsittelijäfunktion
sisälle, joka ensimmäisen napin tapauksessa olisi siis:def tulosta_aasi():
print("aasi")
Näinpä siis terminaaliin tulostuu aasi. Ajossa terminaaliin tulostuneet pisteet kuvaavat klikkauksia, riippumatta siitä osuiko hiiri johonkin nappiin tai ei. Kun ohjelma "sammutetaan" kutsumalla kirjaston
lopeta-funktiota, kontrolli palaa varsinaiseen ohjelmaan ja jatkuu kaynnista-funktiokutsua seuraavalta riviltä, eli tältä riviltä - tästä syystä siis ohjelman päättyessä tulostuu "terve, ja kiitos kaloista":print("terve, ja kiitos kaloista")
Kokonaisessa kirjastossa on lisätty vielä mahdollisuus näyttää visualisointi toiminnasta turtlen avulla. Voit laittaa tämän visualisoinnin päälle lisämäällä
komentoriviargumentin
-p tai --piirto ohjelman käynnistykseen:python kirjastotesti.py --piirto
Huomaa, että napeissa ei lue mitään. Ylin nappi tulostaa aasin, toinen hemulin, ja kolmas lopettaa ohjelman. Voit pitää terminaalin näkyvissä turtle-ikkunan rinnalla, jolloin näet mitä sinne tulostuu kunkin klikkauksen kohdalla.
Toinen näppärä yksityiskohta: mikäli vaihdat ensimmäisen rivin importin siten, että se ottaakin käyttöön ikkunaston, testikoodi toimii suoraan, ja tuottaa oikean käyttöliittymän. Eli ensimmäiseksi riviksi tulisi:
import ikkunasto as kirjasto
Jolloin ohjelman suoritus tuottaakin oikean ikkunan. Ikkunan geometria on erilainen, koska elementtien asettelusta vastaa kirjasto, ei kirjastoa käyttävä ohjelma. Tästä onkin kerrottu tarkemmin seuraavan otsikon alla.
Ohjeellinen käsittelijä¶
Käsittelijäfunktion asettaminen käyttöliittymäkomponenteille sekä erilaisille tapahtumille koodissa on tärkeä osa nykyajalle tyypillistä ohjelmointia. Kirjoitetaan tässä tehtävässä yksi käsittelijällä varustettu nappi kokeeksi.
Opittavat asiat:
käsittelijäfunktion
asettaminen käyttöliittymäkomponentille. Napin luominen ikkunasto-moduulin avulla.Alustus:
Tehtävänannon lopussa näet koodin, jossa on pienen käyttöliittymän ensiaskeleet. Koodista löytyy valmiiksi funktio, jota on tarkoitus käyttää käsittelijänä, sekä ikkuna ja kehys. Koodista puuttuu vielä rivi, joka lisää ohjeikkunan avaavan napin kehykseen.
Haettu vastaus:
Vastaukseen haetaan yhtä koodiriviä joka lisää kehykseen napin, jonka tekstinä on merkkijono
"Ohje" ja jonka käsittelijäfunktio on ainoa koodista löytyvä funktio. Luotua nappia ei ole tarpeen sijoittaa muuttujaan!Resurssit:
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Laatikoita ja pakkaamista¶
Ennen syventymistä toimintojen toteuttamiseen käsittelijäfunktioilla on syytä tutkia miten käyttöliittymä määritellään ohjelmakoodilla. TKinter käyttää menetelmää, jossa käyttöliittymä voidaan jakaa kehyksiin ja varsinaisiin komponentteihin. Kehys on vähän kuin Pythonin
lista
, eli se voi sisältää muita komponentteja - myös muita kehyksiä. Asettelu perustuu pakkaamiseen jotain seinää vasten (tämä ei tosin ole ainoa vaihtoehto). Komponentille siis määritetään suunta, mihin se pyritään työntämään. Esimerkiksi jos komponentin pakkaussuunta on ylöspäin, se pyrkii olemaan niin ylhäällä kehyksessään kuin mahdollista. Komponentit pakataan lisäysjärjestyksessä, joten ensimmäisenä pakattu komponentti on lähimpänä sitä reunaa jota vasten se on pakattu, toisena pakattu tämän "päällä".
Yleisesti ottaen kaikki yhden kehyksen komponentit kannattaa pakata samaan suuntaan jotta käyttöliittymään ei jää hölmön näköisiä aukkoja. Yksinkertaisuuden nimissä käyttöliittymäkirjastomme pakkaa aina kehyksen sisällä olevat komponentit yläreunaa vasten - ainoastaan itse kehysten pakkausuuntaan voi vaikuttaa funktioiden argumenteilla. Kirjasto myös piilottaa joitain mahdollisia asetuksia joilla asetteluun voisi TKinterissä vaikuttaa, eli sitä minkä näköisiä käyttöliittymiä voidaan luoda on rajoitettu aika paljon. TKinter ei kyllä muutenkaan ole paras kirjasto, jos haluaa oikeasti hienon näköisiä käyttöliittymiä. Esim. PySide 2 kääntää huomattavasti monipuolisemman (ja monimutkaisemman) Qt-käyttöliittymäkirjaston Pythonille.
