Rinnakkaislaskenta¶
Osaamistavoitteet: Erilaisia tapoja toteuttaa rinnakkaislaskentaa moderneissa suorittimissa.
Prosessorin ja muistin sisäisen toiminnan optimoinnin ohella suoritustehoa haetaan nykyään rinnakkaislaskennan avulla, missä ajatus on että ohjelma tai prosessi jaetaan usean suorittimen tai ytimen (engl. core) kesken, jotka suorittavat ohjelmakoodia yhtäaikaisesti ja synkronoidusti.
Tämä luo myös haasteita ohjelmointiin, koska ohjelmat tulisi laatia siten, että niiden suorituksessa voidaan hyödyntää useita ytimiä. Eli ohjelma olisi voitava jakaa osiin, jotka minimaalisesti riippuvat toisistaan ja minomoivat data- ja kontrollihasardit. Nykyään on jo olemassa rinnakkaislaskentaa tukevia ohjelmointikieliä tai rinnakkais-laajennuksia olemassaoleviin kieliin.
Modernit kääntäjät ja suorittimet osaavat optimoida ohjelmakoodia niin, että rinnakkaisuuden toteuttaminen on mahdollista niiden yhteispelillä. Kääntäjä voi jo optimoida ohjelmaa valitulle suorittimelle, esimerkiksi hoitamalla löydetyt data- ja kontrollihasardit sekä arvioimalla mitkä käskyt voidaan milloinkin suorittaa (engl. prediction / speculation). Nyt, moderrni kääntäjä voi siis lisätä käskyjä ohjelmaan (esim. nop) tai järjestellä ohjelman käskyt uuteen suoritusjärjestykseen! Kääntäjä voi jopa toteuttaa ohjelmakoodiin valmiiksi erilaisia ohjelman suoritushaaroja, jotka suoritetaan sen mukaan toteutuiko ennustus.. Näin osa riippuvuuksista eliminoituu jo käännösvaiheessa, hasardeihin yritetään reagoida jo valmiiksi ja tätä myöten suoritusteho kasvaisi.
Käännöksen aikainen optimointi on staattista, eli sisäänrakennettu ohjelmaan, jonka lisäksi suoritin voi ajonaikana dynaamisesti optimoida suoritusta kontrollilogiikkansa avulla. Suoritin esimeriksi määrittää kuinka monta käskyä voidaan suorittaa yhden kellojakson aikana tai mitkä käskyt suoritetaan missä kellojaksossa (engl. out-of-order execution), huomioiden tietysti riippuvuudet. Aiemmassa materiaalissa esittelemämme liukuhihntatoteutus on in-order pipeline, koska siinä käskyt suoritetaan ohjelmoidussa järjestyksessä.
Käskytason rinnakkaisuus¶
Kun konekielisen ohjelman käskyjä suoritetaan rinnakkain suorittimessa, puhutaan yleisesti käskytason rinnakkaisuudesta (engl. instruction-level parallelism, ILP), jossa suorittimen mikroarkkitehtuuriin toteutetaan erilaisia optimointitekniikoita.
Liukuhihnasuoritin jo osaltaan toteuttaa käskytason rinnakkaisuutta, kun useampi käsky on yhtaikaa suoritettavana eri osajärjestelmissä. Kuten aiemmin todettu, liukuhihnan suoritustehoa voidaan kasvattaa lisäämällä vaiheita liukuhihnaan. Vaiheita saadaan lisää purkamalla osajärjestelmät pienempiin ja nopeampiin osiin, jolloin kellojakson pituutta voidaan lyhentää ja tuloksena suoritusteho (IPS) kasvaa.
Toinen tapa on lisätä suorittimeen rinnakkaisia osajärjestelmiä, jolloin usea käsky voi olla liukuhihnalla samassa vaiheessa omassa osajärjestelmä-komponentissaan (engl. superscalar processor). Tässä konseptuaalisesti oletuksena on, että käskyt ja data tulevat samasta virrasta. Superskalaarissa prosessorissa voi olla esimerkiksi neljä ALUa, mutta liukuhihnalla suoritetaan rinnakkain erityyppisiä käskyjä. Kuvassa esimerkkinä ALU- ja muistiosoitus operaatiot.
