C-kielen muuttujatyypit¶
Osaamistavoitteet: Tämän materiaalin läpikäytyäsi tiedät miten C-kielessä esitellään ja alustetaan muuttujia sekä miten muuttujatyyppi vaikuttaa C-kielisen ohjelman käyttäytymiseen.
Okei, seuraavaksi päästäänkin jo C-kielen asioihin..
C-kielessä on ohjelmoijan iloksi määritelty valmiiksi joukko muuttujatyyppejä. Muuttujan tyyppi kertookin meille sen käyttötarkoituksen: merkki, kokonaisluku tai liukuluku. Kun muuttujatyyppi on standardoitu, voidaan luottaa, että se toimii kaikissa ympäristöissä samalla tavoin.
| Muuttujan tyyppi | Varattu sana | Tavuja | Standardoitu? |
| Merkki | char | 1 | Kyllä |
| Kokonaisluku (sana) | int | 2 / 4 | Ei, vaihtelee arkkitehtuurin mukaan |
| Lyhyt kokonaisluku | short int | 2 | Kyllä |
| Pitkä kokonaisluku | long int | 4 | Kyllä |
| Yksinkertaisen tarkkuuden liukuluku | float | 4 | Kyllä |
| Kaksinkertaisen tarkkuuden liukuluku | double | 8 | Kyllä |
Itseasiassa
short ja long ovat muuttujamääreitä, mutta niitä käyttäessä voidaan sana int jättää pois.C-kielessä kokonaisluvut luvut esitetään 2-komplementtilukuina, ellei ohjelmoija toisin määritä. Muuttujatyyppiä tarkennetaan määreellä
signed (etumerkillinen), joka varaa MSB:n etumerkkiä varten kuten aiemmin opittiin, ja unsigned (etumerkitön) jossa luvut ovat aina positiivisia. Tällöin tietenkin myös lukualue muuttuu vastaavasti. Esimerkkinä. 4-bittisen kokonaisluvun lukualue: unsigned ja signed.
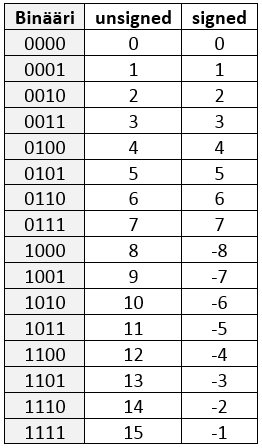
Kokonaisluku-muuttujatyypeille luvataan standardin mukaisesti minimi- ja maksimilukualueet, eli kääntäjästä ja tietokoneesta riippumatta muuttujan tulee toimia tällä mainitulla lukualueella.
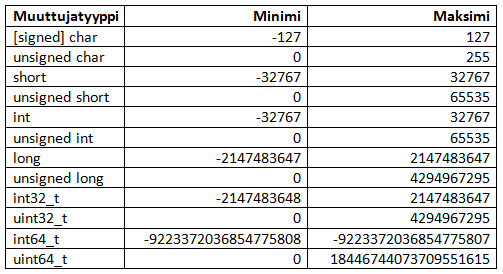
C-kielen standardissa on määritelty joukko johdettuja muuttujatyyppejä (otsikkotiedostossa
inttypes.h). Käytämme tästä eteenpäin näitä muuttujatyyppejä, jotta pysyy tiedossa muuttujan koko. Muistaen mikrokontrolleriparkaa ja sen vähäistä keskusmuistia!| Muuttujan tyyppi | Tavuja |
| int8_t / uint8_t | 1 |
| int16_t / uint16_t | 2 |
| int32_t / uint32_t | 4 |
| int64_t / uint64_t | 8 |
Näissä
intN_t-tyyppi tarkoittaa etumerkillistä kokonaislukua ja uintN_t-tyyppi etumerkitöntä kokonaislukua.Merkkimuuttuja
char on siitä kiinnostava tyyppi, että itseasiassa se on 8-bittinen luku, jonka arvo tulkitaan kääntäjässä kirjoitusmerkiksi ASCII-taulukon mukaisesti. Tosin ohjelmoija voi halutessaan unohtaa char-tyypin merkkiluonteen ja käyttää sitä 8-bittisenä kokonaislukumuuttujana. Tästä seuraa, että char-tyypin muuttujille toimivat laskutoimitukset kirjaimilla kuten muillekin kokonaislukumuuttujille, eli esimerkiksi 'a' + 1 = 'b' tai 'a' + 'c' = 196. Hassua. C-kielessä on myös rekisteri-, osoitin-, globaaleja ja staattisia muuttujia, mutta niistä lisää myöhemmin.
