Bitit ja lukujärjestelmät¶
Osaamistavoitteet: Tämän materiaalin läpikäytyäsi tiedät miten tietoa esitetään tietokoneessa binäärilukuina ja osaat tehdä muunnoksia tietokonetekniikassa käytettyjen lukujärjestelmien välillä.
Aiemmilla ohjelmoinnin kursseilla opimme mitkä ovat tietokoneen (ja eri ohjelmointikielten) tuntemat lukujärjestelmät: binääri-, kymmen- ja heksadesimaaliluvut. Näistä kymmenjärjestelmä on mukana vain meidän ihmisten, ts. ohjelmoijien ja käyttäjien, takia. Tietokone vaatimattomana laskimena ei tarvitse kuin binääriluvut ja laiteläheisten ohjelmoijien tulee tietää miten tietokone ymmärtää binääriluvut ja niiden bitit.
Bitit tietokoneen muistissa¶
Bitti on tietoalkion (=informaation) pienin käsiteltävissä oleva osa. Bitillä on kaksi toisensa poissulkevaa loogista tilaa, 0 ja 1. Looginen tila tässä tarkoittaa sitä, että on suorittimen, laiteohjelmiston/käyttöjärjestelmän ja ohjelmoijan päätettävissä mitä bitin tilat tarkoittavat.
Yksittäinen bitti siis esittää aika vähän informaatiota, mutta kun bitit asetetaan jonoon binääriluvuksi, voidaankin esittää aika monipuolisesti informaatiota. Edellisellä luennoilla opimme, että suorittimen arkkitehtuuri määrittelee käsiteltävän tietoalkoon koon (sanan pituus) n-bittisenä binäärilukuna.
Esimerkiksi sulautetussa järjestelmässä oheislaitteen kanssa pelatessa, looginen tila 0 voisi tarkoittaa että oheislaite on valmis vastaanottamaan komentoja ja 1 että laite on busy, eli vielä suorittamassa edellistä komentoa.
Muistipaikka¶
Yleisesti on siis suoraviivaista ja sikäli hyödyllistä, että tietokoneen muisti vastaavasti organisoidaan muistipaikkoihin, joiden koko on sanan pituus. Tällöin sanan pituudesta (dataväylä) ja muistin koosta (osoiteväylä) saadaan tarvittava muistiväylän leveys.
Esimerkinomaisesti alla pätkä arkkitehtuuriltaan 8-bittisen tietokoneen muistia. Nyt muistia on vain 16 muistipaikkaa, joten osoiteväylän leveys on 4-bittiä (2^4=16). (Näin pieni muisti voisi olla vaikka haihtumaton EEPROM-muisti sulautetussa laitteessa.)
| Muistiosoite | Sisältö | Tulkinta 10-järjestelmässä |
| 0000 | 00000011 | 3 |
| 0001 | 11111111 | -1 |
| 0010 | 10110111 | -73 |
| 0011 | 00110110 | 54 |
| .. | .. | .. |
| 1111 | 00110111 | 55 |
Ylläolevassa muistissa muistiosoitteessa 3 (0011) on tallessa arvo 54 (00110110). Tällainen tilanne voisi syntyä, kun olisimme ohjelmassa esitelleet 8-bittisen muuttujan, joka olisi alustettu arvoon 54. Kääntäjä ja käyttöjärjestelmä (menemättä yksityiskohtiin) päätyivät siihen, että kyseinen arvo talletetaan muistipaikkaan nro 3, josta se on ohjelman käytettävissä sen ajonaikana.
Esimerkki. Muistipaikan osoitteen voisi helposti ajatella katuosoitteena. Jokaisella kadunvarren talolla on järjestysnumero, joka yksilöllisesti osoittaa talon, ja jokaiseen taloon voidaan tallettaa yksi tieto. Ylläolevassa muistiesimerkissä talossa nro 3 olisi tallessa siis luku 54, josta se voidaan käydä kysymässä tai kertomassa tilalle uusi luku. (Palaamme tähän taloesimerkkiin myöhemmässä materiaalissa..)
Nimitysuutisia¶
Nyt, erikokoisille binääriluvuille on tietotekniikassa yleisesti määritelty nimityksiä:
- 8-bittisestä binääriluvusta käytetään nimitystä tavu (engl. byte)
- 16/32-bittisestä luvuista taas nimitystä sana (engl. word). Tiedämme että sanan pituus vaihtelee arkkitehtuurista toiseen ja myöskään C-kielen standardi ei sanan pituutta määrittele.