Alla on esitetty funktio, joka luo kokoelmaohjelman uuden hienon graafisen käyttöliittymän komponentit sekä kuva miltä tämä käyttöliittymä näyttää (Linuxilla). Koodiin on myös lisätty lopeta-funktio, joka toimii lopetusnapin
käsittelijänä
.import ikkunasto as ik
def lopeta():
ik.lopeta()
def luo_ikkuna():
ikkuna = ik.luo_ikkuna("Kokoelmaohjelma 0.1 alpha")
nappikehys = ik.luo_kehys(ikkuna, ik.VASEN)
kokoelmakehys = ik.luo_kehys(ikkuna, ik.VASEN)
latausnappi = ik.luo_nappi(nappikehys, "Lataa", lataa_kokoelma)
rakennusnappi = ik.luo_nappi(nappikehys, "Rakenna", rakenna_kokoelma)
tallennusnappi = ik.luo_nappi(nappikehys, "Tallenna", tallenna_kokoelma)
ik.luo_vaakaerotin(nappikehys, 5)
lisaysnappi = ik.luo_nappi(nappikehys, "Lisää", lisaa)
poistonappi = ik.luo_nappi(nappikehys, "Poista", poista)
muokkausnappi = ik.luo_nappi(nappikehys, "Muokkaa", muokkaa)
ik.luo_vaakaerotin(nappikehys, 5)
lopetusnappi = ik.luo_nappi(nappikehys, "Lopeta", lopeta)
kokoelmalaatikko = ik.luo_listalaatikko(kokoelmakehys)
ik.kaynnista()
if __name__ == "__main__":
#lahde, kohde = lue_argumentit(sys.argv)
try:
luo_ikkuna()
except KeyboardInterrupt:
print("Ohjelma keskeytettiin, kokoelmaa ei tallennettu")
Napinluontifunktiot ja muut pääasiassa kertovat palauttavansa
objektin
. Tällä hetkellä ne otetaan kaikki talteen muuttujiin
, jotta niihin voidaan viitata myöhemmin. Emme ole tosin vielä miettineet tarvitseeko niihin viitata. Kehyksiin kyllä selkeästi viitataan jo tämän funktion sisällä, mutta nappeihin ei. Erottimet taas eivät ole aktiivisia komponentteja, joten kirjasto ei edes vaivaudu palauttamaan niitä. Toinen huomio on, että koodi voidaan tällä hetkellä ajaa, mutta napit eivät pääasiassa toimi (paitsi lopetusnappi). Pääohjelmaa on muutettu kutsumaan luo_ikkuna-funktiota aiemman valikko-funktion sijaan, ja komentoriviargumenttien lukeminen on toistaiseksi kommentoitu ulos.Uudenlaista tiedonvälitystä¶
Syytä sille miksi napit eivät toimi ei tarvi etsiä kovin kaukaa. Ikkunaston luo_nappi-funktion
dokumenttimerkkijono
kertoo seuraavaa help-funktiolla katsottuna:luo_nappi(kehys, teksti, kasittelija)
Luo napin, jota käyttäjä voi painaa. Napit toimivat käsittelijäfunktioiden
kautta. Koodissasi tulee siis olla määriteltynä funktio, jota kutsutaan
aina kun käyttäjä painaa nappia. Tämä funktio ei saa lainkaan argumentteja.
Funktio annetaan tälle funktiokutsulle kasittelija-argumenttina. Esim.
def aasi_nappi_kasittelija():
# jotain tapahtuu
luo_nappi(kehys, "aasi", aasi_nappi_kasittelija)
Napit pakataan aina kehyksensä ylälaitaa vasten, joten ne tulevat näkyviin
käyttöliittymään alekkain. Jos haluat asetella napit jotenkin muuten, voit
katsoa tämän funktion koodista mallia ja toteuttaa vastaavan
toiminnallisuuden omassa koodissasi. Jos laajenna-argumentiksi annetaan
True, nappi käyttää kaiken jäljellä olevan tyhjän tilan kehyksestään.
