In database terminology primary key refers to the column in a table that's intended to be the primary way of identifying rows. Each table must have exactly one, and it needs to be unique. This is usually some kind of a unique identifier associated with objects presented by the table, or if such an identifier doesn't exist simply a running ID number (which is incremented automatically).
Learning outcomes and material¶
During this exercise students will learn how to implement a RESTful clients and services that communicate with each other, and how to take advantage of hypermedia in that communication.
Introduction Lecture¶
Can be found here
Implementing Hypermedia Clients¶
In this final exercise we're visiting the other side of the API puzzle: the clients. We've been discussing the advantages
hypermedia
has for client developers for quite a bit. Now it's time to show how to actually implement these mythical clients. This exercise material has two parts: in the first one we make a fully automated machine client (Python script). In the second part we'll go over another means of communication between services using task queues with RabbitMQ.API Clients with Python¶
Our first client is a submission script that manages its local MP3 files and compares their metadata against ones stored in the API. If local files have data that the API is missing, it automatically adds that data. If there's a conflict it just notifies a human user about it and asks their opinion - this is not an AI course after all.
Learning goals: Using Python's requests library to make
HTTP requests
.Preparations¶
Another exercise, another set of Python modules. We're using Requests for making API calls. Another module that is used in the latter half of the exercise is Pika, a RabbitMQ library for Python. Installation into your virtual environment as usual.
pip install requests pip install pika
In order to test the examples in this material, you will need to run the MusicMeta API. By now we expect you to know how to do that. The code is unchanged from the end of the previous exercise, but is provided below for convenience.
Using Requests¶
The basic use of Requests is quite simple and very similar to using Flask's test client. The biggest obvious difference is that now we're actually making a
HTTP request
. Like the test client, Requests also has a function for each HTTP method
. These functions also take similar arguments: URL as a mandatory first argument, then keyword arguments like headers, params and data (for headers
, query parameters
and request body
respectively). It also has a keyword argument json as a shortcut or sending a Python dictionary as JSON. For example, to get artists collection:In [1]: import requests
In [2]: SERVER_URL = "http://localhost:5000"
In [3]: resp = requests.get(SERVER_URL + "/api/artists/")
In [4]: body = resp.json()
For another example, here is how to send a POST request, and read the Location header afterward:
In [5]: import json
In [6]: data = {"name": "PassCode", "location": "Osaka, JP"}
In [7]: resp = requests.post(SERVER_URL + "/api/artists/", json=data)
In [8]: resp.headers["Location"]
Out[8]: '/api/artists/passcode/'
Often when making requests using
hypermedia
controls the client should use the method included in the control
element. When doing this, using the request function is more convenient than using the method specific ones. Assuming we have the control as a dictionary called crtl:In [10]: resp = requests.request(ctrl["method"], SERVER_URL + ctrl["href"])
Using Requests Sessions¶
Our intended client is expected to call the API a lot. Requests offers sessions which can help improve the performance of the client by reusing TCP connections. It can also set persistent
headers
which is helpful in sending the Accept header, as well as authentication tokens for APIs that use them. Sessions should be used as context managers using with statement to ensure that the session is closed.In [1]: import requests
In [2]: SERVER_URL = "http://private-xxxxx-yourapiname.apiary-mock.com"
In [3]: with requests.Session() as s:
...: s.headers.update({"Accept": "application/vnd.mason+json"})
...: resp = s.get(SERVER_URL + "/api/artists/")
With this setup, when using the session object to send
HTTP requests
, all the session headers are automatically included. Any headers defined in the request method call are added on top of the session headers (taking precedence in case of conflict).Basic Client Actions¶
The client code we're about to see makes some relatively sane assumptions about the API. First of all, it works with the assumption that
link relations
that are promised in the API resource
state diagram are present in the representations sent by the API. Furthermore it trusts that the API will not send broken hypermedia
controls
or JSON schema
. It will also have issues if new mandatory fields are added for POST and PUT requests (but we'll make it easy to update in this regard).We're not going to show the full code here, only the parts that actually interact with the API (but you can download the full code later). Furthermore, while the client was tested with actual MP3 files, it might be easier for you to simply fake the tag data by creating a data class with necessary attributes, e.g. (only in Python 3.7. or newer)
from dataclasses import dataclass
@dataclass
class Tag:
title: str
album: str
track: int
year: str
disc: int
disc_total: int
In older Python versions you need to make a normal class and write the __init__ method yourself (data classes implement this kind of __init__ automatically).
class Tag:
def __init__(self, title, album, track, year, disc=1, disc_total=1):
self.title = title
self.album = album
self.track = track
self.disc = disc
self.disc_total = disc_total
self.year = year
Learning goals: How to navigate an API with an automated client, and send requests. Taking advantage of hypermedia to implement dynamic clients.
Client Workflow¶
The submission script works by going through the local collection with the following order of processing:
- check first artist
- check first album by first artist
- check each track on first album
- check second album by first artist
and so on, creating artists, albums and tracks as needed. It also compares data and submits differences. It trusts the local curator more than the API, always submitting the local side as the correct version. However when it doesn't have data for some field, it uses the API side value. Since MP3 files don't have metadata about artists, it uses "TBA" for the location field (because it is mandatory).