- 32/64-bittisestä luvusta käytetään nimitystä pitkä kokonaisluku (engl. long word)
Varsinkin englanninkieliset nimet on syytä tuntea osana tieto/sähkötekniikan insinöörin ammattitaitoa ja niitä käytetäänkin digitaali- ja tietotekniikassa yleisesti.
Binääriluvun tulkinta¶
Ikävä kyllä se vielä riitä, että osaamme yhdistää ohjelmamme muuttujan nimen tietokoneen muistipaikkaan ja sen arvoon. Lisäksi tietokoneen pitää osata tulkita muistissa oleva binääriluku.
Bittijärjestys¶
Binääriluvun esittämisessä suorittimen laskentayksikölle on vielä pari mutkaa matkassa, sillä pitää myös sopia miten suoritin tulkitsee muistipaikan bittijonon.
Kymmenjärjestelmässä olemme sopineet, että merkittävin numero on vasemmanpuoleisin numero ja siitä oikealle päin laskevassa järjestyksessä. Esimerkiksi, luvussa 217 isoin painoarvo on luvulla 2, joka kuvaa satasia. Luku on siis
2 x 100 + 1 x 10 + 7 x 1 = 217. Mutta, mikään muu kuin keskinäinen sopimus ei estä meitä lukemasta lukua myös toisesta suunnasta 7 x 100 + 1 x 10 + 2 x 1 = 712.Sama koskee tietysti binäärilukuja. Nyt esimerkiksi luku 1011 voidaan lukea samoin vasemmalta oikealle tai toisinpäin. Suunnasta riippuen luvun arvo voi muuttua, joka sotkee asiat jos sopimukseen ei ole päästy.
8 + 0 + 2 + 1=118 + 4 + 0 + 1=13

Lukusuunnan määritelyssä puhutaan bittijärjestyksestä, jonka määräämiseksi tarvitaan kaksi määritelmää:
- Eniten merkitsevä bitti (engl. Most Significant Bit, MSB) tarkoittaa merkittävintä numeroa luvussa, eli sitä bittiä jonka kakkosen potenssi on suurin.
- Vähiten merkitsevä bitti (engl. Least Significant Bit, LSB), on se bitti jolla on pienin kakkosen potenssi.
- Nyt lukusuunta on nyt siis alkaen MSB:stä kohti LSB:tä, niin että kakkosen potenssi aina pienenee yhdellä.
No, bittijärjestyksen ovat meidän puolestamme suorittimen arkkitehtuurin suunnittelijat aikoinaan päättäneet. Koska suunta voi vielä nykyäänkin vaihdella, se on kerrottu suorittimen käsikirjoissa. Yleensä ohjelmoijan ei tarvitse kiinnittää suorittimen osalta asiaan huomiota, koska ohjelmointikielissä voidaan määritellä bittijärjestys halutuksi ja kääntäjät sitten muokkaavat koodin suorittimelle sopivaksi. Mutta, sulautetuissa järjestelmissä oheislaitteiden kanssa pelaillessa bittijärjestykseen joutuu kiinnittämään huomiota.
Tavujärjestys¶
Sekään ei vielä riitä, että tiedämme missä järjestyksessä binääriluvun bittijono pitää tulkita. Erityisesti sulautetuissa järjestelmissä pääsemme usein käsittelemään lukuja, jotka ovat sanan pituutta suurempia!
Esimerkiksi 8-bittisessä sulautetun järjestelmän suoritinarkkitehtuurissa voimme yleisesti hyvinkin käsitellä 16- tai 32-bittisiä lukuja.
Ratkaisu on pätkäistä luku sanan pituuden sallimiin pätkiin, jolloin 8-bittisessä arkkitehtuurissa 16-bittisestä luvusta saadaan kaksi 8-bittistä lukua ja 32-bittisestä neljä 8-bittistä lukua. Muistiin nämä luvut sijoitetaan sitten peräkkäisiin muistipaikkoihin. Esimerkkinä, 8-bittisissä Arduinoissa C-kielen kääntäjät yleisesti sallivat käyttää isompiakin lukuja, ja kääntäjä sitten muokkaa koodin mikrokontrollerille sopivaksi (tällöin konekielessä isompien lukujen käsittelyssä joudutaan operaatiot tekemään vaiheittain.)