:param widget kehys: kehys, jonka sisälle nappi sijoitetaan
:param str teksti: napissa näkyvä teksti
:param function kasittelija: funktio, jota kutsutaan kun nappia painetaan
:return: palauttaa luodun nappiobjektin
Käsittelijäfunktio
ei saa siis lainkaan argumentteja
, kun taas olemassaolevat funktiot
odottavat niitä saavansa. Niitä ei voi siis suoraan käyttää käsittelijöinä. Vanhoja funktioita ei välttämättä kannata alkaa heti purkamaan. Esim lataa_kokoelma tekee edelleen työnsä aivan hyvin. Sille pitää vain saada annettua kokoelmatiedoston polku
jotain muuta kautta. Hieman tutkimalla selviää, että ikkunastossa on oma funktio tiedostojen valitsemiselle: avaa_tiedostoikkuna. Muutetaan siis latausnapin käsittelijäksi uusi funktio, joka kutsuu lataa_kokoelma-funktiota saatuaan polun avaa_tiedostoikkuna-funktiolta. Vastaava voidaan tehdä kokoelman rakentamiselle (kumpikin avaa erilaisen valintaikkunan). Poistetaan myös input-funktiokutsu rakenna_kokoelma-funktiosta ja muutetaan kansio parametriksi
.def rakenna_kokoelma(kansio):
try:
kokoelma = nuuskija.lue_kokoelma(kansio)
except FileNotFoundError:
print("Kansiota ei löytynyt")
return kokoelma
def avaa_latausikkuna():
polku = ik.avaa_tiedostoikkuna("Valitse kokoelmatiedosto (JSON)")
kokoelma = lataa_kokoelma(polku)
def avaa_rakennusikkuna():
polku = ik.avaa_hakemistoikkuna("Valitse kokoelman juurikansio")
kokoelma = rakenna_kokoelma(polku)
Tässä on nyt tosin pienoinen ongelma: käsittelijäfunktio ei myöskään voi palauttaa mitään, joten miten kokoelma, joka nyt on paikallisessa muuttujassa, saadaan näkymään muualla ohjelmassa? Tässä auttaa palauttaa mieleen, että sekä
lista
että sanakirja
ovat muuntuvia
. Jos pääohjelmatasolla
on määritelty muuntuva objekti
, sitä voidaan käsitellä ohjelman kaikissa funktioissa. Tässä tapauksessa tehdään kaukaa viisaasti sanakirja, jonka avaimiin
voidaan sijoittaa muitakin objekteja joita saatetaan joutua jakamaan.komponentit = {
"kokoelma": []
}
Huomion arvoista on, että Pylint tulee valittamaan tästä (tosin tarkistimissa tämä valitus on otettu pois päältä), koska se pitää tätä sanakirjaa
vakiona
, koska se on määritelty pääohjelmassa. Tätä objektia on kuitenkin tarkoitus muutella suorituksen aikana, joten nimen kirjoittaminen isolla antaisi siitä väärän kuvan. Muutetaan lataus- ja rakennusfunktiot sijoittamaan kokoelma tähän sanakirjaan:def rakenna_kokoelma(kansio):
try:
komponentit["kokoelma"] = nuuskija.lue_kokoelma(kansio)
except FileNotFoundError:
print("Kansiota ei löytynyt")
def lataa_kokoelma(tiedosto):
try:
with open(tiedosto) as lahde:
komponentit["kokoelma"] = json.load(lahde)
except (IOError, json.JSONDecodeError):
print("Tiedoston avaaminen ei onnistunut. Aloitetaan tyhjällä kokoelmalla")
komponentit["kokoelma"] = []
def avaa_latausikkuna():
polku = ik.avaa_tiedostoikkuna("Valitse kokoelmatiedosto (JSON)")
lataa_kokoelma(polku)
tulosta(komponentit["kokoelma"])
def avaa_rakennusikkuna():
polku = ik.avaa_hakemistoikkuna("Valitse kokoelman juurikansio")
rakenna_kokoelma(polku)
tulosta(komponentit["kokoelma"])
Funktioista ovat poistuneet return-lauseet, joten myös vastaavat sijoitukset tulee poistaa. Kokoelma saadaan nyt siis ladattua (tai rakennettua), joten se pitäisi enää saada näkymään käyttöliittymässä. Tätä varten on olemasa lisaa_rivi_laatikkoon-funktio, mutta sille pitäisi antaa argumenttina laatikko, johon rivi lisätään, ja rivin sisältö. Tällä hetkellä laatikko on olemassa vain luo_ikkuna-funktiossa, joten se pitänee lisätä tähän uuteen sanakirjaan. Uudelleenkirjoitetaan tulosta-funktio siten, että se tulostaa terminaalin sijaan listalaatikkoon käyttöliittymässä.
def muotoile_rivi(levy, i):
return "{i:2}. {artisti} - {albumi} ({vuosi}) [{kpl_n}] [{kesto}]".format(
i=i,
artisti=levy["artisti"],
albumi=levy["albumi"],
kpl_n=levy["kpl_n"],
kesto=levy["kesto"].lstrip("0:"),
vuosi=levy["julkaisuvuosi"]
)
def tulosta(kokoelma):
for i, levy in enumerate(kokoelma):