GETting What You Need¶
The key principles of navigating a
hypermedia
API are:- start at the entry point
- follow the link relationsthat will lead to your goal
This way your client doesn't give two hoots even if the API changed its
URIs
arbitrarily on a daily basis, as long as the resource state diagram remains unchanged. Our submission script needs to start at the artist collection. However, instead of starting the script with a GET to /api/artists/, it should start digging at the entry point /api/ and find the correct URI for the collection it's looking for by looking at the "href" attribute of the "mumeta:artists-all" control
.With this in mind, this is how the client should start its interaction with the API:
with requests.Session() as s:
s.headers.update({"Accept": "application/vnd.mason+json"})
resp = s.get(API_URL + "/api/")
if resp.status_code != 200:
print("Unable to access API.")
else:
body = resp.json()
artists_href = body["@controls"]["mumeta:artists-all"]["href"]
This is the only time the entry point is visited. From now on we'll be navigating with the link relations of
resource representations
(starting with the artist collection's representation). With the artist collection at hand, we can start to check artists from the local collection one by one.def check_artist(s, name, artists_href):
resp = s.get(API_URL + artists_href)
body = resp.json()
artist_href = find_artist_href(name, body["items"])
if artist_href is None:
artist_href = create_artist(s, name, body["@controls"]["mumeta:add-artist"])
resp = s.get(API_URL + artist_href)
body = resp.json()
albums_href = body["@controls"]["mumeta:albums-by"]["href"]
We've chosen to fetch the artist collection anew for each artist, for the off chance that the artist we're checking is added by another client while we were processing the previous one. The first order of things is to go through the "items" attribute and look if the artist is there. Remembering the non-uniqueness issue with artist names, our script falls back to the human user to make a decision in the event of finding more than one artist with the same name. Doing comparisons in lowercase avoids capitalization inconsistencies.
def find_artist_href(name, collection):
name = name.lower()
hits = []
for item in collection:
if item["name"].lower() == name:
hits.append(item)
if len(hits) == 1:
return hits[0]["@controls"]["self"]["href"]
elif len(hits) >= 2:
return prompt_artist_choice(hits)
else:
return None
Assuming we find the artist, we can now use the item's "self" link relation to proceed into the artist resource. This is only an intermediate step that is needed (according to the state diagram) in order to find the "mumeta:albums-by" control for this artist. This is the resource we need for checking the artist's albums. We have skipped exception handling because we trust the API to adhere to its own documentation (also for the sake of brevity).
Rat in the Maze¶
Hypermedia can also be used for dumb things like making mazes that can be navigated using link relations. Solving one with an automated client is good exercise, so we decided to do some cheese hiding into a rather large maze...
Learning goals: Making a
hypermedia
client that chains together GET requests using link relations
to find what it needs.What to do
We have an API server running in
https://pwpcourse.eu.pythonanywhere.com. Its media type is Mason. The server only has one resource, which only supports GET, and an entry point at /api/. The resource is a room, and it has two attributes:"handle": string, the room's unique identifier"content": string, possible values:""and"cheese"
In addition it can have up to four directional controls which represent transitions from one room to another. Corner rooms only have two, rooms along the edge only have three. The controls belong to the maze namespace.
"maze:north": head towards the wall; you probably know nothing"maze:south": head to warmer climates"maze:east": go towards the sunrise"maze:west": go west where the skies are blue
In addition the entry point has one control from the maze namespace:
"maze:entrance" which leads to the first room.Your quest is to find the cheese. The "maze" is just a square grid, but it has a lot of rooms. Unless you feel like clicking through thousands of links manually, using an automated machine client is recommended. When you find the cheese, remember to print out the room's handle - it's your answer to this task.
Your client needs some minimal intelligence so that it goes through the rooms in some logical order (e.g. one row at a time). Please make sure your client doesn't get stuck in infinite loops. Your client is sending actual network traffic - don't flood the API.
 Anna palautetta
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Schematic POSTing¶
When something doesn't exist, the submission script needs to obviously send it to the API. We're skipping ahead a bit to creating albums and tracks. For both the data comes from MP3 tags (for albums we take the first track's tag as the source). The POST
request body
for both can also be composed in a similar manner thanks to JSON schema
included in the hypermedia
control. The basic idea is to go through properties in the schema and for each property:- find the corresponding local value (i.e. MP3 tag field)
- convert the value into the correct format using the property's "type" and related fields (like "pattern" and "format" for strings)
- add the value to the message bodyusing the property name
In the event that a corresponding value is not found, the client can check whether that property is required. If it's not required, it can be safely skipped. Otherwise the client needs to figure out (or ask a human user) how to determine the correct value. We've chosen not to implement this part in the example though. It would be relevant only if the API added new attributes to its resources.
As a reminder of what it looks like, here's the "mumeta:add-album" control from the the albums collection
resource
:"mumeta:add-album": {
"href": "/api/artists/scandal/albums/",
"title": "Add a new album for this artist",
"encoding": "json",
"method": "POST",
"schema": {
"type": "object",
"properties": {
"title": {
"description": "Album title",
"type": "string"
},
"release": {
"description": "Release date",
"type": "string",
"pattern": "^[0-9]{4}-[01][0-9]-[0-3][0-9]$"
},
"genre": {
"description": "Album's genre(s)",
"type": "string"
},
"discs": {
"description": "Number of discs",
"type": "integer",
"default": 1
}
},
"required": ["title", "release"]
}
}
As it turns out, we only need one function for constructing POST requests for both albums and tracks:
def create_with_mapping(s, tag, ctrl, mapping):
body = {}
schema = ctrl["schema"]
for name, props in schema["properties"].items():
local_name = mapping[name]
value = getattr(tag, local_name)
if value is not None:
value = convert_value(value, props)
body[name] = value
resp = submit_data(s, ctrl, body)
if resp.status_code == 201:
return resp.headers["Location"]
else:
raise APIError(resp.status_code, resp.content)
In this function, tag is an object. In real use it's an instance of
tinytag.TinyTag, but can also be instance of the class Tag we showed earlier. The ctrl parameter is a dictionary picked from the resource's
controls
(e.g. "mumeta:add-album"). The mapping parameter is a dictionary with API side resource attribute names as keys and the corresponding MP3 tag fields as values. The knowledge of what goes where comes from reading the API's resource profiles
. As an implementaion note, we're also using the getattr function which is how object's attributes can be accessed using strings in Python (as opposed to normally being accessed as e.g. tag.album).The mapping dictionary for albums looks like this, where keys are API side names and values are names used in the tag objects.