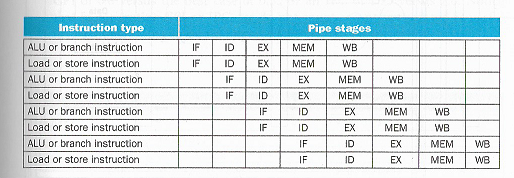
Näiden suoritinarkkitehtuurien yhteydessä puhutaan VLIW-käskykannasta (engl. very long instruction word). VLIW-käskyt on tyypillisesti hyvin pitkiä (jopa 128 bittiä), koska niissä on kuvattu usean eri käskyn operaatiokoodit ja operandit.
Käskyjen jako rinnakkaisille hihnoille on mahdollista tehdä jo kääntäjässä, jolla saadaan se hyöty, että eri suoritusosien digitaalilogiikan toteutus yksinkertaistuu. Mutta, hasardien käsittely on sitten taas monimutkaisempaa. Näin ollen, VLIW-suorittimet eivät useinkaan ole yleiskäyttöisiä vaan sovelluskohtaisia, esimerkiksi DSP-prosessorit.
Yleisesti moderneissa suorittimissa liukuhihnalla voi, kun otetaan usea eri optimointitekniikka käytäntöön, olla samanaikaisesti kymmeniä eri käskyjä suorituksen eri vaiheissa!
Moderni toteutus¶
Kuvassa alla käskytason rinnakkaisuutta toteuttavan modernin suorittimen arkkitehtuuri, jossa käskyjä ajetaan optimoidussa järjestyksessä (out-of-order execution).
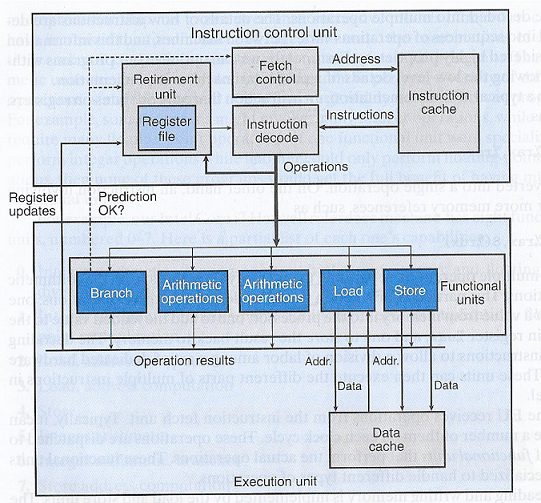
Kuten nähdään suoritin on jaettu kahteen osaan: kontrolli- (instruction control unit) ja suoritusyksikköön (execution unit). Kontrolliyksikkö lukee käskyt erillisestä välimuistista (instruction cache). Koska kontrolliosa toteuttaa ennustamisen (branch prediction ja speculation Fetch control-komponentissa, on sen toteutus varsin monimutkainen, ja tyypillisesti käskyt haetaan välimuistista hyvissä ajoin. Decode-komponentti taas purkaa käskyt yleensä mikro-operaatioiksi, jotta ne voidaan suorittaa monivaiheisemmassa likuhihnassa. Kontrolliosassa on vielä eläköitymisyksikkö (hieno suomennos eikös? engl. retirement unit), jonka tehtävänä on huolehtia että ohjelma kokonaisuutena suoritetaan halutussa loogisessa järjestyksessä. Tämä yksikkö myös päivittää käskyjen tulokset rekistereihin, kun ne on saatu liukuhihnasta läpi tai vastaavasti, jos ennustus meni pieleen, tyhjentää puskurista väärät tulokset.
Suoritusyksikkö jakaantuu sitten toiminnallisiin yksiköihin, joista jokainen on erikoistunut suorittamaan tietyntyyppiset käskyt: ALUn operaatiot, ohjelman kontrollikäskyt ja muistiosoitukset.
Moniydinprosessorit¶
Seuraava askel rinnakkaisuuden toteuttamisesta abstraktiotasolla ylöspäin on tehtävä- tai prosessitason rinnakkaisuuden toteuttaminen. Tavoitteena on kasvattaa prosessien suoritustehoa moniajoa tukevissa tietokoneissa tai palvelimissa, joissa prosessit voidaan jakaa usealle ytimelle yhtaikaa suoritettavaksi. Tällöin puhutaan moniydin-suorittimista.