ik.lisaa_rivi_laatikkoon(komponentit["laatikko"], muotoile_rivi(levy, i + 1))
Ikkunan luonnissa listalaatikko pitää tietenkin tallentaa sanakirjaan, mikä tehdään näin
komponentit["laatikko"] = ik.luo_listalaatikko(kokoelmakehys). Yksittäisen rivin muotoilu on omassa funktiossaan, koska ennakoimme, että sitä saattaa tarvita myös rivin päivittämiseen kun levyn tietoja muutetaan. Nyt saadaan aikaan kiva tulostus.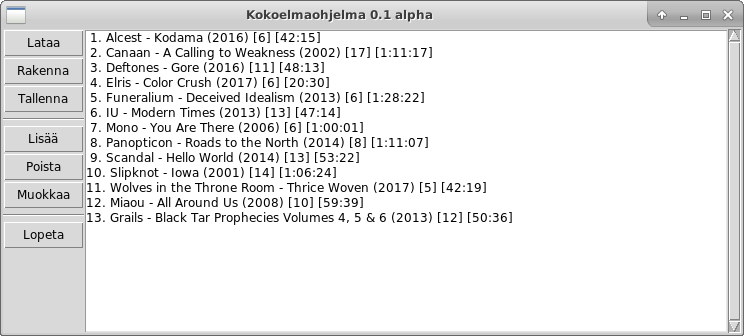
Ponnahtavia ikkunoita¶
Tässä osiossa on paljon koodia, mutta ei lopulta kovin montaa asiaa. Tavoitteena on saada levyjen lisäys toimimaan. Koska tämä tehtiin aiemmin
tekstisyötteillä
, muutoksia pitää tehdä aika laajasti. Ajatus on kuitenkin, että käyttöliittymän Lisää-napin painaminen avaisi erillisen ikkunan johon levyn tiedot voi syöttää. Levy tallennetaan kokoelmaan kun ikkuna suljetaan - jos tiedot ovat kelvollisia. Muuten avataan virheviesti-ikkuna ja annetaan käyttäjälle mahdollisuus korjata virhe.Kirjastosta löytyy muutama ali-ikkunoihin liittyvä
funktio
. Ali-ikkuna on siis tapa, jolla saadaan avattua toinen ikkuna pääikkunan päälle. Niihin voidaan sijoittaa kehyksiä ja komponentteja samalla tavalla kuin pääikkunaankin. Ali-ikkunan voi piilottaa ja tuoda esiin funktioilla. Hyvä tapa on siis luoda ikkuna heti ohjelman alussa, ja piilottaa se kun sitä ei tarvita. Tämä siis sen sijaan, että luotaisiin koko ikkuna joka kerta kokonaan uudestaan! Ikkuna sisältää tekstikenttiä ja niihin liittyviä otsikoita. Koko komeus luodaan luo_ikkuna-funktiossa:def luo_ikkuna():
# Pääikkunan luonti
ikkuna = ik.luo_ikkuna("Kokoelmaohjelma 0.1 alpha")
nappikehys = ik.luo_kehys(ikkuna, ik.VASEN)
kokoelmakehys = ik.luo_kehys(ikkuna, ik.VASEN)
latausnappi = ik.luo_nappi(nappikehys, "Lataa", avaa_latausikkuna)
rakennusnappi = ik.luo_nappi(nappikehys, "Rakenna", avaa_rakennusikkuna)
tallennusnappi = ik.luo_nappi(nappikehys, "Tallenna", avaa_tallennusikkuna)
ik.luo_vaakaerotin(nappikehys, 5)
lisaysnappi = ik.luo_nappi(nappikehys, "Lisää", avaa_lisayslomake)
poistonappi = ik.luo_nappi(nappikehys, "Poista", poista)
muokkausnappi = ik.luo_nappi(nappikehys, "Muokkaa", muokkaa)
ik.luo_vaakaerotin(nappikehys, 5)
lopetusnappi = ik.luo_nappi(nappikehys, "Lopeta", lopeta)
komponentit["laatikko"] = ik.luo_listalaatikko(kokoelmakehys)
# Ali-ikkunan luonti
levylomake = ik.luo_ali_ikkuna("Levyn tiedot")
kenttakehys = ik.luo_kehys(levylomake, ik.YLA)
nappikehys = ik.luo_kehys(levylomake, ik.YLA)
ohjekehys = ik.luo_kehys(kenttakehys, ik.VASEN)
syotekehys = ik.luo_kehys(kenttakehys, ik.VASEN)
ik.luo_tekstirivi(ohjekehys, "Artisti")
komponentit["lomake_artisti"] = ik.luo_tekstikentta(syotekehys)
ik.luo_tekstirivi(ohjekehys, "Albumi")
komponentit["lomake_albumi"] = ik.luo_tekstikentta(syotekehys)
ik.luo_tekstirivi(ohjekehys, "Kpl N")
komponentit["lomake_kpl_n"] = ik.luo_tekstikentta(syotekehys)
ik.luo_tekstirivi(ohjekehys, "Kesto (HH:MM:SS)")
komponentit["lomake_kesto"] = ik.luo_tekstikentta(syotekehys)
ik.luo_tekstirivi(ohjekehys, "Julkaisuvuosi")
komponentit["lomake_vuosi"] = ik.luo_tekstikentta(syotekehys)
ik.luo_nappi(nappikehys, "Tallenna", tallenna_lomake)
ik.piilota_ali_ikkuna(levylomake)
komponentit["levylomake"] = levylomake
ik.kaynnista()
Viittaukset lomakkeen kenttiin ja itse lomakkeeseen tarvitaan komponentit-
sanakirjaan
, jotta kenttien sisältö voidaan lukea muualla ohjelmassa, ja jotta ikkuna voidaan piilottaa sekä tuoda esiin. Samalla Lisää-napin käsittelijäfunktioksi
vaihdetaan uusi funktio, joka avaa lisäyslomakkeen. Vastaavasti tehdään myös tallennusnapille oma käsittelijä.def avaa_lisayslomake():
ik.nayta_ali_ikkuna(komponentit["levylomake"], "Lisää levy")
def tallenna_lomake():
ik.piilota_ali_ikkuna(komponentit["levylomake"])
Näillä eväillä lomake saadaan auki ja kiinni, joten voidaan katsoa miltä se näyttää. Ohjemerkkijonot eivät ihan osu kenttien kohdalle, mutta olkoot, niitä ei aleta tässä säätämään paikoilleen.