API_TAG_ALBUM_MAPPING = {
"title": "album",
"discs": "disc_total",
"genre": "genre",
"release": "year",
}
Since all values are not stored in the same type or format as they are required to be in the request, the
convert_value function (shown below) takes care of conversion:def convert_value(value, schema_props):
if schema_props["type"] == "integer":
value = int(value)
elif schema_props["type"] == "string":
if schema_props.get("format") == "date":
value = make_iso_format_date(value)
elif schema_props.get("format") == "time":
value = make_iso_format_time(value)
return value
Finally, notice how we have put
submit_data as its own function? What's great about this function is that it works for all POST and PUT requests in the client. It looks like this:def submit_data(s, ctrl, data):
resp = s.request(
ctrl["method"],
API_URL + ctrl["href"],
data=json.dumps(data),
headers = {"Content-type": "application/json"}
)
return resp
Overall this solution is very dynamic. The client makes almost every decision using information it obtained from the API. The only thing we had to hardcode was the mapping of resource attribute names to MP3 tag field names. Everything else regarding how to construct the request is derived from the hypermedia control: what values to send; in what type/format; where to send the request and which HTTP method to use. Not only is this code resistant to changes in the API, it is also very reusable.
Of course if the control has "schemaUrl" instead of "schema", the additional step of obtaining the schema from the provided URL is needed, but is very simple to add.
To PUT or Not¶
When using dynamic code like the above example, editing a resource with PUT is a staggeringly similar act to creating a new one with POST. The bigger part of editing is actually figuring out if it's needed. Once again the core of this operation is the
schema
. One reason to use the schema instead of the resource representation's
attributes is that the attributes can contain derived attributes that should not be submitted in a PUT request (e.g. album resource does have "artist" attribute, but the value cannot be changed).In order to decide whether it should send a PUT request, the client needs to compare its local data against the data it obtained from the API regarding an album or a track. For comparisons to make sense, we need to once again figure out what are the corresponding local values, and convert them into the same type/format. This process is very similar to what we did in the
create_with_mapping function above, and in fact most of its code can be copied into a new function called compare_with_mapping:def compare_with_mapping(s, tag, body, schema, mapping):
edit = {}
change = False
for field, props in schema["properties"].items():
api_value = body[field]
local_name = mapping[field]
tag_value = getattr(tag, local_name)
if tag_value is not None:
tag_value = convert_value(tag_value, props)
if tag_value != api_value:
change = True
edit[field] = tag_value
continue
edit[field] = api_value
if change:
try:
ctrl = body["@controls"]["edit"]
except KeyError:
resp = s.get(API_URL + body["@controls"]["self"]["href"])
body = resp.json()
ctrl = body["@controls"]["edit"]
submit_data(s, ctrl, edit)
Overall this process looks very similar. There's just the added step of checking whether a field needs to be updated, and marking the change flag as True the first time a difference is discovered. Note also that for albums we're doing this comparison for the album resource, but for tracks we are actually doing it to track data that's in the album resource's "items" listing. This way we don't need to GET each individual track unless it needs to be updated. When this happens, we actually need to first GET the track and then find the edit
control
from there. This explains why we're not directly passing a control to this method, and also why finding the control at the end has the extra step if an edit control is not directly attached to the object we're comparing.Fun fact: if at a later stage the API developer chooses to add the edit control to each track item in the album resource, this code would find that, making the extra step unnecessary. Sometimes clients can apply logic to find a control that's not immediately available. Following the self
link relation
of an item in a collection is a good guess about where to find additional controls related to that item.A final reminder about PUT: remember that it must send the entire representation, not just the fields that have changed. The API should use the request body to replace the resource entirely. That is why we're always adding the API side value to fields when we don't have a new value for that field.
The Schemanator - Terminal Edition¶
Generic hypermedia clients are built on the idea that it's possible to fully interact with an API by generating a user interface using information provided by hypermedia controls. One part of this is prompting values for POST and PUT requests from the user by generating a form or similar from either a template or schema provided by the API. In this task you will do a simple command line version of a generic data prompt function.
Learning goals: How to make prompts and convert data based on
JSON schema
, fetching a schema from a schema URL, submitting a POST/PUT request.Before you begin:
You can use the
submit_data function from the submission script example as-is. The only difference is that the checker in task will provide complete URLs as the "href" attribute in controls. Therefore you should either remove the API_URL constant or set it to "" before submitting your answer.You should also download the latest version of the Sensorhub API and
run it
. This will help you in testing.Function to implement:
prompt_from_schema- Parameters:
- requests session object - you must use this object to make any requests
- Mason hypermedia control as a dictionary
The function should obtain the schema in one of two ways:
- if the control has a "schema" attribute, use that schema
- otherwise send a GET request to the URL specified in "schemaUrl" attribute and read the schema from the response with
.json()
Once it has a schema, it should ask the user to input all required values (using description as the input prompt), and convert these into correct types as specified in the schema. The types used in this exercise are "number", "integer" and "string". String formats or patterns are not used. Once the function has compiled the request data, it should send it to the API server using attributes from the hypermedia control. You can use the
submit_data function for this.You do not need to implement typechecking for the user's inputs - the checker will only give you valid inputs. You do need to prompt inputs in the order they appear in the "required" list though (inputs from the checker are given in this order). Use the builtin input function for making these prompts.