Muuttujien alustaminen¶
Muuttujien alustus tapahtuu esittelyn yhteydessä antamalla muuttujalle arvo.
int16_t kokonaisluku = -123;
uint16_t etumerkiton_kokonaisluku = 3333U;
uint32_t pitka_kokonaisluku = 0x12345678;
float liukuluku = 1.234;
float pienempi_liukuluku = 1.2e-10;
Jos ohjelmoija yrittää alustaa muuttujan sen lukualueen ulkopuolelta liian isolla luvulla, niin yleensä kääntäjä varoittaa virheestä.
int8_t a = 1234;
..warning: overflow in implicit constant conversion.
Mutta mutta! Kääntäjä vain varoittaa virheestä. Käännös jatkuu varoituksesta huolimatta, joten tällaiset ajatusvirheet voivat päätyä käännettyyn ohjelmaan (jos ohjelmoija esimerkiksi hakee kupin kahvia käännöksen aikana ja huomioi kääntäjän outputista vain onnistuneen käännöksen..).
Nythän muistista oli muuttujalle varattu tyypin mukainen määrä bittejä, ja jos sinne kirjoitetaankin enemmän tavaraa, on seurauksena muistin ylivuoto. Eli yritetään kirjoittaa muistiin muuttujalle varatun muistipaikan yli!! Mitä kääntäjässä sitten tapahtuu - miksi tämä on vain varoitus?
No, C-kielen kääntäjät surutta leikkaavat ylimääräiset eniten merkitsevät bitit numerosta pois giljotiinin omaisesti. Ylläolevassa esimerkissä käy seuraavasti: 1234 on binäärilukuna
10011010010. Nyt kääntäjä leikkaa pois ylimmät kolme bittiä 100, jolloin muuttujaan a sijoittuu 8-bittinen arvo 11010010. Tämä arvo taas desimaalilukuna taas on -46. Kun näin vahingossa pieleen alustettua muuttujaa int8_t a = -46 käytetään sitten ohjelmassa, saattaa operaation tulos olla varsin mielenkiintoinen.Merkkimuuttujien alustuksessa käytetään kirjoitusmerkin erottimena '-merkkiä (heittomerkki). Muistiin tallentuu sitten kirjoitusmerkkiä vastaava ASCII-taulukon numeroarvo.
char c = 'a'; // Tässä c:n arvoksi tulee a:ta vastaava ASCII-taulukon numeroarvo
char c = 97; // ASCII-taulukossa a:ta sattuu vastaamaan luku 97
Nyt, jos kasvatetaan muuttujan arvoa yhdellä..
c += 1;
.. sen arvoksi tulee 98, joka on ASCII-kirjoitusmerkkinä 'b'
Ja vielä, C-kieli tarjoaa määreen
const kertomaan, ettei muuttujan arvoa voi muuttaa. Ts. voimme tallettaa muistipaikkaan vakion. const uint8_t vakio = 12;
Taulukkomuuttujat¶
C-kielessä taulukkomuuttujat esitellään hakasulkujen avulla (kuten monessa muussakin ohjelmointikielessä), joiden sisällä on taulukon koko. Voimme esittää taulukkoja kaikille perusmuuttujatyypeille (ja muillekin muuttujatyypeille joista lisää tuonnempana). Tottakai myös moniulotteiset taulukot onnistuvat C-kielessä.
Syntaksi on seuraava:
uint8_t taulukko[5];
uint8_t taulukko[5] = { 1, -3, 5, -7, 9 }; // Alustetaan samalla
uint8_t taulukko[] = { 1, -3, 5, -7, 9 }; // Kääntäjä laskee taulukon koon itse!
uint8_t taulukko[3][3];
uint8_t taulukko [3][3] = { { 1, 2, 3 }, // Alustetaan
{ 4, 5, 6 },
{ 7, 8, 9 } };
uint8_t taulukko [][3] = { { 1, 2, 3 }, // Kääntäjä osaa joskus päätellä taulukon koon!
{ 4, 5, 6 },
{ 7, 8, 9 } };
Merkkijonot¶
Koska C-kielessä ei ole erillistä merkkijono-muuttujatyyppiä, niin merkkijonot ovat taulukkoja. Niiden alustuksessa on kuitenkin pientä eleganttia erikoisuutta. Monet standardikirjaston funktiot olettavat merkkijonon päättyvän numeroon 0, eli literaaliin '\0'. Huomataan, että numeroarvo 0 on ihan eri asia (kääntäjän mielestä, joten ei auta väittää vastaan) kuin ASCII-taulukon merkki '0', jonka numeroarvo on 48.
char viesti[] = "Terve"; Tämä alustus lisää merkkijonon loppuun automaattisesti nollan, ja kaikki ok. Muistissa viestimme perään on ilmestynyt arvo 0, eli merkkijonon koko onkin 5+1. Muutoin, meidän täytyy itse lisätä merkkijonon perään 0.