Seuraavaksi lomake pitäisi saada tekemään jotain. Tämä vaatii hieman päätöksentekoa ja suunnittelua. Olemme päättäneet käyttää samaa lomaketta lisäämiseen ja muokkaamiseen. Olemme myös päättäneet, että tallennus tehdään ikkunan sulkemisen yhteydessä (missäs muuallakaan?) Tieto siitä onko lomake avattu lisäystä vai muokkausta varten pitäisi siis jotenkin kuljettaa tallenna_lomake-funktiolle. Mekanismi on sama kuin se, millä kokoelmalistaa kuskataan pitkin ohjelman käsittelijäfunktioita: tungetaan tieto siitä mitä ollaan tekemässä
sanakirjaan
. Eritellään samalla kokoelma-lista ja tämä uusi informaatio toiseen sanakirjaan, ja jätetään komponentit-sanakirjaan pelkästään viittaukset varsinaisiin käyttöliittymäelementteihin.EI_VALITTU = 0
LISAA = 1
MUOKKAA = 2
komponentit = {
"laatikko": None,
"levylomake": None,
"lomake_artisti": None,
"lomake_albumi": None,
"lomake_kpl_n": None,
"lomake_kesto": None,
"lomake_julkaisuvuosi": None,
}
tila = {
"kokoelma": [],
"toiminto": EI_VALITTU
}
Toteutetaan eri toimintojen erottaminen
vakioilla
. Näiden numeroarvoilla ei ole merkitystä, mutta nimetyt numerot ovat tällaisen informaation esittämiseen kätevämpiä kuin merkkijonot
saati sitten paljaat numerot. Olemme myös tallentaneet komponenttisanakirjaan None jokaisen avaimen
kohdalle. Tämä ei ole pakollista, mutta tällä halutaan esittää heti ohjelman alussa mihin komponentteihin sanakirjan kautta voi viitata. Hyödyntäen tila-sanakirjassa olevaa toiminto-informaatiota voidaan jatkaa lomakkeen käsittelyä:def avaa_lisayslomake():
ik.nayta_ali_ikkuna(komponentit["levylomake"], "Lisää levy")
tila["toiminto"] = LISAA
def tallenna_lomake():
if tila["toiminto"] == LISAA:
onnistui = lisaa(tila["kokoelma"])
paikka = len(tila["kokoelma"]) - 1
elif tila["toiminto"] == MUOKKAA:
onnistui = muokkaa(tila["kokoelma"])
else:
return
if onnistui:
ik.lisaa_rivi_laatikkoon(
komponentit["laatikko"],
muotoile_rivi(tila["kokoelma"][paikka], paikka + 1), paikka
)
ik.tyhjaa_kentan_sisalto(komponentit["lomake_artisti"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_albumi"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_kpl_n"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_kesto"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_vuosi"])
ik.piilota_ali_ikkuna(komponentit["levylomake"])
tila["toiminto"] = EI_VALITTU
Toiminto siis asetetaan kun lomake avataan ja sen arvoa tarkastellaan kun lomake suljetaan Tallenna-napilla. Samalla tässä on tehty lomakkeen sulkemiseen liittyvää lisäkäsittelyä. Lomake halutaan sulkea vasta kun käyttäjä antoi oikeanlaista tietoa. Samalla halutaan myös pyyhkiä lomakkeen kentät tyhjiksi, jotta ne eivät ole siellä kummittelemassa seuraavalla avauskerralla. Onnistuneen tallennuksen tapahtuessa levy pitää lisätä myös käyttöliittymän listanäkymään. Toinen vaihtoehto olisi tietenkin tyhjentää koko lista ja kutsua tulosta-funktiota, joka tulostaisi koko kokoelman uudestaan, mutta tässä on aika paljon turhaa työtä. Varsinainen lisäysfunktio muuttuu itse asiassa vähän laajemmaksi rivien määrän puolesta.
def lisaa(kokoelma):
artisti = ik.lue_kentan_sisalto(komponentit["lomake_artisti"])
albumi = ik.lue_kentan_sisalto(komponentit["lomake_albumi"])
try:
n = int(ik.lue_kentan_sisalto(komponentit["lomake_kpl_n"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Kappaleiden lukumäärän on oltava kokonaisluku", virhe=True)
return False
try:
kesto = tarkista_kesto(ik.lue_kentan_sisalto(komponentit["lomake_kesto"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Keston on oltava muodossa HH:MM:SS", virhe=True)
return False
try:
vuosi = int(ik.lue_kentan_sisalto(komponentit["lomake_vuosi"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Julkaisuvuoden on oltava kokonaisluku", virhe=True)
return False
kokoelma.append({
"artisti": artisti,
"albumi": albumi,
"kpl_n": n,
"kesto": kesto,
"julkaisuvuosi": vuosi
})
return True
Syy on virheviesteissä: niissä halutaan nyt mainita erikseen missä kentässä virhe on, joten jokainen tarvii oman try-exceptin. Virheestä viestitään nyt kirjaston tarjoamalla viesti-ikkuna-toiminnolla, jolla voidaan tehdä erillisiä viesti-ikkunoita. Viimeinen argumentti, joka on selkeyden nimissä annettu