Testing your program
You can test this program against any API that uses Mason as its
media type
, you just have to check whether the API uses full URLs or omits the host part
. All of our examples omit it, which means you need to use the API_URL constant for the host part. Just remember to change it to an empty string before submitting your answer. Best way to do this is to set it to empty string at the beginning, and change its value to your test target in the main program portion of your module (as seen below). Here's a main program that you can use to test against the Sensorhub API, to create a sensor.
if __name__ == "__main__":
API_URL = "http://localhost:5000"
with requests.Session() as s:
resp = s.get(API_URL + "/api/sensors/")
body = resp.json()
prompt_from_schema(s, body["@controls"]["senhub:add-sensor"])
About the checker
This checker does not run an API server, but rather just uses objects that emulate just enough of the behavior of requests.Session and requests.Response to make it possible to check your function. They do not provide the full set of methods and attributes of these objects so try to stick to the basics shown in the examples (i.e. get, request, put and post for the Session and json and status_code for Response).
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Closing Remarks and Full Example¶
Although this was a specific example, it should give you a good idea about how to approach client development in general when accessing a
hypermedia
API: minimize assumptions and allow the API resource representations
to guide your client. When you need to hardcode logic, always base it on information from profiles
. Always avoid working around the API - workarounds often rely on features that are not officially supported by the API, and may stop working at any time when the API is updated. Having a client that adjusts itself to the API is also respectful towards the API developer, making the job of maintaining the API much easier when there aren't clients out there relying on ancient/unintended features.Here's the full example. If you want to run it without modifications, you need to actually have MP3 files with tag data that matches your Apiary documentation's examples. The submission script doesn't currently support VA albums.
TLS and Secrets Management¶
From this point on you will need to communicate with a RabbitMQ server. If you want to run the examples as they are, you need to have it running on your own computer. Simply installing and using default settings will be fine. However, we are also providing a live RabbitMQ server in the CSC cloud that you can use. Since it is publicly available, some measures are in place to increase security. First you will need some keys.
Using TLS¶
TLS (Transport Layer Security) is a rather important topic in the internet world as it is the vehicle that allows sending secrets like API keys encrypted. As there are other courses that will give you a much better understanding into what TLS involves, we will cover it rather briefly and mostly focus on what you need to know to access the course servers that use TLS. We are only covering this subject because without TLS, all traffic including keys and passwords would be plain text.
Generally speaking, when you connect to a server using TLS you obtain its certificate that has two purposes: 1) it can be used to verify that the server is who it says it is; 2) to encrypt communication between your client that holds the certificate, and the server that holds the corresponding private key. We are mostly interested in the latter part for the purposes of this course in order to keep things a little bit simpler.
Our servers are using self-generated certificates which means no client will trust them by default. This is more or less the only option because we do not have hostnames for them, only IPs. If you point a browser to the API you will get a warning along these lines:
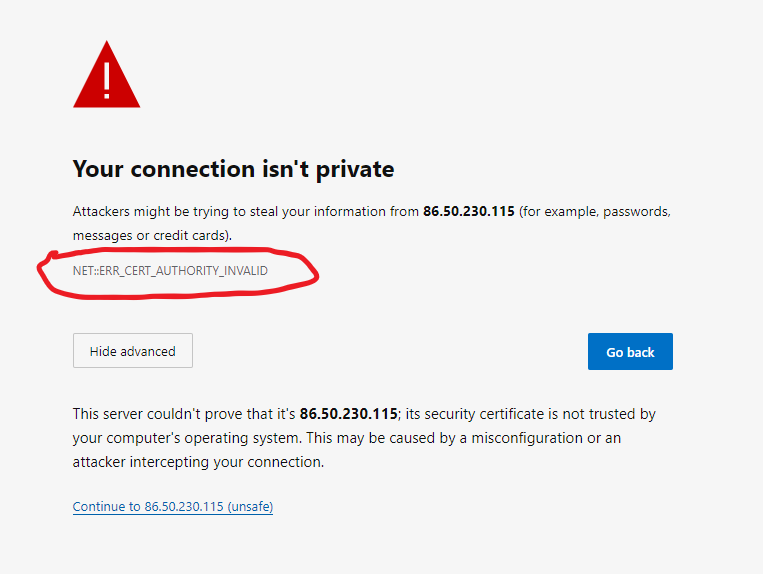
There are two ways around this implementing your own TLS clients: you can download the certificate and configure your client with it to make it trusted, or you can just instruct the client to ignore the issue. The latter option is not recommended in real life use cases, but we will go that way for simplicity's sake.
TLS with Requests¶
When using the Requests module, things are relatively straightforward as it basically handles everything. However it will give you an error if you try to connect to a server with a self-signed certificate and will drop the connection. To get around the issue, include the optional verify argument:
requests.get("https://some.whe.re/api/", verify=False)
This instructs requests to not verify the server's identity. Which by the way is a really bad idea if you are connecting to anything that has any sort of actual value. To the extent that you will get a warning every time you do it.