char viesti[] = {'T', 'e', 'r', 'v', 'e', '\0'}; // Tässä kääntäjä osaa laskea taulukon koon!
char viesti[6] = {'T', 'e', 'r', 'v', 'e', '\0'};
Jos alustamme merkkijonon / taulukon liian lyhyenä, kääntäjä täyttää sen automaattisesti nollilla. Allaolevat alustukset ovat ekvivalentteja.
char viesti[5] = "T";
char viesti[5] = {'T'};
char viesti[5] = {'T', 0, 0, 0, 0 };
Indeksit¶
Muutoin taulukkojen käsittely on tuttua, niissä liikutaan indeksien avulla kuten muissakin ohjelmointikielissä. Tosin, indeksin ensimmäinen arvo on
0 ja viimeinen sallittu indeksi on taulukon koko-1. Esimerkki indeksin käytöstä.
uint8_t i=0, jono[] = { 1, 2, 3, 4, 5};
for (i=0; i < 5; i++) {
printf("%d\n",jono[i]);
}
Taulukoissa voidaan liikkua muillakin tavoin, josta lisää osoittimien luentokappaleessa. Laiteläheisyys tarjoaa monenlaista kivaa muistinkäsittelyyn.
(Joissain tapauksissa taitava (tai myös vähemmän taitava) ohjelmoija voi onnistua menemään indeksillä taulukon ulkopuolelle ilman että kääntäjä sitä huomaisi, joten ollaanpa varovaisia sen indeksin tyypin kanssa!!)
Muuttujatyyppien muunnokset¶
C-kielessä voidaan muuttujien tyyppiä muuttaa tiettyjen sääntöjen mukaan. Standardi kertoo asiat tarkasti, mutta meille riittää am. yleissäännöt.
- Muunnokset, joissa saatetaan menettää tietoa, aiheuttavat kääntäjässä varoituksen. Esimerkiksi suuremman arvon muutaminen pienempään tyyppiin, josta yllä keskustelimme. Näissä kääntäjän giljotiini pudottaa ylimpiä bittejä armotta.
- Yhteen- ja kertolaskussa voi tulla ylivuoto, joten giljotiini leikkaa taas ylimmät bitit pois.
- signed tyyppien keskinäisessä muunnoksessa (esim. short -> long) tapahtuu sign extension, eli merkkibitti kopioidaan ylimpiin bitteihin
- Esimerkki.
int8_t -> int16_t: 11001010 -> 1111111111001010 - signed-tyypit konvertoidaan unsigned-tyypeiksi kääntäjässä
- Liukulukujen muunnoksessa kokonaisluvuksi desimaaliosa pudotetaan pois. Tässä ei siis pyöristetä!
- Muunnoshierarkia: double <- float <- long int <- int <- char
- unsigned-määre sotkee kuviota, koska kokonaislukutyyppien koot (int) riippuvat arkkitehtuurista. No, ei mennä syvemmälle tässä asiassa..
- char-tyyppi on taas hieman erikoinen. Koska ASCII-merkkejä on 127 kpl, ne voidaan osoittaa 7:llä bitillä. Nyt kun char-ajatellaan 8-bittisenä lukuna, jää meille MSB merkkibitiksi. Tässä on kääntäjissä vaihtelua, eli tulkitaanko char-tyyppi 2-komplementin mukaan negatiiviseksi luvuksi vai 8-bittiseksi positiiviseksi luvuksi.. tämän vuoksi jos haluaa olla ihan varma, voi käyttää numeraalisen char:n kanssa määreitä signed tai unsigned.
- Aritmeettisissa operaatiossa perussääntö on että operandeista "alempi" tyyppi muunnetaan "ylemmäksi" tyypiksi.
Tyyppimuunnoksen pakottaminen¶
C-kielessä on tyyppimuunnosoperaattori (engl. cast), jolla muunnos voidaan pakottaa missä tahansa kohtaa koodia. Operaattori on muotoa
(tyyppinimi) lauseke. Operaattorilla voidaan rikkoa ym. hierarkia tarvittaessa. Esimerkiksi.
uint16_t x = 2;
double y = sqrt((double) x); // tässä x:n arvo pakotetaan double:ksi, ennen neliöjuuren laskemista
Lopuksi¶
Taulukkojen kanssa tulemme vielä pelaamaan osoitin-muuttujien yhteydessä. Muuttujamuunnoksista ja alustuksissa on hyvä ymmärtää kääntäjän giljotiini, niin säästytään monelta kummalliselta bugilta.
Anna palautetta
Kommentteja materiaalista?