avainsana-argumenttina
kertoo kirjastolle, että ikkunassa tulisi käyttää virheestä kertovaa kuvaketta. Lomakkeen kentät saadaan luettua lue_kentan_sisalto-funktiolla, jota varten tarvitaan siis komponentit-sanakirjasta
viittaukset kenttiin - tämä siis palauttaa kentän sisällön merkkijonona. Huomattavaa on, että tarkista_kesto ei edelleenkään oikeasti tee mitään, mutta ainakin nyt se käsitellään mikäli joskus koittaa päivä jolloin se tekee jotain.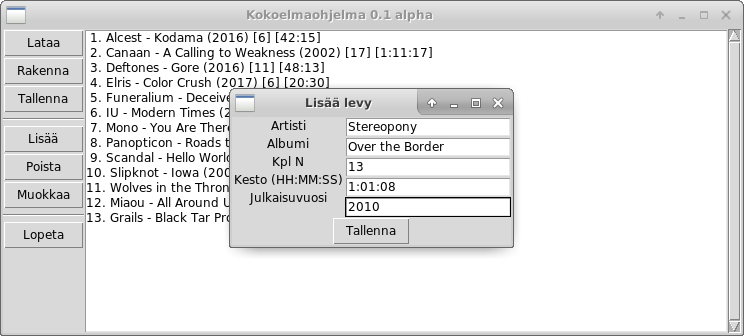
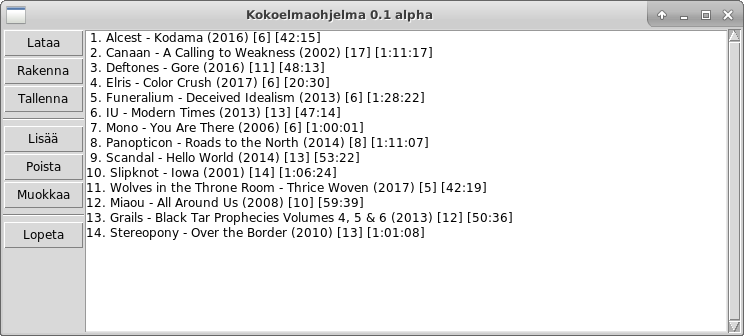
Helpotusta korjaustöihin¶
Levyjen poisto kokoelmasta oli aiemmin hyvin kankeaa: levyn valintaan vaadittiin, että käyttäjä kirjoitti sekä albumin että artistin nimen. Nykymaailmassa olisi kuitenkin mukavampaa, jos poistettavan levyn voisi valita suoraan klikkaamalla käyttöliittymässä olevasta luettelosta. Juuri tätä varten olemme käyttäneet pelkän tekstilaatikon sijaan listalaatikkoa, jossa jokainen rivi on klikattava kokonaisuus. Kirjastossa on tätä varten oma
funktio
lue_valittu_rivi. Funktio palauttaa valitun rivin (jos valittu) indeksin ja sisällön. Lisäksi kirjastossa on funktio rivin poistamiseen. Näin olleen poista-funktiosta tuleekin aiempaa huomattavasti yksinkertaisempi:def poista():
valittu, sisalto = ik.lue_valittu_rivi(komponentit["laatikko"])
if valittu != None:
tila["kokoelma"].pop(valittu)
ik.poista_rivi_laatikosta(komponentit["laatikko"], valittu)
Tässä käytetään nyt pop-
metodia
poistamaan alkio
listasta
, koska halutaan poistaa indeksin eikä sisällön perusteella. Todettakoon myös, että tämä metodi myös palauttaa poistamansa alkion - nyt sillä ei vain tehdä mitään. Viimeinen rivi puolestaan poistaa levyn käyttöliittymän listanäkymästä. Ainoaksi ongelmaksi jää se, että numerointiin tulee reikä. Asia korjataan tällä kertaa laiskasti, eli poistamalla numerointi kokoelman tulostuksesta. Jos numerointia ei poisteta, pitäisi kaikki poistokohdasta eteenpäin olevien levyjen tiedot tulostaa uudestaan. Tätä funktiota voidaan käyttää suoraan poistonapin käsittelijänä
.Levyn valintaa listalaatikosta voidaan käyttää myös muokkaamiseen. Tämä on yhdistelmä aiemmin tehtyä lisäystoimintoa, mistä lainataan muokkauslomake, sekä juuri tehtyä poistotoimintoa, josta lainataan levyn valinta. Tällä kertaa avataan sama ali-ikkuna kuin levyä lisätessä, mutta halutaan täyttää tekstikenttiin levyn olemassaolevat arvot. Lisäksi muokattu levy pitäisi saada näkymään vanhalla paikallaan eikä kokoelman lopussa. Kaiken kaikkiaan tässä tarvitaan jälleen kohtalaisesti päätöksentekoa siitä, mitä tapahtuu missä. Helpointa on lähteä liikkeelle siitä, miten lomake avataan:
def avaa_muokkauslomake():
paikka = kirjoita_tiedot_lomakkeeseen()
ik.nayta_ali_ikkuna(komponentit["levylomake"], "Muokkaa levyä")
tila["toiminto"] = MUOKKAA
tila["valittu"] = paikka
Lomake pitää täyttää tässä vaiheessa ennen kuin se näytetään. Tätä varten lie parasta tehdä erillinen funktio. Sovitaan myös, että valittu paikka listassa (eli levyn indeksi kokoelmassa) luetaan tuossa funktiossa ja palautetaan sieltä. Toinen tässä tehty päätös on tallettaa tila
sanakirjaan
valitun levyn indeksi. Tämä ihan vain siksi, että käyttäjä ei sotke kokoelmaa valitsemalla toisen levyn lomakkeen avaamisen jälkeen, jolloin uudet tiedot tallentuisivat väärän levyn päälle. Tuo mainittu uusi funktio näyttää tältä:def kirjoita_tiedot_lomakkeeseen():
valittu, sisalto = ik.lue_valittu_rivi(komponentit["laatikko"])
levy = tila["kokoelma"][valittu]
ik.kirjoita_tekstikenttaan(komponentit["lomake_artisti"], levy["artisti"])
ik.kirjoita_tekstikenttaan(komponentit["lomake_albumi"], levy["albumi"])
ik.kirjoita_tekstikenttaan(komponentit["lomake_kpl_n"], levy["kpl_n"])
ik.kirjoita_tekstikenttaan(komponentit["lomake_kesto"], levy["kesto"])
ik.kirjoita_tekstikenttaan(komponentit["lomake_vuosi"], levy["julkaisuvuosi"])
return valittu
Nyt lomake saadaan siis auki, ja sinne ilmestyvät valitun levyn tiedot muokkausta varten.