TLS with Pika¶
In order to configure Pika to connect with TLS, you need a little bit more work and the help of the built-in ssl module. Pika needs to be given an SSL context which you can build with the ssl module. In our case we are simply going to build a context that does essentially what
verify=False did for Requests. These three lines will prepare the context:import ssl
context = ssl.create_default_context()
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
Once you have your context, it is simply passed to the Pika connection along with your credentials. The following example assumes you have username, password, host, port, and vhost defined somewhere earlier in the file.
credentials = pika.PlainCredentials(username, password)
connection = pika.BlockingConnection(pika.ConnectionParameters(
host,
port,
vhost,
credentials,
ssl_options=pika.SSLOptions(context)
))
After this change to forming the connection, the rest of the examples work just like you were using a default RabbitMQ installation without credentials and TLS.
Managing Secrets¶
Before moving on we need to discuss the topic of how to make secrets available to your code. As code these days tends to end up in Github - particularly for your project - you should never include any credentials in your code. Not only is this incredible insecure, it also makes deployment harder. Generally speaking there are two primary ways to convey secrets to an application:
- Configuration files
- Environment variables
In some scenarios command line arguments and prompts can also be considered, but usually only for human users. When making automated machine clients, picking one of the two primary methods is recommended. In case of Flask, using a configuration file as explained in Flask API project example. For clients simply using requests you can make your own configuration file solution with e.g. Python's configparser, or use environment variables.
Environment variables are set with the set or export command depending on your operating system. Python access them through the environ dictionary in the os module, e.g.:
username = os.environ["PWP_RABBIT_USER"]
You can also remove the variable after retrieving provided unsetenv is supported on your system. This would be done just like removing and retrieving a key from any dictionary, with the pop method:
username = os.environ.pop("PWP_RABBIT_USER")
While the variable will still exist after you exit the application, it will not be available to any subprocesses etc. during the application's runtime so if you are doing something fun like, I don't know, running student code in order to check whether it's correct, it is probably a good idea to not let those processes access any important environment variables.
In general configuration files are easier to manage because with environment variables you still need to write them into the environment somehow, and this usually happens from a file so might as well use a configuration file at that point. The most important thing about configuration files is to just make sure they are only readable by the user your application is running as. While full web server setups usually use configuration files, in container deployments it can be more straightforward to configure the container launchup to write secrets into environment variables. Choose an approach that suits your needs.
Task Queues and Publish/Subscribe¶
Major part of the course has involved direct communication between the API and client where the client accesses the API through HTTP requests and gets mostly immediate responses. By that we mean the client expects to get whatever it was looking for as a direct response to its request. However, this is certainly not the only way of communication between services and clients or other services. In this last segment we are taking a peek at using task queues and publish/subscribe, two means of communication that are more asynchronous in nature.
This section will use RabbitMQ, a message broker commonly used to implement communication between services. We have provided you a running instance of RabbitMQ that you can access with credentials. You will be informed via course channels about how to get access. Feel free to use this instance to test examples, complete tasks, and implement these messaging protocols in your project if you want to go that way.
Our way of interacting with RabbitMQ is the Pika module which offers a Python interface for connecting to RabbitMQ.
Task Queues¶
Task queues are used to "place orders" for computational tasks that will be run by separate workers. Unlike API calls that would be targeted to a specific service by its address, tasks are sent to the message broker. As it is a queue, the first eligible worker to notice the message will undertake the task, marking it as being processed. They are generally used when you have lots of heavy tasks that can be run independently of each other, or tasks that need to be run in isolation. Worker pools are usually easy to scale as all a worker needs to do is connect to the message broker and it's ready to go. Usually workers don't have their own persistent storage.
For a real life example, Lovelace uses task queues when checking code submissions. This is a use case where task
queues fit like a glove:
queues fit like a glove:
- Each submission needs to be checked exactly once
- Each check is an independent operation
- Checking the submission is an expensive operation
- It also needs heavy isolation as we are running unknown code
- There is no need for persistent storage for the individual workers
Sensorhub Statistics¶
As to our code example, we're going to implement a feature to get statistics from a sensor. Because calculating statistics can be time-consuming, they will be calculated on separate workers. For the purposes of this example we are only calculating the mean value of measurements, but you could add all sorts of statistics without changes to the communication protocol. In our simple plan, only one set of stats will exist for a sensor at any given time. Here is a summary of how this will be implemented:
- We will have a new database model for sensor statistics on the API server
- We will add a new route,
/api/sensors/<sensor:sensor>/stats/, it supports GET, PUT, and DELETE - When a client sends a GET request to this resource, one of two things will happen:
- If there are existing statistics, they will be returned to the client (200)
- If there are no existing statistics, measurement data will be sent to the task queue for processing, and the client receives a 202 (Accepted) response to indicate that this resource is not yet available but will be in the future.
- When the worker has completed processing calculating statistics, it will send a PUT request with the statistics to the main API
- If a client wants to generate the stats again, they will first send DELETE to the stats resource, and then send a new GET request.
Download the API server example from below. Important changes are highlighted and explained in code snippets in the upcoming sections. If you want to test the code in your machine, be sure that you create and populate the database.
The full system that we are implementing in this material is presented by the diagram below. Details about each component can be found in the sections below. Our system will have one API server and one RabbitMQ server, but can have any number of workers and clients connected to it.