Palataan hetkeksi yllä esitettyyn muistiin:
| Muistiosoite | Muistipaikan sisältö | Tulkinta 10-järjestelmässä |
| 0000 | 00000011 | 3 |
| 0001 | 11111111 | -1 |
| 0010 | 10110111 | -73 |
| 0011 | 00110110 | 54 |
Nyt tässä muistidumpissa (raakakopio muistin sisällöstä) on neljä tavua, jotka voivat tarkoittaa neljää 8-bittistä lukua, kahta 16-bittistä lukua (muistipaikat 0-1 ja 2-3) ja yhtä 32-bittistä lukua (muistipaikat 0-3). Ok, mutta.. vastaavasti herää kysymys että missä järjestyksessä tavut luetaan? Onko 32-bittisen luvun ensimmäinen tavu muistipaikassa 0 vai 3?
No, arvatenkin myös tavujärjestys (eli tavujen lukusuunta) on vastaavasti suoritinarkkitehtuurin suunnittelun yhteydessä päätetty asia. Tässäkin käytetään kahta yleistä termiä:
- Big endian: lukusuunta vasemmalta oikealle. Esimerkkimuistissa siis suunta on muistipaikasta 0 muistipaikkaan 3.
- Little endian: lukusuunta oikealta vasemmalle. Esimerkkimuistissa siis suunta on muistipaikasta 3 muistipaikkaan 0.
Esimerkki. PC-työasemien nykyinen x86-64 -prosessoriarkkitehtuuri on little endian, mutta bittijärjestys taas eniten merkitsevä ensin, eli bitit luetaan vasemmalta oikealle MSB->LSB.
Sopimus¶
Jotta kurssilla ymmärrämme toisiamme, niin määritellään tässä yhteiset lukusuunnat:
- eniten merkitsevä tavu on vasemmanpuoleisin tavu (big endian), eli muistissa pienin muistipaikka.
- eniten merkitsevä bitti (MSB) on luvun vasemmanpuoleisin bitti.
- Aina binäärilukua tulkitessa liikutaan siis vasemmalta oikealle suurimmasta bitin painoarvosta pienempään.
Esimerkki. Tulkinta 16-bittiselle luvulle. MSB -> LSB 1100101000101100 = -13780
Pyrkimys säästeliäisyyteen¶
Jees, hieno homma. Mutta miksi nämä tavut ja sanat kiinnostavat meitä.. eikö riittäisi, että käytetään aina vain 64-bittistä arkkitehtuuria sovelluksissa, niin ei lopu lukualue kesken ja osaahan ne kääntäjätkin hanskata isot luvut?
Työasemalla ohjelmoidessahan asia ei juuri liikuta, koska resursseja kuten muistia ja prosessoritehoa on riittämiin. Kun taas sulautetuissa järjestelmissä mikrokontrollereissa on yleensä pieni määrä RAM-muistia, tyyliin muutama kilotavu, joka pitää jakaa sovelluksen lisäksi firmiksen (ja käyttöjärjestelmän kesken). Näin ollen muistin käyttöä joudutaankin sulautetuissa sovelluksissa miettimään tarkemmin.
Oleellinen asia tässä on esittää ohjelmassa juuri sopivan kokoisia muuttujia. Nyt, jos tarvitsemamme lukualue mahtuu 8-bittiseen muuttujaan, niin miksi esitellä ohjelmassa sitä varten 64-bittinen muuttuja? Jälkimmäisessä tapauksessa muistia kuluu kahdeksan tavua, kun taas sovelluksessa oikeastaan pärjättäisiin yhdellä tavulla. Työasemaohjelmointiin tottuneelle muutaman tavun säästö voi tuntua olemattomalta saavutukselta, mutta tarkastellaan asiaa sulautettujen maailmassa esimerkin kautta.
Esimerkki. ATmelin ATtiny-sarjan mikrokontrollereissa RAM-muistia on jopa alle yhden kilotavun (1024 tavua). Lasketaanpa hieman. Nyt jos käytetään 32-bittisiä muuttujia, niitä mahtuu muistiin maksimissaan (1024 tavua / 4 tavua = 256). Jos taas käytetään 16-bittisiä muuttujia, niitä mahtuisi muistiin (1024 / 2 tavua = 512). Mutta eikös satakin muuttujaa ole jo aika paljon yhteen ohjelmaan? No, riippuu sovelluksesta. Esimerkiksi jos kerätään nopeassa tahdissa (useita kertoja sekunnissa) vaikkapa kiihtyvyysanturidataa kolmelta akselilta (X, Y, Z) taulukkoon, ei muutaman kilotavun muisti enää riittäne..
Tähän asiaan palaamme jo heti seuraavassa materiaalissa, kun esittelemme C-kielen muuttujatyypit.