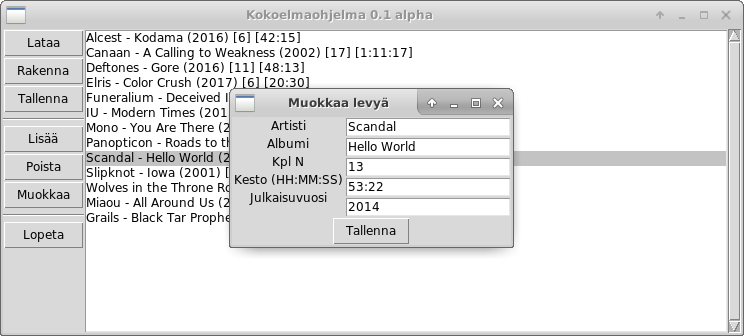
Lomakkeen tallennusnapin käsittelijä on jo olemassa lisäystoiminnon jäljiltä, mutta silloin tehty arvaus siitä miten muokkaus toimii ei ollut täysin riittävä. Tehdään siis hieman lisää töitä:
def tallenna_lomake():
if tila["toiminto"] == LISAA:
onnistui = lisaa(tila["kokoelma"])
paikka = len(tila["kokoelma"]) - 1
elif tila["toiminto"] == MUOKKAA:
paikka = tila["valittu"]
onnistui = muokkaa(tila["kokoelma"], paikka)
if onnistui:
ik.poista_rivi_laatikosta(komponentit["laatikko"], paikka)
tila["valittu"] = None
else:
return
if onnistui:
ik.lisaa_rivi_laatikkoon(
komponentit["laatikko"], muotoile_rivi(tila["kokoelma"][paikka]), paikka
)
ik.tyhjaa_kentan_sisalto(komponentit["lomake_artisti"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_albumi"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_kpl_n"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_kesto"])
ik.tyhjaa_kentan_sisalto(komponentit["lomake_vuosi"])
ik.piilota_ali_ikkuna(komponentit["levylomake"])
tila["toiminto"] = EI_VALITTU
Paikka päätettiin siis lukea siitä tilasanakirjan arvosta, joka asetettiin "valittu"-
avaimeen
kun lomake avatiin. Muokkauksen tekee varsinaisesti muokkaa-funktio. Jos se raportoi muokkauksen onnistuneen, poistetaan laatikosta vanha rivi, jotta sen paikalle voidaan tulostaa uudet tiedot. Varsinainen lisäys ei sen sijaan ole muuttunut, joten siltä osin funktion suunnittelussa onnistuttiin aiemmin. Jäljelle jää enää varsinaisen muokkaa-funktion toteutus:def lue_tiedot_lomakkeesta(levy):
levy["artisti"] = ik.lue_kentan_sisalto(komponentit["lomake_artisti"])
levy["albumi"] = ik.lue_kentan_sisalto(komponentit["lomake_albumi"])
try:
levy["kpl_n"] = int(ik.lue_kentan_sisalto(komponentit["lomake_kpl_n"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Kappaleiden lukumäärän on oltava kokonaisluku", virhe=True)
return None
try:
levy["kesto"] = tarkista_kesto(ik.lue_kentan_sisalto(komponentit["lomake_kesto"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Keston on oltava muodossa HH:MM:SS", virhe=True)
return None
try:
levy["julkaisuvuosi"] = int(ik.lue_kentan_sisalto(komponentit["lomake_vuosi"]))
except ValueError:
ik.avaa_viesti_ikkuna("Virhe tiedoissa", "Julkaisuvuoden on oltava kokonaisluku", virhe=True)
return None
return levy
def muokkaa(kokoelma, indeksi):
levy = lue_tiedot(kokoelma[indeksi].copy())
if levy:
kokoelma[indeksi] = levy
return True
return False
def lisaa(kokoelma):
levy = lue_tiedot_lomakkeesta({})
if levy:
kokoelma.append(levy)
return True
return False
Koska lisäys ja muokkaus molemmat tarvitsevat samanlaista lomakkeesta lukemista, siitä päätettiin tehdä oma funktio. Siksi alimpana näkyy myös miten lisaa-funktiota on muokattu käyttämään tätä uutta työkalua. Kaiken kaikkiaan kokoelmaohjelma näyttää lopulta tältä. Järjestämiseen liittyvät toiminnot jätettiin tällä kertaa toteuttamatta, koska tarkoitus oli pääasiassa näyttää miten funktioita sidotaan käyttöliittymäelementteihin. Vanha järjestysfunktio jää koodiin malliksi, josta sen voi halutessaan vaikka muokata toimimaan uuden käyttöliittymän kanssa... Yksi aika helppo tapa on tehdä jokaiselle sarakkeelle oma nappinsa, jota painamalla kokoelma järjestetään sen mukaan, ja uudestaan painamalla sama käänteisenä.