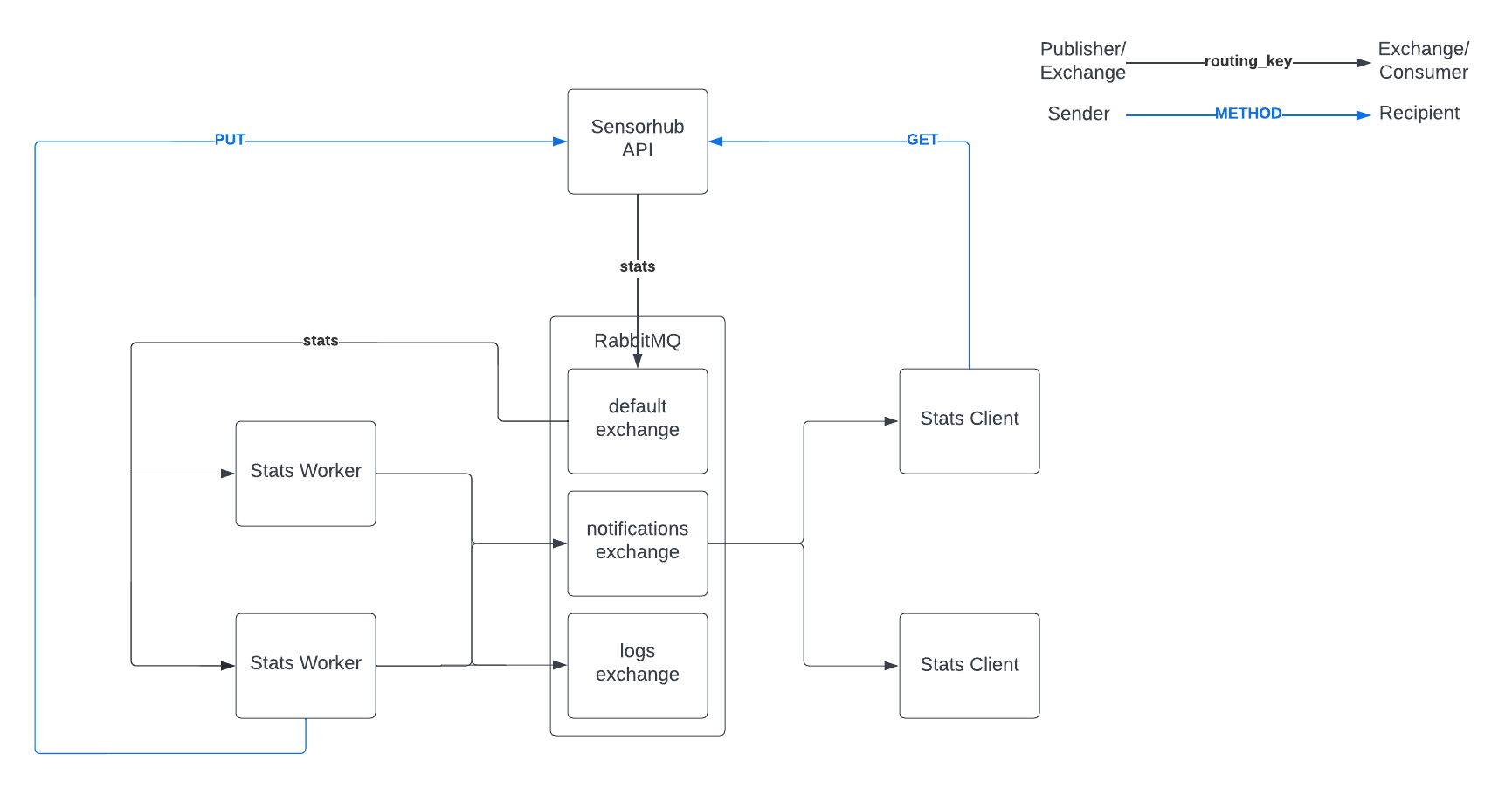
Statistics Model¶
The stats model doesn't have anything that wasn't covered in Exercise 1, but it's shown here to give you an idea what we are working with.
class Stats(db.Model):
id = db.Column(db.Integer, primary_key=True)
generated = db.Column(db.DateTime, nullable=False)
mean = db.Column(db.Float, nullable=False)
sensor_id = db.Column(
db.Integer,
db.ForeignKey("sensor.id"),
unique=True, nullable=False
)
sensor = db.relationship("Sensor", back_populates="stats")
It also has serialize, deserialize, and json_schema methods that are not shown here. A relationship pointing to this model will also be added to the Sensor model.
stats = db.relationship("Stats", back_populates="sensor", uselist=False)
Statistics Resource¶
The statistics resource will look like this.
class SensorStats(Resource):
def get(self, sensor):
if sensor.stats:
body = SensorhubBuilder(
generated=sensor.stats.generated.isoformat(),
mean=sensor.stats.mean
)
body.add_namespace("senhub", LINK_RELATIONS_URL)
body.add_control("self", api.url_for(SensorStats, sensor=sensor))
body.add_control("up", api.url_for(SensorItem, sensor=sensor))
body.add_control_delete_stats(sensor)
return Response(json.dumps(body, 200, mimetype=MASON)
else:
self._send_task(sensor)
return Response(status_code=202)
def put(self, sensor):
if not request.json:
raise UnsupportedMediaType
try:
validate(request.json, Stats.json_schema())
except ValidationError as e:
raise BadRequest(description=str(e))
stats = Stats()
stats.deserialize(request.json)
sensor.stats = stats
db.session.add(sensor)
db.session.commit()
return Response(status_code=204)
def delete(self, sensor):
db.session.delete(sensor.stats)
return Response(status_code=204)
There are mostly two things to note here. GET handling depends on whether stats currently exist or not - the mystery method _send_task will be called when stats are not available. We are using PUT to set the stats for the sensor regardless of whether they existed previously or not. This is done to deal with the situation where multiple GET requests are sent to the stats resource before the calculation service has finished processing. It will still result in stats being calculated multiple times, but we will only have one result at the end (the latest one). This issue could be addressed by adding suitable model class fields and logic to mark sensor's stats as being processed.