Moniydin-prosessoreissa ohjelmien suorituksen hallinta ja optimointi on sitten jo varsin haastavaa. Joudutaan huomioimaan mm. ohjelman jakaminen rinnakkaisiin osiin, niiden suoritusjärjestys (engl. scheduling), tehtävien suorituksen synkronointi ja suorituskuorman jakaminen ydinten kesken. Ytimet myös kommunikoivat keskenään. Tämän tason rinnakkaisuus vaatii myös ohjelmoijalta rinnakkaisuuden sisäänrakentamista ohjelmiin. Lähtökohtaisesti sekventiaalinen ohjelman suoritus on todella hidasta nykyteknologialla..
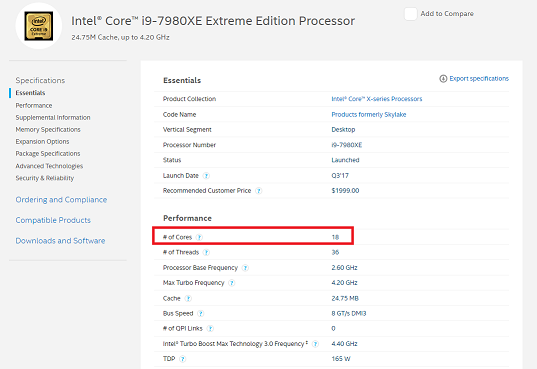
Esimerkkinä tuoreessa Intel Core i9-suoritinperheen prossuissa on jopa 18 ydintä!
Moniydin-keskusyksikköjen toteutukset ovat jaettu konseptuaalisesti neljään ryhmään datavirtojen ja käskyvirtojen määrän perusteella.
SISD¶
SISD (Single instruction stream, single data stream) tarkoittaa perinteistä tietokonetta, jossa yksi ydin suorittaa käskyn sen operandeille jotka ovat peräisin yhdestä datavirrasta.
Esimerkki SISD-prosessorista on Intel Pentium 4 vuodelta 2000.
SIMD¶
SIMD (Single instruction stream, multiple data streams) toteutuksessa on yksi suoritin, jolle data tuodaan 1-ulotteisessa vektorimuodossa (rivinä). Yksi SIMD-käsky suorittaa saman operaation kaikille vektorin alkiolle yhtaikaa. Näinollen, SIMD-toteutus tarvitsee vain yhden PC-rekisterin ja siihen liittyvän kontrollilogiikan, mutta paljon datarekistereitä. Esimerkkinä, taulukkojen käsittely voidaan toteuttaa nopeasti SIMD-käskyllä. Mutta SIMD toimisi tehottomasti ehtolauseissa.
SIMD toteuttaa yleisen vektoriarkkitehtuurin, jossa liukuhihnoitettu ALU (tai useampi rinnakkainen ALU) tekee operaatiot sekventiaalisesti 1-ulotteiselle datataulukolle yhden käskysyklin aikana. Vektoriprosessorin konekielen käskykannassa on erilliset vektori-käskyt, esimerkiksi voidaan lisätä numeroarvon vektorin kaikkiin alkioihin kerralla tai jokainen alkio voidaan kertoa samalla luvulla, jne. Tehokas ohjelman suoritus edellyttää että käytettävissä on riittävästi rekistereitä datavektorin sijoittamiseksi kokonaisuudessaan rekistereihin. Tehokkuutta tulee myös siitä, että vektori haetaan muistista rekistereihin kerralla. Vektoriarkkitehtuureissa oletuksena on ettei käskyjen välillä ole paljon riippuvuuksia ja liukuhihnan hasardeja tarkistetaan vain käskyjen välillä. Johtuen rinnakkaisesta toteutuksesta silmukkarakenteiden kontrollihasardeja ei esiinny.
Esimerkkinä SIMD-toteutuksesta ovat x86-perheen SSE-käskyt ja vektori-arkkitehtuureista Cray-supertietokoneet 1970-luvulta alkaen.
MISD¶
MISD (Multiple instruction streams, single data stream) malli on teoreettinen. MISD-prosessori toteuttaisi yhtaikaa useita käskyjä samalla data-alkiolle. Tällaisia sovelluksiahan toki löytyy, mutta miten idea heijastuu suoritinarkkitehtuuriin? Tästä ei ole olemassaolevia toteutuksia nykyään.. kvanttitietokoneet?