Lopullinen tiedosto, jota on vielä hieman siistitty Pylintin avulla (esim. poistettu turhat muuttujat ikkunan luonnista, koska nappeihin ei tarvi viitata niiden luomisen jälkeen).
Koko kurssin loppusanat¶
Neljä pitkää materiaalia myöhemmin olemme kulkeneet laskimen toiminnoista ohjelmiin, joiden toiminta lähentelee taikuutta. Parilla napinpainalluksella ohjelma löytää kaikkien levyjen tiedot kiintolevyn musiikkikokoelmasta – ominaisuus, joka on tarpeen mm. moderneissa soitto-ohjelmissa. Kaikkea tätä tehdessä meille paljastui, että lopulta kyse ei välttämättä ole tuhansista koodiriveistä tai edes erityisen vaikeista asioista. Kyse on vain siitä miten pienet palasevat vuoron perään loksahtelevat paikoilleen ja kasvattavat kokonaisuutta odottamattomiin mittoihin. Lopputulos voi tuntua taikuudelta, mutta kyseessä on kuitenkin vain puhdas, järjestelmällinen työprosessi. Tärkeintä on, että missään vaiheessa ei haukata liian suurta palaa.
Tietenkin esimerkkien työprosesseja lukiessa voi tuntua siltä, että vastaukset löytyvät vähän turhan helposti. Kyse ei kuitenkaan lopulta ole siitä miten nopeasti vastaukset löytyvät vaan siitä, että ymmärtää kysyä riittävän pieniä kysymyksiä. Silloin vastauksetkin ovat lyhyitä ja koodi jakaantuu melkein itsestään hallittavan kokoisiin paloihin. Jos katsoo esimerkkiohjelman koodia, pisinkin funktio on vain 40 riviä ja kaikki yksittäiset toiminnot ohjelmassa koostuvat lopulta aika yksinkertaisista rakenteista. Tietenkin on mahdollista mennä syvemmälle ja tehdä monimutkaisempaa koodia, mutta miksi vaivautua? Monimutkaisella koodilla voi tietenkin viihdyttää itseään, mutta tehokkaassa ohjelmoinnissa yksinkertaisuus on yleensä valttia.
Tämän viimeisen materiaalin asiat toimivat pitkälti täydennyksenä kolmen ensimmäisen tarjoamaan tiukkaan työkalupakkiin. Ilman moduuleja on vaikea tehdä mitään erityisen hyödyllistä koodia. Sen sijaan Pythonin sisäisillä moduuleilla pääsee monissa tapauksissa jo varsin pitkälle. Keinojen loppuessa kannattaa kuitenkin aina muistaa, että ongelmasi on todennäköisesti ratkaissut joku toinen, ellei kyseessä ole hyvin yksilöllinen tapaus. Tällöinkin kyseessä on yleensä erikoistapaus yleisemmästä ongelmasta jonka joku on jo ratkaissut. Tämä nähtiin materiaalin esimerkeissä: yhtä lailla tallennusratkaisuihin kuin musiikkitiedostojen metadatan lukemiseen löytyi valmiit palikat – toinen Pythonin sisältä ja toistakaan ei tarvinnut kaukaa etsiä.
Lopuksi nähtiin pieni kurkistus komentoriviohjelmointia nykyaikaisempaan ohjelmointiin. Tässä mentiin vähän alkeista ulos, mutta nykyaikana ilman ymmärrystä käsittelijäfunktioista ja kumppaneista ei oikeastaan pääse mihinkään. Toisaalta jos tietää niistä edes vähän, avautuvat monet ovet - moderneilla kirjastoilla pystyy alkeistiedoillakin tekemään nopeasti vaikuttavan näköistä jälkeä. Ylipäätään luovuuden tielle ei tule läheskään yhtä paljon toteutusyksityiskohtien miettimistä kuin silloin, jos yrittäisi tehdä itse kaiken alusta asti.
Materiaalien päättyessä jäljellä on enää viimeiset harjoitustehtävät ja tietenkin se lopputyö. Tässä vaiheessa eväät lopputyön tekemiseen on pitkälti annettu, ja alustavat suunnitelmatkin tehty. Toimimalla järjestelmällisesti lopputyön toteuttamisen ei pitäisi olla kenellekään mahdoton urakka. Toki se voi vaatia paljonkin työtä, jos jotkut vastaukset antavat odottaa itseään. Kunhan ei haukkaa liian suurta palaa kerralla, itsensä jalkaan ampumisen voi kuitenkin pitkälti välttää jolloin hidaskin edistys on kuitenkin taattua. Etenee vain suunnitelman mukaan, yksi pieni asia kerrallaan – ja joka vaiheessa muistaa kokeilla, että koodi toimii kuten sen ajattelee toimivan. Kun aina pääsee eteenpäin, maailman valloitus on ihan kulman takana.
Kuvalähteet¶
- alkuperäinen lisenssi: public domain (teksti lisätty)
- alkuperäinen lisenssi: CC-BY-NC 2.0 (teksti lisätty)
- alkuperäinen lisenssi: CC-BY-NC 2.0 (teksti lisätty)
- alkuperäinen lisenssi: CC-BY 2.0 (teksti lisätty)
- alkuperäinen lisenssi: public domain (teksti lisätty)
Anna palautetta
Kommentteja materiaalista?