Sending Tasks¶
The process of sending a task has the following steps:
- Gather the data to be sent
- Form a connection to the RabbitMQ broker and get a channel object
- Declare a queue
- Send the task to the declared queue
The worker is going to need two pieces of information to complete its task: list of measurement values, and how to send the results back. The data can be obtained easily by forming a list of measurement values from the sensor's measurements relationship (this could be done in a more optimized manner, but we're keeping it simple). We also already have an answer for the latter part: we can include a hypermedia control in the payload. We'll also add the sensor's name (unique) for quick identification purposes later. With these things in mind we can look at the _send_task method.
def _send_task(self, sensor):
# get sensor measurements, values only
body = SensorhubBuilder(
data=[meas.value for meas in sensor.measurements],
sensor=sensor.name
)
body.add_control_modify_stats(sensor)
# form a connection, open channel and declare a queue
connection = pika.BlockingConnection(
pika.ConnectionParameters(app.config["RABBITMQ_BROKER_ADDR"])
)
channel = connection.channel()
channel.queue_declare(queue="stats")
# publish message (task) to the default exchange
channel.basic_publish(
exchange="",
routing_key="stats",
body=json.dumps(body)
)
connection.close()
We are using the default exchange here to make the example simple. It allows us to declare queues freely. The queue name "stats" is given as routing_key argument to basic_publish. This will publish the message to the "stats" queue so that it can be picked up by workers who are consuming the "stats" queue. In order to be more efficient with connections, the middle part could be done on module level only once.
With this our API side is ready. It will now send requests for stats to the queue. You can already run the server and visit any stats URL. However, as there are no consumers for the queue, the task will simply sit there until a consumer shows up.
Statistic Worker¶
Next step is implementing the worker that consumes the task queue. To keep the example simple, this will be a Python program that runs from the command line and keeps serving until it is terminated with Ctrl-C. The workflow is roughly:
- Define a handler function for received tasks
- Connect to the RabbitMQ server and get a channel
- Declare the "stats" queue
- Enter the consuming loop to serve tasks
Once a task comes in, the following will occur:
- Check that the task has all we need (data and "edit" control)
- Calculate the stats and add a timestamp
- Use the hypermedia control "edit" to check where and how to send the stats
- Regardless of result, acknowledge the task as completed
In the first implementation round we won't implement handling for errors. All tasks will be acknowledged regardless of result because we don't want them to go back to the queue. For istance, if we were to receive a task without a usable "edit" control, the task simply cannot be completed, and returning it to the queue would be pointless. In the second implementation round we will add a mechanism to notify other parts of the system that there was a failure in comleting the task.
The full code is available below. Note that it includes the second implementation round additions as well. The example snippets below will only have
pass in these spots.Setting Up and Running¶
First we are going to look at the main function that will connect to the message broker, and start consuming the "stats" queue. Most of this is quite similar to what we did on the sending end in the API side. Prints in this and other functions are simply there to make it easier to follow what is going on. In real life these should be replaced by using the logging module or other logging facilities.
def main():
connection = pika.BlockingConnection(pika.ConnectionParameters(BROKER_ADDR))
channel = connection.channel()
channel.queue_declare(queue="stats")
channel.basic_consume(queue="stats", on_message_callback=handle_task)
print("Service started")
channel.start_consuming()
The call to basic_consume is where we configure what queue will be consumed and how this worker will handle tasks. Note that we are not using auto_ack because we want to be sure our tasks are not lost in void if the worker dies or falls off the network in the middle of processing. This means the task handler needs to acknowledge the message when it has finished processing. With this setup we are ready to implement the actual logic for handling tasks.
Task Handler¶
The task handler in this case is the function that is responsible for parsing the task from the received message, calculating the statistics, and sending the response back in the designated manner (a PUT request to the address included in the message). If our workers handled more than one type of task, this function's role would be to parse the task and call the appropriate processing function. The code is presented below with comments for handling steps.
def handle_task(channel, method, properties, body):
print("Handling task")
try:
# try to parse data and return address from the message body
task = json.loads(body)
data = task["data"]
sensor = task["sensor"]
href = task["@controls"]["edit"]["href"]
except KeyError as e:
# log error
print(e)
else:
# calculate stats
stats = calculate_stats(task["data"])
stats["generated"] = datetime.now().isoformat()
# send the results back to the API
with requests.Session() as session:
resp = session.put(
API_SERVER + href,
json=stats
)
if resp.status_code != 204:
# log error
print("Failed PUT")
else:
print("Stats updated")
finally:
# acknowledge the task regardless of outcome
print("Task handled")
channel.basic_ack(delivery_tag=method.delivery_tag)
To keep this example easier to follow, the only thing we dig from the hypermedia control is the "href" for the address. The rest of how to send data back is hardcoded into this function. We set the call to the statistics function in a way that it returns a dictionary of whatever stats it was able to calculate, and we add a timestamp afterward. The data is sent back to the API with a PUT request as we designed. Also like we discussed earlier, there's a
finally clause in the try structure that will, regardless of what happens, always acknowledge the message.With this we have a fully operational system where clients can now request stats from the API, and those stats will be generated by the worker. However, if we have really heavy calculations that can take a long time, how would the client know when to check back? Similarly, how will the rest of the system know if something went wrong so that developers can start working on how to fix it?
Publish / Subscribe¶
The other topic of this material is broadcasting with publish / subscribe. Whereas with task queues only one recipient will consume the message, in publish / subscribe the message will be delivered to all consumers. This communication method is useful when sending events to the system in situations where we do not know the exact recipient, and/or there is multiple of them. In our example we can use it in two ways:
- We can broadcast an event when statistics calculation has been completed, and this can be picked up by some notification service to let the user know that the statistics they ordered are ready.