Negatiiviset binääriluvut¶
Aiemmin olemme käyttäneet binäärilukuja positiivisten lukujen esittämiseen, mutta hei.. mites negatiiviset binääriluvut?
No, ei hätää, useita ratkaisuja on tietotekniikan esitetty, jotka perustuvat sopimukseen, että varataan binääriluvusta joku bitti merkkibitiksi esittämään etumerkkiä (+ / -). Yleisesti tämä bitti on MSB, jonka arvo 0 tarkoittaa positiivista lukua ja 1 negatiivistä lukua. Kun varaamme yhden bitin etumerkin käyttöön, jää meillä itse lukualueeseen n-1 -bittiä.
Esimerkiksi 8-bittisen luvun lukualue tippuu 7:n bittiin, eli positiivinen lukualue olisi enää
0..127. Tosin nyt saamme lukualueeseen tilalle etumerkin avulla lisäksi negatiiviset lukualueen -128..-1. Ilman etumerkkiä lukualue olisi 0-255, joten lukualue ikäänkuin siirtyy negatiiviseen suuntaan MSB:n arvon verran.Suora esitystapa¶
Suorassa esitystavassa (engl. signed magnitude) varataan biteistä eniten merkitsevä (MSB) merkkibitiksi. Tästä seuraa, että nyt esimerkiksi 0010 olisi 2 ja 1010 olisi -2.
Huomataan, että tällöin nollalla on kaksi esitystä, eli 0000 (ikäänkuin +0) ja 1000 (ikäänkuin -0). Tämä on huono juttu, koska ohjelmassa joudutaan huomioimaan molemmat esitykset nollalle.
Yhden komplementti¶
Nyt negatiivinen luku saadaan ottamalla positiivisesta looginen negaatio. Esimerkiksi, kun luku 3 on 0011 binäärilukuna, niin -3 olisi 1100.
Tässäkin esitystavassa on nollalle kaksi esitystä, 0000 ja 1111, joten ei paras eikä hyvä meille.
Kahden komplementti¶
Kahden komplementti-esitystapa on yleisesti digitaalitekniikassa / tietotekniikassa käytetty, joten uhrataan sille hieman enemmän aikaa ja kurssimateriaalia.
Sovitaan taas, että eniten merkitsevä bitti (MSB) on merkkibitti eli 0 positiivinen ja 1 negatiivinen.
- Positiiviset luvut: Ei mitään erikoista
- Negatiiviset luvut: Nyt kokonaisluvun esittämiseen on oma menetelmänsä
- Positiivisesta binääriluvusta otetaan negaatio (eli nollat ykkösiksi ja päinvastoin).
- Lisätään negaatioon 1.
Esimerkkejä 4-bittisillä luvuilla.
Luku 1 0001 Luku 2 0010
Negaatio 1110 Negaatio 1101
Lisäys +1 Lisäys +1
---- ----
1111 = -1 1110 = -2
Muunnos takaisin negatiivisesta positiiviseksi mennään ihan samoin (kätevää!):
Luku -1 1111 Luku -2 1110
Negaatio 0000 Negaatio 0001
Lisäys +1 Lisäys +1
---- ----
0001 = 1 0010 = 2
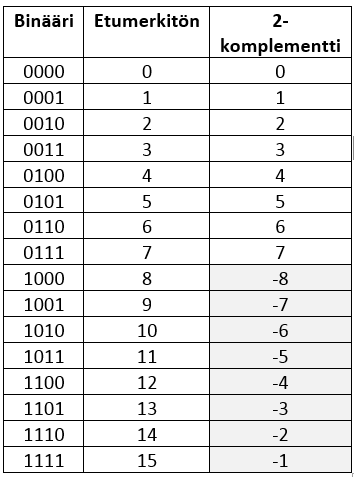
Esimerkki. Kuvassa 4-bittiset luvut ilman etumerkkiä ja 2-komplementtiesityksenä.
Kätevyyttä¶
2-komplementtiesitys on myös siitä kätevä, että 2-komplementtilukujen yhteenlasku toimii samoin oli operandi positiivinen tai negatiivinen. Tämä helpottaa merkittävästi digitaalitekniikassa esimerkiksi laskentaa suorittavien logiikkapiirien toteutusta.
Esimerkki. Laske 2-komplementtiluvuilla 2+3 = ? ja 2-3 = 2+(-3) = ?
Luku +2 0010 Luku +2 0010
Luku +3 0011 Luku -3 1101
+ ---- + ----
0101 = 5 1111 = -1
(Suorassa menetelmässä ja 1-komplementti-esityksessä tämä ei aina toimi, kokeile löytää esimerkki jossa yhteenlasku ei toimi!)