MIMD¶
MIMD (Multiple instruction streams, multiple data streams) tarkoittaa toteutusta, jossa usea ydin suorittaa operaatioita omassa (virtuaali)muistissaan. Data on peräisin samasta jaetusta fyysisestä muistista, joten ohjelman suorituksen ja muistioperaatioiden synkronointia ytimien kesken tarvitaan.
MIMD-toteutus itseasiassa mahdollistaa erillisten ohjelmien ajamisen eri ytimissä, esimerkiksi eri prosessien tai säikeiden (siellä Käyttöjärjestelmät-kurssissa sitten..) ajamisen omissa ytimissään. Mutta, yleensä yhtä ohjelmaa ajetaan kaikissa ytimissä yhtäaikaisesti.
Ohjelma jaetaan ehdollisilla lauseilla (jotka voivat olla lisäyksiä johonkin tunnettuun ohjelmointikieleen) ytimien kesken niin, että eri koodilohkoja ajavat eri ytimet. Jokaisessa ytimessä saattaa olla siis oma kopio ohjelman koodista ja datasta sen omassa välimuistissa.
Esimerkki MIMD-suorittimesta on Intel Core i7 vuodelta 2008.
GPU¶
Erilliset grafiikkaprosessorit (engl. Graphics Processing Unit, GPU) ovat yleistyneet. Yhdessä GPU:ssa saattaa olla satoja liukulukulaskentaan omistettuja yksikköjä, joita käytetään nopean grafiikan tuottamiseen. GPU:iden ohjelmointi on nykyään myös tullut osaksi mainstream-ohjelmointia ja niitä voidaan valjastaa laskentaan muissakin tarkoituksissa, esimerkiksi massadata-analyysissä.
GPU:t eroavat yleisestä CPU:sta seuraavasti:
- GPU:t ovat laitteistokiihdyttimiä, joiden tarkoitus on nopeuttaa haluttuja operaatiota, joten niissä ei tarvitse olla samoja ominaisuuksia kuin mitä yleinen CPU vaatisi.
- GPU:ssa on jopa enemmän rekistereitä kuin vektoriprosessoreissa.
- GPU:ssa ei ole monitasoisia välimuisteja, mutta tehokkuutta saadaan, kun muistiosoituksen aikana suoritetaan muita käskyjä.
- GPU:n muistipiireissä tarvitaan isot väylänleveydet.
- Datan koko on yleensä satoja megatavuja, kun se CPU:ssa on kymmeniä / satoja kilotavuja.
Kuvassa alla yleinen NVIDIAn GPU-arkkitehtuuri:
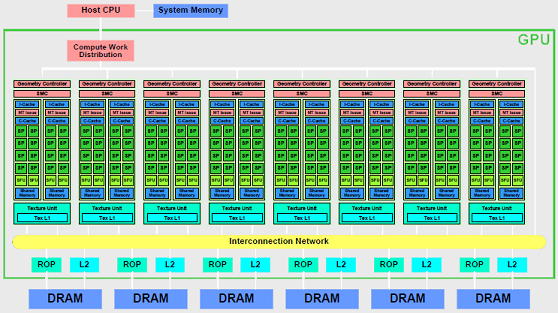
Tätä samaa ideaa kuin GPU:ssa on nykyään viety askel pidemmälle Tensori-prosessoreissa, joissa hardis on optimoitu tekoälyn menetelmiä varten, esimerkiksi koneoppimista.
Lopuksi¶
Tämä materiaali on vasta lyhyt yleiskatsaus modernien mikroprosessorien maailmaan.
Kuten materiaalista yleisesti käy ilmi, itse laskentaa suorittava ALU on vain hyvin pieni osanen koko tietokonejärjestelmää. Tietokonejärjestelmän toimintaa hallitsevat suorittimen rinnakaiset osajärjestelmät, liukuhihnat, niitä heijastavat käskykannat, kontrolliosien moninaiset ja -mutkaiset toteutukset, välimuistit eri tasoilla sekä väylien toteutukset muistipiireille ja I/O-laitteille.
Anna palautetta
Kommentteja materiaalista?