- We can broadcast log events so that system admins can notice problems
We can achieve this by creating two exchanges with the fanout type: one for notifications and one for logs. Services that are interested in those can then listen on the exchange of their choice.
Changes to Worker¶
The worker will need a couple of changes to fulfill these new requirements. The file provided earlier has these changes already included.
Setting Up Exchanges¶
First we need to introduce the exchanges in our main function. We also need to make the channel globally available. We're just going to be lazy and use the
global keyword to achieve this, but generally it would be better to e.g. turn the worker into a class. The changed main function is shown belowdef main():
global channel
connection = pika.BlockingConnection(pika.ConnectionParameters(BROKER_ADDR))
channel = connection.channel()
channel.exchange_declare(
exchange="notifications",
exchange_type="fanout"
)
channel.exchange_declare(
exchange="logs",
exchange_type="fanout"
)
channel.queue_declare(queue="stats")
channel.basic_consume(queue="stats", on_message_callback=handle_task)
print("Service started")
channel.start_consuming()
Besides adding the exchanges, the rest is the same. Declaring these new exchanges doesn't interfere with the previous functionality in any way. Also just like queues, exchange declarations are idempotent, and should be declared at both ends.
Broadcast Functions¶
Once we have the exchanges, we can write functions that will publish to them. We'll make one for the notifications, and another one for logs. The same basic_publish method that was used on the API side to send the task is also used here, but this time we are providing the exchange argument instead of routing_key.
def send_notification(href, sensor):
channel.basic_publish(
exchange="notifications",
routing_key="",
body=json.dumps({
"task": "statistics",
"sensor": sensor,
"@namespaces": {
"senhub": {"name": API_SERVER + LINK_RELATIONS}
},
"@controls": {
"senhub:stats": {
"href": href,
"title": "View stats"
}
}
})
)
def log_error(message):
channel.basic_publish(
exchange="logs",
routing_key="",
body=json.dumps({
"timestamp": datetime.now().isoformat(),
"content": message
})
)
For consistency we are once again using Mason in the notifications to include a control for accessing the statistics. The worker knows the URI because it just performed a PUT request to the same address. After these functions are in place, all that's left is to replace some of the prints with calls to these functions, which you can see in the final code.
Client Example¶
For the client we are going to make one important shortcut: the client will be allowed to connect and listen on the notifications exchange directly. In a real setup we probably should not be doing this directly, but we are already running three Python programs when we're done, and don't want to add any more intermediate steps to this example. We are going to implement a very simple client. It's going to take a sensor's name as command line argument, send a request to stats and then print them out when they are ready.
Requesting Stats¶
The core function is the one that requests stats from the API. This function can do one of two things when it receives a successful response (i.e. in the 200 range):
- on 200: print out the statistics
- on 202: open a connection to the message broker and wait for a notification
def request_stats(sensor):
with requests.Session() as session:
stats_url = API_SERVER + f"/api/sensors/{sensor}/stats/"
resp = session.get(
stats_url
)
if resp.status_code == 200:
print(resp.json())
elif resp.status_code == 202:
try:
listen_notifications()
except StopListening:
sys.exit(0)
else:
print(f"Response {resp.status_code}")
In order to keep this shorter and focus on what's important, we did not discover the stats URL via the API's hypermedia like we did in Exercise 4. Under the
elif branch we go into the listen mode by calling a function which we'll introduce next. This is also done under a try statement that catches a custom exception which we can use inside the handling logic to notify that we are done listening.Listening In¶
In order to listen to notifications, the client needs to undergo a setup process that is quite similar to the one done by the stats worker. There's just a couple key differences because we are listening in on a fanout type exchange.
- We need to declare the exchange
- We want to create a new queue that is exclusively used by this client
This is almost directly from the third RabbitMQ tutorial:
def listen_notifications():
connection = pika.BlockingConnection(pika.ConnectionParameters(BROKER_ADDR))
channel = connection.channel()
channel.exchange_declare(
exchange="notifications",
exchange_type="fanout"
)
result = channel.queue_declare(queue="", exclusive=True)
channel.queue_bind(
exchange="notifications",
queue=result.method.queue
)
channel.basic_consume(
queue=result.method.queue,
on_message_callback=notification_handler,
auto_ack=True
)
channel.start_consuming()
When we declare a queue without a name, RabbitMQ will generate a queue name for us. Also if it's set to exclusive, it tells RabbitMQ to delete the queue once we disconnect from it. The generated name is available through the response we get from queue_declare. Using that we can bind the queue to the "notifications" exchange. After that we just need to start consuming, and pass any notifications in the channel to our handler.
Handling Notifications¶
When a notification is received, the client needs to check that it's valid, and then determine if it was the notification we are looking for. In our current designs nofitications for all sensors are sent through the same exchange with no routing key, so it's up to the consumer to figure out if it is interested in the notification. Once we get notification for the sensor we requested stats for, the client can send a new GET request to the API to retrieve the stats. The notification handler code is shown below:
def notification_handler(ch, method, properties, body):
try:
data = json.loads(body)
href = data["@controls"]["senhub:stats"]["href"]
notification_for = data["sensor"]
except (KeyError, json.JSONDecodeError) as e:
print(e)
raise StopListening
else:
if notification_for == sensor:
with requests.Session() as session:
resp = session.get(href)
if resp.status_code == 200:
print(resp.json())
else:
print(f"Response {resp.status_code}")
raise StopListening
The sensor variable comes from the module level - it was set when we read its value from sys.argv. As discussed previously, this function can raise StopListening exception when either an error is encountered, or we have successfully obtained the stats that were initially requested.
Anna palautetta
Kommentteja materiaalista?