Niksi-Pirkasta päivää¶
Ja sitten terveisiä Niksi-Pirkka osastolta.. negatiivisen binääriluvun muunnos kymmenjärjestelmään voidaan tehdä ilman laskintakin yhteenlaskua hyödyntäen. Idea on, että ajatellaan:
- Eniten merkitsevän bitin arvo negatiivisena.
- Muiden bittien arvot pysyvät positiivisina
Kuvassa alla siis MSB-bitin arvo ajatellaan negatiivisena ja muiden positiivisena.
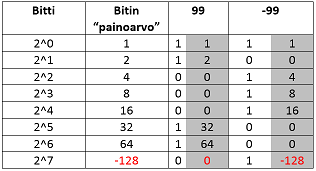
Nyt muunnos tapahtuu siten, että lasketaan yhteen bittien arvoa vastaavat kymmenjärjestelmän luvut.
Esimerkki. 8-bittiset luvut 99 ja -99. 99 on binäärilukuna 01100011 eli 64 + 32 + 2 + 1 = 99 -99 on binäärilukuna 10011101 eli -128 + 16 + 8 + 4 + 1 = -99
Muunna 6-bittinen 2-komplementtiluku 101011 kymmenjärjestelmään yhteenlasku-menetelmällä.
 Anna palautetta
Anna palautetta
Koitko tämän tehtävän hyödylliseksi oppimisen kannalta?
Kommentteja tehtävästä?
Heksadesimaaliluvut¶
Toinen tietokonetekniikassa usein käytetty kantalukujärjestelmä on 16. Tällöin puhutaan heksadesimaalinumeroista, jotka käsittävät numerot 0-9 ja 10-15, joita jälkimmäisiä merkitään kirjaimilla A-F.
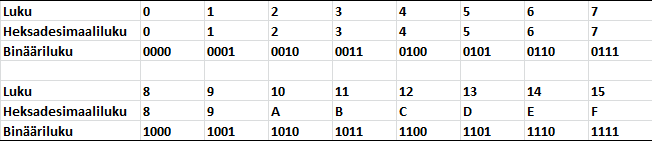
Huomataan, että jokainen heksadesimaalinumero voidaan esittää 4:llä bitillä (ns. nibble). Tämä onkin yksi erittäin hyvä syy miksi heksadesimaalilukuja tietotekniikassa ja ohjelmoinnissa käytetään. Nyt voidaan yksi tavu esittää kahdella heksadesimaalinumerolla (vs. hankalasti biteiksi tulkittava kymmenjärjestelmän kokonaisluku vs. silmille epämukava binääriluku).
Muunnos heksalukujen ja binäärilukujen välillä on helppo kun tiedämme, että jokaista heksanumeroa siis vastaa 4 bittiä. Tarvitsee vain muuttaa heksanumerot yksi kerrallaan 4-bittisiksi binääriluvuiksi.
Esimerkki. binääriluku 01011101 on heksana 5D ja kymmenjärjestelmässä 93.
5 D 0101 1101 0 + 64 + 0 + 16 + 8 + 4 + 0 + 1 = 93
Esimerkki. Muunna heksadesimaaliluku 173A4C binääriluvuksi?
1 7 3 A 4 C 0001 0111 0011 1010 0100 1100
Monissa ohjelmointikielissä heksaluvut esitetään käyttäen etuliitettä
0x. Esimerkiksi kaikki ao. luvut ovat valideja heksalukuja. 0x0 0x0123456789ABCDEF 0xA 0x1000 0x001 0xBEEF 0xC0DE 0xBA5EBA11
Lopuksi¶
.. joskus eri lukujärjestelmien kanssa laskeminen voi saada kummallisia käänteitä (http://www.xkcd.com/571)

Nooh, nythän meille on selvää mitä kolmannessa ruudussa tapahtuu! Ystävämme laskee lampaita 16-bittisillä 2-komplementtiluvuilla ja käy niin ikävästi, että unta odotellessa positiivinen lukualue ehtii loppua, jolloin merkkibitti vaihtuu ja mennäänkin negatiiviselle lukualueelle.
...
0111111111111111 = 32767 lammasta
+1 lammas
1000000000000000 = -32768 lammasta // etumerkki vaihtui kun MSB 0 -> 1
+1 lammas
1000000000000001 = -32767 lammasta
...
Anna palautetta
Kommentteja materiaalista?